



 本文详细解析了Java Class文件的结构及其组成部分,包括魔数、版本号、常量池、访问标志等内容,并解释了这些元素如何支持Java的特性和可移植性。
本文详细解析了Java Class文件的结构及其组成部分,包括魔数、版本号、常量池、访问标志等内容,并解释了这些元素如何支持Java的特性和可移植性。
前言:
java程序可移植的,是平台无关的。因为java源码文件(.java)被编译器(javac)编译转化为字节码文件(.class),而字节码文件的执行是依赖JVM的,所以只要在平台上安装了对应的虚拟机版本,那么这些字节码文件就可以被加载执行。几行文字就说明了java程序为啥平台无关的,可移植的。虚拟机加载字节码文件,那么字节码文件里面到底保存了什么内容呢?它的结构是什么样的呢?这也是这篇文章所要讲解的内容。读了这篇文字能获得那些内容呢?
1.Class文件结构
2.Class文件格式及各部分内容讲解
3.根据class文件格式内容,理解JAVA语言的特性
备注:
class文件结构是java语言的核心基础数据结构,所以理解和掌握这一部分内容是必须和非常重要的,但因为是数据结构的内容,所以会有些无聊。尽量通俗易懂。
- class文件结构
class文件是以8位字节为基础单位的二进制流。各个数据项严格按照顺序紧凑的
排列在class文件中,没有分隔符,没有空隙。如果出现8位字节以上的数据项,则会按照
高位在前的方式分割成若干各8位字节进行存储。
java虚拟机规范规定:class文件格式采用一种类似C语言结构体的伪结构存储,这种伪结构只有两种数据类型:无符号数、表。解析都是依赖这两种数据类型,所以 将清楚这两货是必要搞懂的。
1.无符号数是基本的数据类型,分别以u1\u2\u4\u8表表示1各字节、2个字节、4个字节、
8个字节。它可以用来描述数字、索引引用、数量值、或者按照UTF-8编码构成的
字符串值。
2.表是由无符号数或者和其他表作为数据项构成的复合型数据结构。就是跟c语言的结构
体很相似。而整个class文件就是一张表。
class表结构:
| 类型 | 名称 | 数量 |
|---|---|---|
| u4 | magic | 1 |
| u2 | minor_version | 1 |
| u2 | major_version | 1 |
| u2 | constant_pool_count | 1 |
| cp_info | constant_pool | constant_pool_count-1 |
| u2 | access_flags | 1 |
| u2 | this_class | 1 |
| u2 | super_class | 1 |
| u2 | interfaces_count | 1 |
| u2 | interfaces | interfaces_count |
| u2 | fields_count | 1 |
| field_info | fields | fields_count |
| u2 | methods_count | 1 |
| method_info | methods | methods_count |
| u2 | attributes_count | 1 |
| attribute_info | attributes | attributes_count |
备注:
class文件的结构不同于XML等描述语言,它没有分割符,所以无论是顺序和数量都严格限定的,不可修改的。
- class文件格式
魔数(magic,u4):占用4个字节,
用于进行身份识别,判断是否为虚拟机可接受文件格式。git\jpeg都在文件头存有魔数。
class的魔数是 :0xCAFEBABE(咖啡宝贝?这个取值的历史也很有意思,可自行查阅,
你还可以联想一下java的icon是不是一杯咖啡的图).
次版本号(minor_version,u2)、主板本号(major_version,u2):
第5,第6个字节标识次版本号。java的版本号是从45开始的。JDK1.1以后每个大版本在
主板本号上加1,高版本JDK可以向下兼容。但无法兼容后续的高版本,就算内容结构啥的
没有发生改变,也是无法兼容的。如果要验证,可以自行用不同的jdk编译的文件进行测试
。
常量池:
紧接着就是常量池的入口,特别要注意的是这里常量池会使用一个u2的constant_pool_count计数器,统计常量池容量。但它的计数是从1开始,不是0,所以constant_pool的容量是constant_pool_count-1。
那为啥不从0开始呢?因为规范制定时,这一0有特殊用途:表达“不引用任何一个常量池项目”。class文件中就只有常量池计数器是从1开始的,其他都是从0开始的。
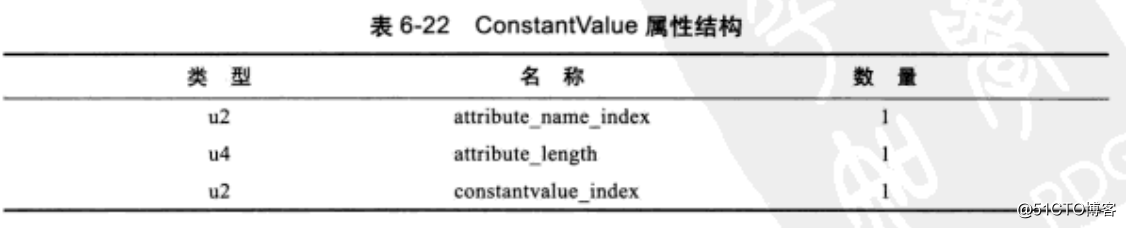
常量池存放两大类常量,字面量与符号引用。字面量接近java语言层面的常量,比如字符串、final定义的常量值等。而符号引用则是编译原理的概念。包括:类和接口全限定名、字段的名称和描述符、方法的名称和描述符。
常量池中的每一项都是一个表。一共有11个各不相同的表结构。这11个表有一个共同点,开头都是u1类型的标识位(tag)取值1-12,没有2标识的数据类型.下表为tag取值对应的数据类型。
| 类型 | 标识 | 描述 |
|---|---|---|
| CONSTANT_Utf8_info | 1 | UTF-8编码的字符串 |
| CONSTANT_Integer_info | 3 | 整型字面量 |
| CONSTANT_Float_info | 4 | 浮点型字面量 |
| CONSTANT_Long_info | 5 | 长整型字面量 |
| CONSTANT_Double_info | 6 | 双精度浮点型字面量 |
| CONSTANT_Class_info | 7 | 类或者接口的符号引用 |
| CONSTANT_String_info | 8 | 字符串类型字面量 |
| CONSTANT_Fieldref_info | 9 | 字段的符号引用 |
| CONSTANT_Methodref_info | 10 | 类中方法的符号引用 |
| CONSTANT_InterfaceMethodref_info | 11 | 接口中方法的符号引用 |
| CONSTANT_NameAndType_info | 12 | 字段或者方法的部分引用 |
之所以说常量池最复杂就是因为这11个常量类型都有自己的结构。而且很多class文件中的数据项都要引用常量池中的常量,所以这一部分也是非常重要的内容。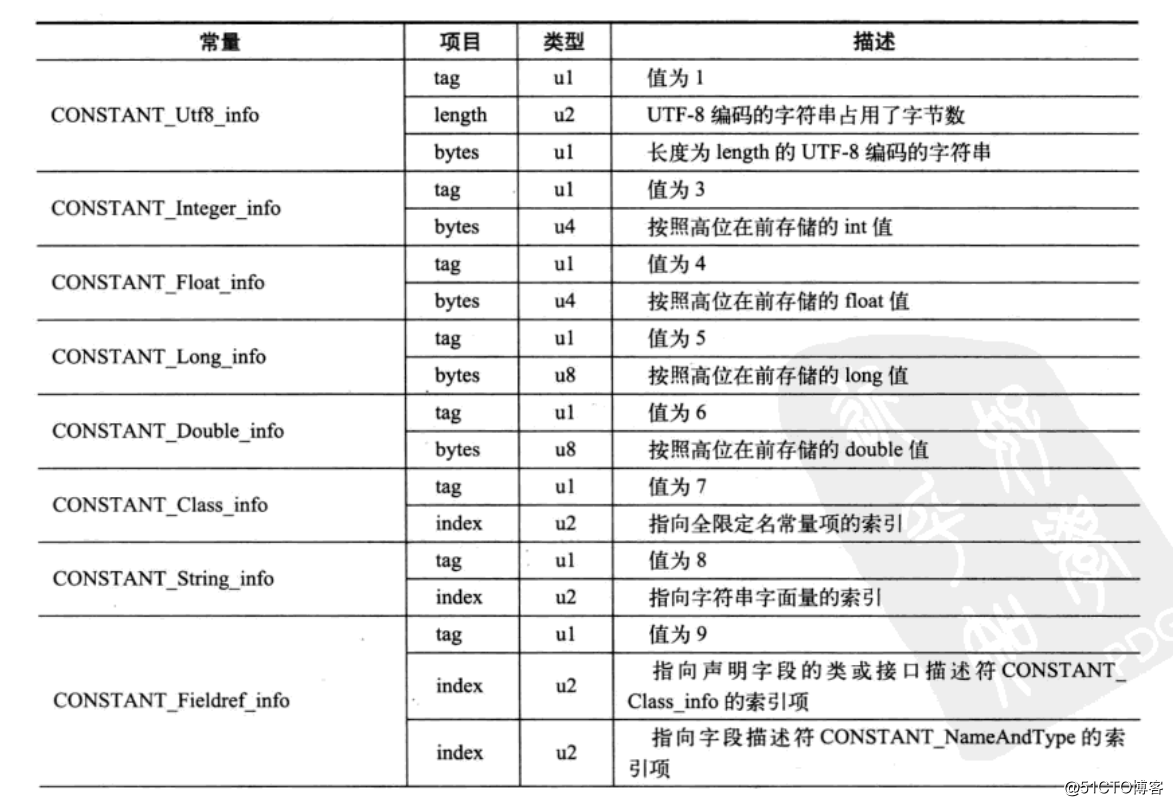
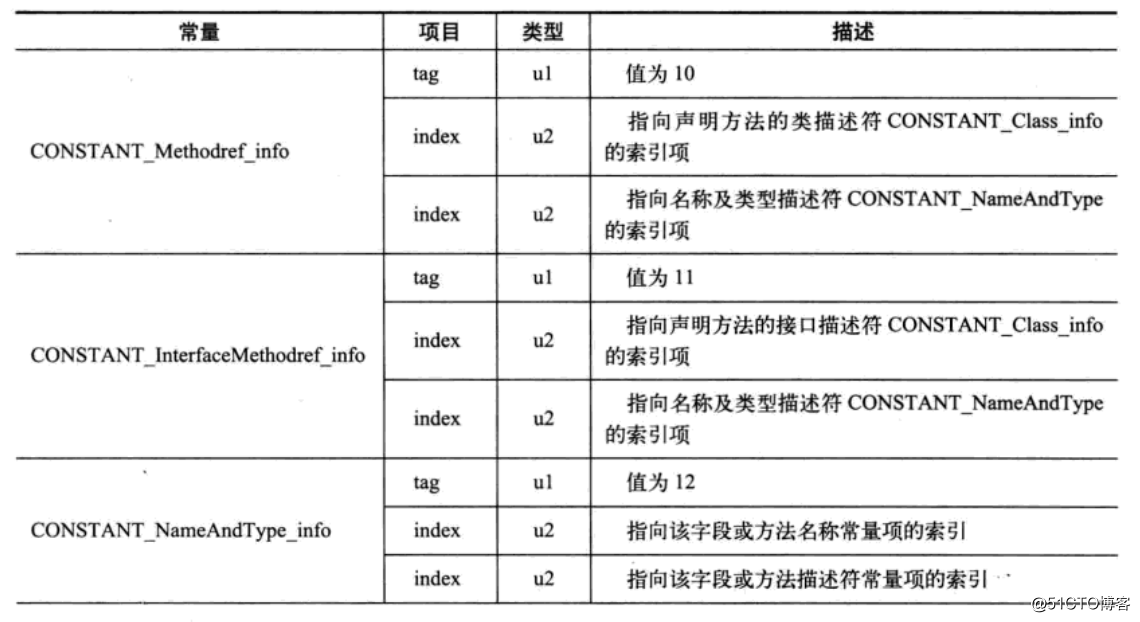
访问标识
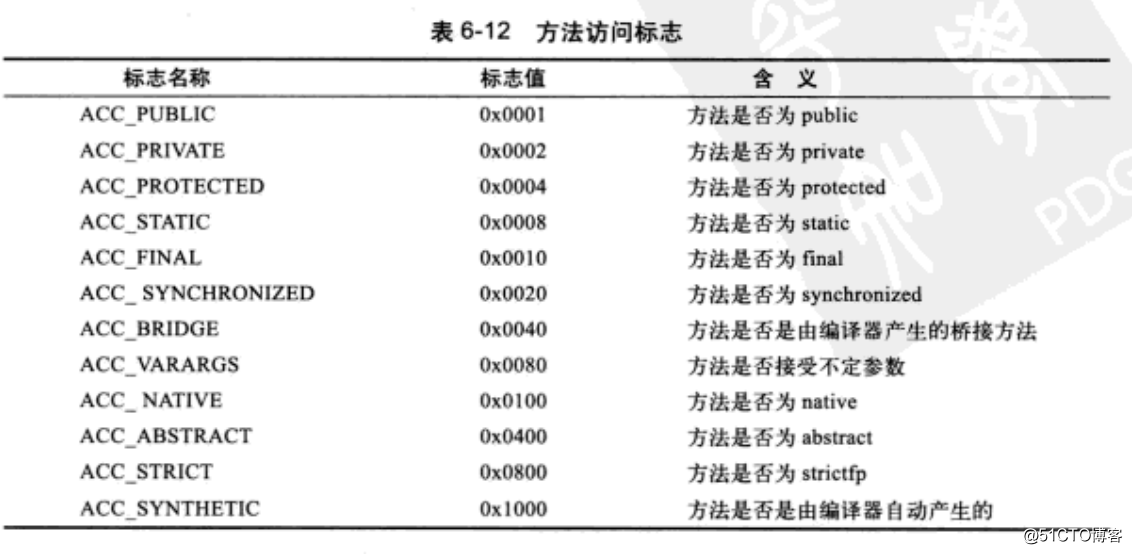
该标识用于识别一些类的信息,比如说:classs是类还是接口,是否public,是否是abstract,如果是类,是不是定义为final。
类索引、父类索引、接口索引集合
类索引(this_class)和父类索引(super_class)都是u2类型的数据,而接口索引集合是一组u2数据类型的集合。class文件中用这三项来描述该类的继承关系。这也是为什么java只能单继承,不能多继承,而可以多实现接口的原因。在class文件结构上就限定了类的单继承特性。
类索引和父类索引各自指向了一个Constant_Class_info的描述符号常量,通过Constant_class_info中的索引值可以找到一个Constant_Utf8_info的常量字符串,这个字符串就是类的全限定名字符串。查找过程如下图:
字段表集合
字段表是描述接口和类申明的变量。类变量和实例变量,但不包含在方法体中的局部变量。那么它可以描述那些信息呢?我们可以结合字段申明所用的修饰来分析,比如作用域、类变量还是实例变量、是否可变、并发可见性、可否序列化、字段数据类型、字段名称。下面是字段表结构:
字段访问标识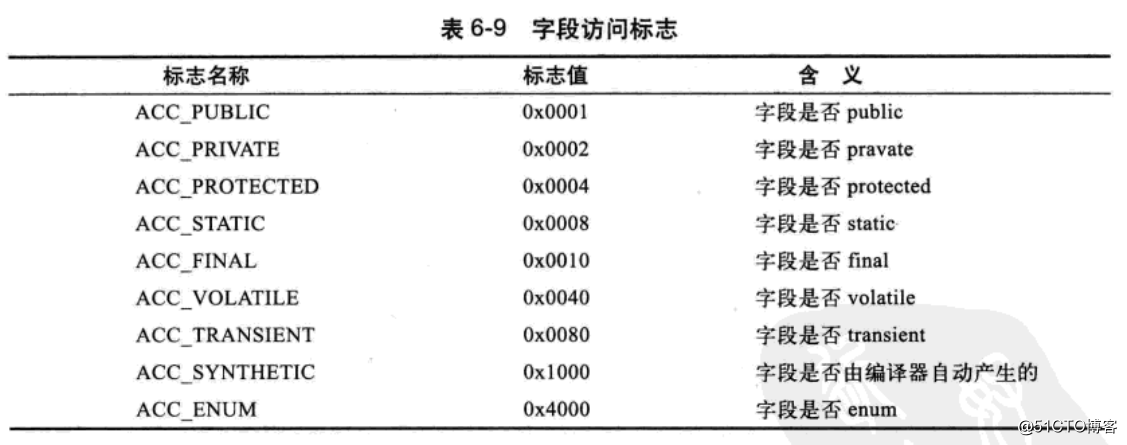
方法表集合
如果理解了字段表集集合的含义,那么理解方法表集合就十分的简单了,因为它们非常相似,只是在可选值上有所区别。
到这里我就产生类疑问,我方法体里面的代码呢?它保存到哪里去啦?
代码被编译称字节码指令,保存到方法属性表集合中的code属性里面了,而方法属性呢,则顾名思义是放在属性表集合中了,接下来就是讲属性表集合。
属性表集合
前面的class文件、字段表集合、方法表集合都有attribute表集合,用来描述某些场景的专有信息。
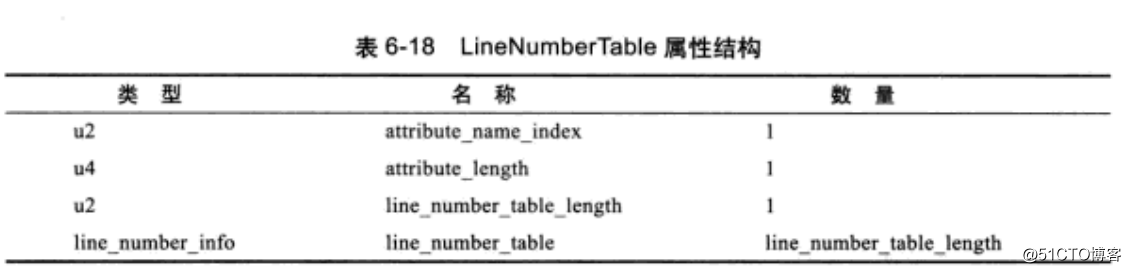
可以看到,code属性有本地变量表,LineNumberTable,我们前面方法里的代码就是放在Code属性中的。

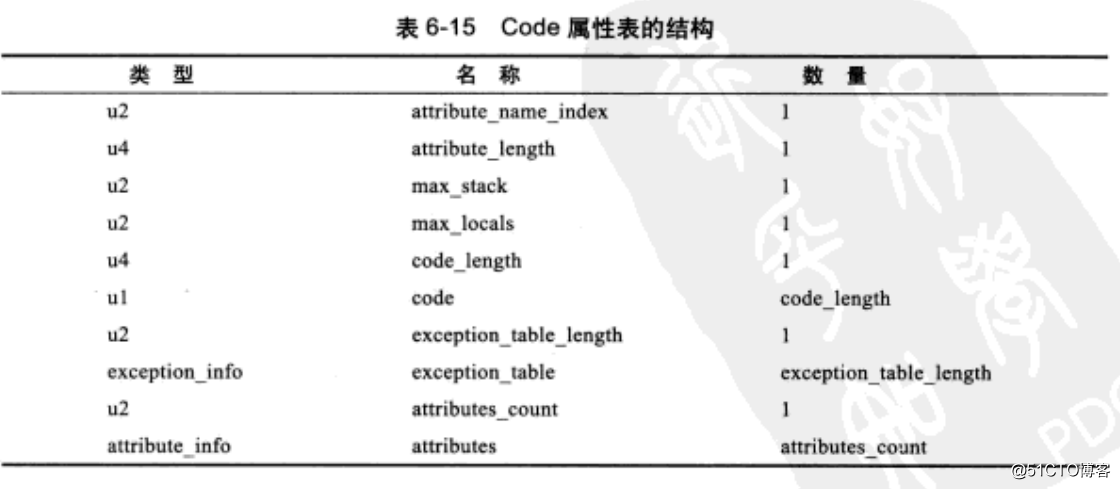
特别注意:code属性不是一定都会存在,比如抽象类,就没有方法表中的code属性,接口因为jdk8做了接口增强以后,可以在接口中实现方法体了,所以接口可能有,也可能没有。但jdk8以前的接口肯定是没有的。
异常属性表结构





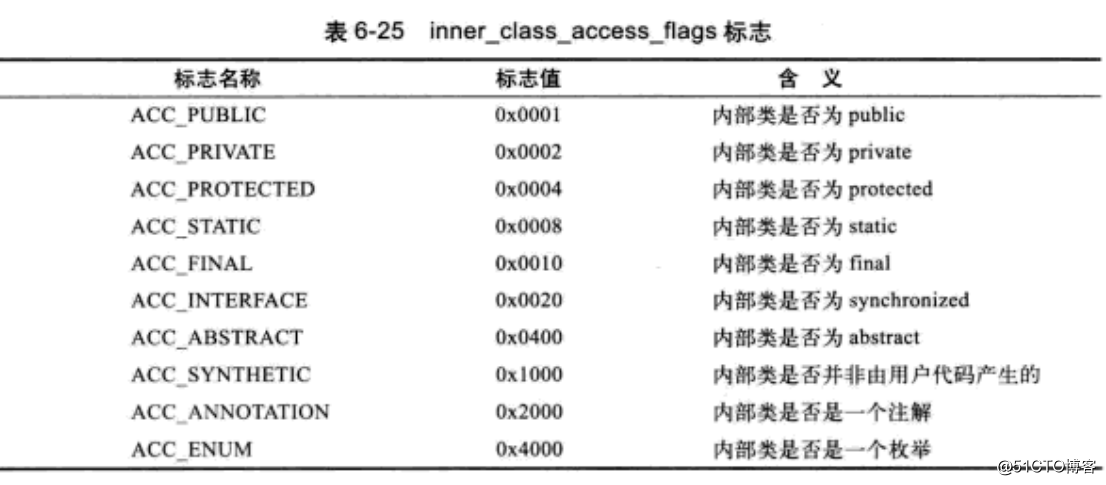

class文件是java虚拟机执行引擎的入口,那么通过上面的讲解,对class文件结构也有更深入的了解,对java语言的一些特性也有了在根本上理解的基础。class文件也是算的上java技术体系中的基础支柱之一。对于后面讲解虚拟机执行引擎具有重要的意义。
备注:
上面所写的内容版本应该是1.6的,所以现在都已经开始1.8、1.9的流行了,所以如果你看到的内容有所不同,这是正常的,因为java在发展,class文件结构也在不断发展,但是大的变化是没有的,而一些小变化也是在结构设计之处就是定义为可扩展的。
转载于:https://blog.51cto.com/4837471/2157940

















 1835
1835

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









