



 本文详细介绍了一种基于Orchestrator、Consul和GLB的高可用性MySQL集群方案,利用Mysql最新复制技术,结合半同步复制和GTID,实现了故障自动监听与恢复。通过Orchestrator进行集群管理,简化了运维工作,提升了数据库的稳定性和效率。
本文详细介绍了一种基于Orchestrator、Consul和GLB的高可用性MySQL集群方案,利用Mysql最新复制技术,结合半同步复制和GTID,实现了故障自动监听与恢复。通过Orchestrator进行集群管理,简化了运维工作,提升了数据库的稳定性和效率。

Github基于Orchestrator,Consul和GLB实现高可用性目标。
- orchestrator用来运行故障监听和故障恢复。我们使用了如下图所示的一个跨数据中心的orchestrator/raft。
- Hashicorp公司的用于服务发现的Consul。使用Consul的KV存储器写入集群主节点的身份。对于每个集群,都有一套KV记录表明集群的主节点的fqdn、port、ipv4和ipv6。
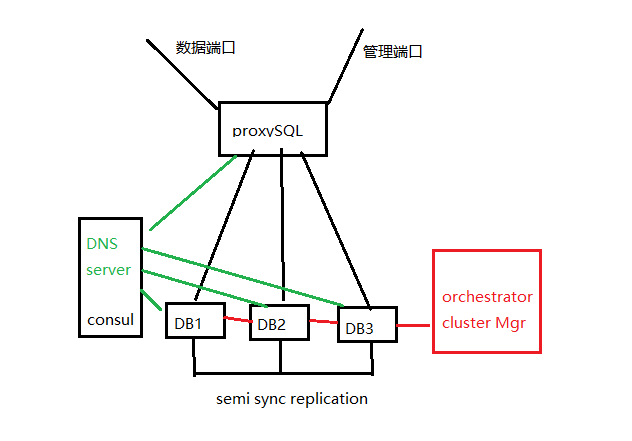
- 作为客户端和写操作节点之间的代理层的GLB/HAProxy。
- 用于网络路由的anycast。
概述方案
基本GTID, 多线程,无损半同步复制
- 配置简单, 可复用运维人员的经验。
- 运用了Mysql最新的复制技术。
orchestrator特点:
- 提高了Mysql复制的运维的友好性,可视化操作。
- 基于Raft分步式一致性协议支持高可用性。
- 可主动爬行您的拓扑结构,可以读取基本的MySQL信息,例如复制状态和配置。
- 理解复制规则。 它知道binlog文件:position,GTID,Pseudo GTID,Binlog Servers。
- 根据复制拓扑结构,它可识别各种故障情况,Master并调解Master的故障。
- 无侵入性, 支持Mysql、Percona Mysql,、MarriaDB等,现在类似的方案中, MGR, PXC都会不同程度的锁定用户。
半同步配置
Host配置
10.1.1.106 serv10 serv10.bigdata.com
10.1.1.228 serv11 serv11.bigdata.com
10.1.1.176 serv12 serv12.bigdata.com
10.1.1.178 serv13 serv13.bigdata.com
后面可以很方便的改成DNS解析方式。
安装Mysql插件
INSTALL PLUGIN rpl_semi_sync_master SONAME 'semisync_master.so';
INSTALL PLUGIN rpl_semi_sync_slave SONAME 'semisync_slave.so';
Master配置
创建复制用户
CREATE USER 'repl'@'%' IDENTIFIED BY 'slavePass.123!@#';
GRANT REPLICATION SLAVE ON *.* TO 'repl'@'%';
flush privileges;
在Master创建即可, 为了方便 故障切换,可以每个server上都创建。
修改my.cnf文件
log-error=/var/log/mysqld.log
server-id=1
log-bin = mysql-bin
#mysql-bin-index = mysql-bin.index
log_timestamps = SYSTEM
gtid_mode = on
enforce-gtid-consistency
relay_log_recovery=1
log-slave-updates = 1
innodb_flush_log_at_trx_commit=1
sync_binlog=1
binlog_format = row
expire_logs_days = 10
slow_query_log = on
long_query_time = 2
log-queries-not-using-indexes
slow_query_log_file = /var/log/mysql/slow.log
replicate-ignore-db = mysql
replicate-ignore-db = information_schema
replicate-ignore-db = performance_schema
replicate-ignore-db = sys
replicate_do_db = test
rpl_semi_sync_master_enabled = on
Slave配置
log-error=/var/log/mysqld.log
server-id = 2
log-bin = mysql-bin
#mysql-bin-index = mysql-bin.index
log_timestamps = SYSTEM
gtid_mode = on
enforce-gtid-consistency=1
skip_slave_start=1 #是否Mysql启动时也启动?
slave-parallel-type=LOGICAL_CLOCK
slave-parallel-workers=16
master_info_repository=table
relay_log_info_repository=table
relay_log_recovery=1
log-slave-updates=1
innodb_flush_log_at_trx_commit=2
sync_binlog=0
read_only=true
slow_query_log = on
long_query_time = 2
slow_query_log_file =/var/log/mysql/slow.log
log-queries-not-using-indexes
replicate-ignore-db = mysql
replicate-ignore-db = information_schema
replicate-ignore-db = performance_schema
replicate-ignore-db = sys
replicate_do_db = test
rpl_semi_sync_slave_enabled = on
show master status
root@localhost (none) Tue Sep 25 07:37:40 2018>show master status\G;
*************************** 1. row ***************************
File: mysql-bin.000019
Position: 191
Binlog_Do_DB:
Binlog_Ignore_DB:
Executed_Gtid_Set: 1848ba94-76e9-11e8-a6bc-525400a0c246:1-24
1 row in set (0.00 sec)
show slave status解析
https://dev.mysql.com/doc/refman/5.7/en/show-slave-status.html
***************************1.row***************************
Slave_IO_State:Waitingformastertosendevent
Master_Host:192.168.22.65
Master_User:repl
Master_Port:3306
Connect_Retry:60
Master_Log_File:mysql-bin.000004
Read_Master_Log_Pos:112951358 IO线程读取到主库的binlog文件名和该binlog中的位置。
Relay_Log_File:vm03-relay-bin-master_vm01.000030
Relay_Log_Pos:48472910 SQL线程执行到relay log文件名和该relay log中的位置。
Relay_Master_Log_File:mysql-bin.000004
Exec_Master_Log_Pos:112951358 SQL线程执行到relay log对应主库中的binlog文件名和该binlog的位置。
Slave_IO_Running:Yes
Slave_SQL_Running:Yes
Replicate_Do_DB:platform_data,bigdata_cctsoft,security_NMP
Replicate_Ignore_DB:mysql,information_schema,performance_schema,sys
Replicate_Do_Table:
Replicate_Ignore_Table:
Replicate_Wild_Do_Table:
Replicate_Wild_Ignore_Table:
Last_Errno:0
Last_Error:
Skip_Counter:0
Relay_Log_Space:50212137
Until_Condition:None
Until_Log_File:
Until_Log_Pos:0
Master_SSL_Allowed:No
Master_SSL_CA_File:
Master_SSL_CA_Path:
Master_SSL_Cert:
Master_SSL_Cipher:
Master_SSL_Key:
Seconds_Behind_Master:0
Master_SSL_Verify_Server_Cert:No
Last_IO_Errno:0
Last_IO_Error:
Last_SQL_Errno:0
Last_SQL_Error:
Replicate_Ignore_Server_Ids:
Master_Server_Id:2
Master_UUID:3d7f0b22-994b-11e7-afd5-525400aeed8f
Master_Info_File:mysql.slave_master_info
SQL_Delay:0
SQL_Remaining_Delay:NULL
Slave_SQL_Running_State:Slave has read all relay log; waiting form or eupdates
Master_Retry_Count:86400
Master_Bind:
Last_IO_Error_Timestamp:
Last_SQL_Error_Timestamp:
Master_SSL_Crl:
Master_SSL_Crlpath:
Retrieved_Gtid_Set:3d7f0b22-994b-11e7-afd5-525400aeed8f:1-133757 #已经从Master上获取的Gtid
Executed_Gtid_Set:3d7f0b22-994b-11e7-afd5-525400aeed8f:1-5:133755-133757
Auto_Position:1
Replicate_Rewrite_DB:
Channel_Name:master_vm01
Master_TLS_Version:
异常处理
Fatal error: The slave I/O thread stops because master and slave have equal MySQL server UUIDs; these UUIDs must be different for replication to work.
rm /var/lib/mysql/auto.cnf
ERROR 1872 (HY000): Slave failed to initialize relay log info structure from the repository
reset slave
1、删除slave_master_info ,slave_relay_log_info两个表中数据; 2、删除所有relay log文件,并重新创建新的relay log文件; 3、不会改变gtid_executed 或者 gtid_purged的值
控制从库复制是否自启动
mysql默认在启动时, slave也会自动启动复制。就是说IO进程和SQL进程状态都自动变为Yes.
怎样让从不自动启动复制呢? 在my.cnf配置: skip-slave-start = 1
重启从库生效。
show variables like '%relay%';
show slave status\G;
show variables like 'rpl%';
show status like 'rpl%';
查看master 状态
mysql> show global status like 'rpl%';
+--------------------------------------------+-------+
| Variable_name | Value |
+--------------------------------------------+-------+
| Rpl_semi_sync_master_clients | 1 |
| Rpl_semi_sync_master_net_avg_wait_time | 0 |
| Rpl_semi_sync_master_net_wait_time | 0 |
| Rpl_semi_sync_master_net_waits | 1 |
| Rpl_semi_sync_master_no_times | 0 |
| Rpl_semi_sync_master_no_tx | 0 |
| Rpl_semi_sync_master_status | ON |
| Rpl_semi_sync_master_timefunc_failures | 0 |
| Rpl_semi_sync_master_tx_avg_wait_time | 698 |
| Rpl_semi_sync_master_tx_wait_time | 698 |
| Rpl_semi_sync_master_tx_waits | 1 |
| Rpl_semi_sync_master_wait_pos_backtraverse | 0 |
| Rpl_semi_sync_master_wait_sessions | 0 |
| Rpl_semi_sync_master_yes_tx | 1 |
| Rpl_semi_sync_slave_status | OFF |
+--------------------------------------------+-------+
15 rows in set (0.01 sec)
mysql> show global status like '%master%';
| Com_change_master | 0 |
| Com_show_master_status | 0 |
| master_info_repository | TABLE |
| master_verify_checksum | OFF |
| sync_master_info | 10000 |
| Com_group_replication_start | 0 |
| Com_group_replication_stop | 0 |
状态值注释
Rpl_semi_sync_master_status 是否启用了半同步。
Rpl_semi_sync_master_clients 半同步模式下Slave一共有多少个。
Rpl_semi_sync_master_no_tx 往slave发送失败的事务数量。
Rpl_semi_sync_master_yes_tx 往slave发送成功的事务数量。
查看master变量
mysql> show variables like 'rpl%';
+-------------------------------------------+------------+
| Variable_name | Value |
+-------------------------------------------+------------+
| rpl_semi_sync_master_enabled | ON |
| rpl_semi_sync_master_timeout | 10000 |
| rpl_semi_sync_master_trace_level | 32 |
| rpl_semi_sync_master_wait_for_slave_count | 1 |
| rpl_semi_sync_master_wait_no_slave | ON |
| rpl_semi_sync_master_wait_point | AFTER_SYNC |
| rpl_semi_sync_slave_enabled | OFF |
| rpl_semi_sync_slave_trace_level | 32 |
| rpl_stop_slave_timeout | 31536000 |
+-------------------------------------------+------------+
9 rows in set (0.00 sec)
相关参数注释:
rpl_semi_sync_master_timeout
控制半同步复制切换为异步复制, Master等待slave响应的时间,单位是毫秒,默认值是10秒,超过这个时间,slave无响应,环境架构将自动转换为异步复制, 当master dump线程发送完一个事务的所有事件之后,如果在rpl_semi_sync_master_timeout内,收到了从库的响应,则主从又重新恢复为半同步复制。
rpl_semi_sync_master_trace_level
监控等级,一共4个等级(1,16,32,64),后续补充详细。
rpl_semi_sync_master_wait_no_slave
是否允许master 每个事物提交后都要等待slave的receipt信号。默认为on ,每一个事务都会等待,如果slave当掉后,当slave追赶上master的日志时,可以自动的切换为半同步方式,如果为off,则slave追赶上后,也不会采用半同步的方式复制了,需要手工配置。
rpl_stop_slave_timeout
控制stop slave 的执行时间,在重放一个大的事务的时候,突然执行stop slave ,命令 stop slave会执行很久,这个时候可能产生死锁或阻塞,严重影响性能,mysql 5.6可以通过rpl_stop_slave_timeout参数控制stop slave 的执行时间
rpl_semi_sync_master_wait_for_slave_count
至少有N个slave接收到日志
查看slave变量和状态
mysql> show variables like '%relay%' ;
+---------------------------+---------------------------------------+
| Variable_name | Value |
+---------------------------+---------------------------------------+
| max_relay_log_size | 0 |
| relay_log | |
| relay_log_basename | /var/lib/mysql/serv11-relay-bin |
| relay_log_index | /var/lib/mysql/serv11-relay-bin.index |
| relay_log_info_file | relay-log.info |
| relay_log_info_repository | TABLE |
| relay_log_purge | ON |
| relay_log_recovery | ON |
| relay_log_space_limit | 0 |
| sync_relay_log | 10000 |
| sync_relay_log_info | 10000 |
+---------------------------+---------------------------------------+
11 rows in set (0.02 sec)
mysql> show status like '%relay%' ;
+--------------------------+-------+
| Variable_name | Value |
+--------------------------+-------+
| Com_show_relaylog_events | 0 |
+--------------------------+-------+
1 row in set (0.01 sec)
root@localhost (none) Wed Sep 26 11:22:26 2018>show global status like 'rpl%';
+--------------------------------------------+-------+
| Variable_name | Value |
+--------------------------------------------+-------+
| Rpl_semi_sync_master_clients | 0 |
| Rpl_semi_sync_master_net_avg_wait_time | 0 |
| Rpl_semi_sync_master_net_wait_time | 0 |
| Rpl_semi_sync_master_net_waits | 0 |
| Rpl_semi_sync_master_no_times | 0 |
| Rpl_semi_sync_master_no_tx | 0 |
| Rpl_semi_sync_master_status | OFF |
| Rpl_semi_sync_master_timefunc_failures | 0 |
| Rpl_semi_sync_master_tx_avg_wait_time | 0 |
| Rpl_semi_sync_master_tx_wait_time | 0 |
| Rpl_semi_sync_master_tx_waits | 0 |
| Rpl_semi_sync_master_wait_pos_backtraverse | 0 |
| Rpl_semi_sync_master_wait_sessions | 0 |
| Rpl_semi_sync_master_yes_tx | 0 |
| Rpl_semi_sync_slave_status | ON |
+--------------------------------------------+-------+
15 rows in set (0.00 sec)
若干问题
1:半同步复制设置N个slave应答,如果当前Slave小于N会怎样?
答:取决于rpl_semi_sync_master_wait_no_slave的设置。
- rpl_semi_sync_master_wait_no_slave = 0
会立刻变成异步复制。
- rpl_semi_sync_master_wait_no_slave = 1
仍然等待应答,直到超时。
2:基于GTID的复制,可以指定GTID复制的起始位置么,还是只能根据现有的信息?
答:GTID复制就是为了摆脱对binlog文件名和位置的依赖。所以不能指定复制的起始位置,也完全没有必要指定。
3:对一个已经开启GTID的数据库再做一个从库,先把Master备份下来还原到新slave上去,直接可以同步了还是先需要做purge_gtid的操作再同步呢?
答:需要设置gtid_purged。整个过程可以通过mysqldump完成。
请参考手册:http://dev.mysql.com/doc/refman/5.7/en/replication-gtids-failover.html#replication-gtids-failover-copy
4:在主从复制过程中,是主向从推数据还是从拉数据,如果这个传送的过程中,出现网络闪断,会不会造成数据包丢失,会执行校验重传嘛?
答:Slave 的IO线程发起到Master的连接。
然后master开始发送events,slave只是被动的接收。
slave和master之间使用的是tcp 连接。tcp是可靠的连接。网络丢包等都是tcp层自动处理的。
mysql不需要处理。
如果slave长时间不能收到一个完整的Event,或者接收event时出错。slave
会进行相应的处理。
如果slave认为,重新建立连接能解决问题。slave则自动的断开原来的连接,然后重新连接到master去。
如果slave认为,这个错误无法自动解决,slave会停掉io线程,并报错。
Orchestrator
创建用户
CREATE USER 'orchestrator'@'%' IDENTIFIED WITH mysql_native_password BY 'orch_topology_password';
GRANT SUPER, PROCESS, REPLICATION SLAVE, RELOAD, SELECT ON *.* TO 'orchestrator'@'%';
GRANT SELECT ON mysql.slave_master_info TO 'orchestrator'@'%';
flush privileges;
修改配置
[root@serv10 orchestrator]# cat /usr/local/orchestrator/orchestrator.conf.json
{
"Debug": true,
"EnableSyslog": false,
"ListenAddress": ":3000",
"MySQLTopologyUser": "orchestrator",
"MySQLTopologyPassword": "orch_topology_password",
"MySQLTopologyCredentialsConfigFile": "",
"MySQLTopologySSLPrivateKeyFile": "",
"MySQLTopologySSLCertFile": "",
"MySQLTopologySSLCAFile": "",
"MySQLTopologySSLSkipVerify": true,
"MySQLTopologyUseMutualTLS": false,
"MySQLOrchestratorHost": "serv13",
"MySQLOrchestratorPort": 3306,
"MySQLOrchestratorDatabase": "orchestrator",
"MySQLOrchestratorUser": "orchestrator",
"MySQLOrchestratorPassword": "orch_topology_password",
"MySQLOrchestratorCredentialsConfigFile": "",
"MySQLOrchestratorSSLPrivateKeyFile": "",
"MySQLOrchestratorSSLCertFile": "",
"MySQLOrchestratorSSLCAFile": "",
"MySQLOrchestratorSSLSkipVerify": true,
"MySQLOrchestratorUseMutualTLS": false,
"MySQLConnectTimeoutSeconds": 1,
"DefaultInstancePort": 3306,
"DiscoverByShowSlaveHosts": true,
"InstancePollSeconds": 5,
"UnseenInstanceForgetHours": 240,
"SnapshotTopologiesIntervalHours": 0,
"InstanceBulkOperationsWaitTimeoutSeconds": 10,
"HostnameResolveMethod": "default",
"MySQLHostnameResolveMethod": "@@hostname",
"SkipBinlogServerUnresolveCheck": true,
"ExpiryHostnameResolvesMinutes": 60,
"RejectHostnameResolvePattern": "",
"ReasonableReplicationLagSeconds": 10,
"ProblemIgnoreHostnameFilters": [],
"VerifyReplicationFilters": false,
"ReasonableMaintenanceReplicationLagSeconds": 20,
"CandidateInstanceExpireMinutes": 60,
"AuditLogFile": "",
"AuditToSyslog": false,
"RemoveTextFromHostnameDisplay": ".mydomain.com:3306",
"ReadOnly": false,
"AuthenticationMethod": "",
"HTTPAuthUser": "",
"HTTPAuthPassword": "",
"AuthUserHeader": "",
"PowerAuthUsers": [
"*"
],
"ClusterNameToAlias": {
"127.0.0.1": "test suite"
},
"SlaveLagQuery": "",
"DetectClusterAliasQuery": "SELECT SUBSTRING_INDEX(@@hostname, '.', 1)",
"DetectClusterDomainQuery": "",
"DetectInstanceAliasQuery": "",
"DetectPromotionRuleQuery": "",
"DataCenterPattern": "[.]([^.]+)[.][^.]+[.]mydomain[.]com",
"PhysicalEnvironmentPattern": "[.]([^.]+[.][^.]+)[.]mydomain[.]com",
"PromotionIgnoreHostnameFilters": [],
"DetectSemiSyncEnforcedQuery": "",
"ServeAgentsHttp": false,
"AgentsServerPort": ":3001",
"AgentsUseSSL": false,
"AgentsUseMutualTLS": false,
"AgentSSLSkipVerify": false,
"AgentSSLPrivateKeyFile": "",
"AgentSSLCertFile": "",
"AgentSSLCAFile": "",
"AgentSSLValidOUs": [],
"UseSSL": false,
"UseMutualTLS": false,
"SSLSkipVerify": false,
"SSLPrivateKeyFile": "",
"SSLCertFile": "",
"SSLCAFile": "",
"SSLValidOUs": [],
"URLPrefix": "",
"StatusEndpoint": "/api/status",
"StatusSimpleHealth": true,
"StatusOUVerify": false,
"AgentPollMinutes": 60,
"UnseenAgentForgetHours": 6,
"StaleSeedFailMinutes": 60,
"SeedAcceptableBytesDiff": 8192,
"PseudoGTIDPattern": "",
"PseudoGTIDPatternIsFixedSubstring": false,
"PseudoGTIDMonotonicHint": "asc:",
"DetectPseudoGTIDQuery": "",
"BinlogEventsChunkSize": 10000,
"SkipBinlogEventsContaining": [],
"ReduceReplicationAnalysisCount": true,
"FailureDetectionPeriodBlockMinutes": 60,
"RecoveryPeriodBlockSeconds": 3600,
"RecoveryIgnoreHostnameFilters": [],
"RecoverMasterClusterFilters": [
"*"
],
"RecoverIntermediateMasterClusterFilters": [
"*"
],
"OnFailureDetectionProcesses": [
"echo 'Detected {failureType} on {failureCluster}. Affected replicas: {countSlaves}' >> /tmp/recovery.log"
],
"PreGracefulTakeoverProcesses": [
"echo 'Planned takeover about to take place on {failureCluster}. Master will switch to read_only' >> /tmp/recovery.log"
],
"PreFailoverProcesses": [
"echo 'Will recover from {failureType} on {failureCluster}' >> /tmp/recovery.log"
],
"PostFailoverProcesses": [
"echo '(for all types) Recovered from {failureType} on {failureCluster}. Failed: {failedHost}:{failedPort}; Successor: {successorHost}:{successorPort}' >> /tmp/recovery.log"
],
"PostUnsuccessfulFailoverProcesses": [],
"PostMasterFailoverProcesses": [
"echo 'Recovered from {failureType} on {failureCluster}. Failed: {failedHost}:{failedPort}; Promoted: {successorHost}:{successorPort}' >> /tmp/recovery.log"
],
"PostIntermediateMasterFailoverProcesses": [
"echo 'Recovered from {failureType} on {failureCluster}. Failed: {failedHost}:{failedPort}; Successor: {successorHost}:{successorPort}' >> /tmp/recovery.log"
],
"PostGracefulTakeoverProcesses": [
"echo 'Planned takeover complete' >> /tmp/recovery.log"
],
"CoMasterRecoveryMustPromoteOtherCoMaster": true,
"DetachLostSlavesAfterMasterFailover": true,
"ApplyMySQLPromotionAfterMasterFailover": true,
"MasterFailoverDetachSlaveMasterHost": false,
"MasterFailoverLostInstancesDowntimeMinutes": 0,
"PostponeSlaveRecoveryOnLagMinutes": 0,
"OSCIgnoreHostnameFilters": [],
"GraphiteAddr": "",
"GraphitePath": "",
"GraphiteConvertHostnameDotsToUnderscores": true,
"ConsulAddress": "",
"ConsulAclToken": ""
}
RecoverMasterClusterFilters 和 RecoverIntermediateMasterClusterFilters 必须配置为["*"],否则自动切换不会触发。
FailureDetectionPeriodBlockMinutes 和 RecoveryPeriodBlockSeconds 参数默认值为1个小时,也就是如果发生了故障切换,在1个小时之内,该主库再次出现故障,将不会被监测到,也不会触发故障切换。
orchestrator表
| access_token |
| active_node |
| agent_seed |
| agent_seed_state |
| async_request |
| audit |
| blocked_topology_recovery |
| candidate_database_instance |
| cluster_alias |
| cluster_alias_override |
| cluster_domain_name |
| cluster_injected_pseudo_gtid |
| database_instance |
| database_instance_analysis_changelog |
| database_instance_binlog_files_history |
| database_instance_coordinates_history |
| database_instance_downtime |
| database_instance_last_analysis |
| database_instance_long_running_queries |
| database_instance_maintenance |
| database_instance_peer_analysis |
| database_instance_pool |
| database_instance_recent_relaylog_history |
| database_instance_tls |
| database_instance_topology_history |
| global_recovery_disable |
| host_agent |
| host_attributes |
| hostname_ips |
| hostname_resolve |
| hostname_resolve_history |
| hostname_unresolve |
| hostname_unresolve_history |
| kv_store |
| master_position_equivalence |
| node_health |
| node_health_history |
| orchestrator_db_deployments |
| orchestrator_metadata |
| raft_log |
| raft_snapshot |
| raft_store |
| topology_failure_detection |
| topology_recovery |
| topology_recovery_steps |
管理UI
http://10.1.1.106:3000/web/cluster/serv10:3306
拓扑结构
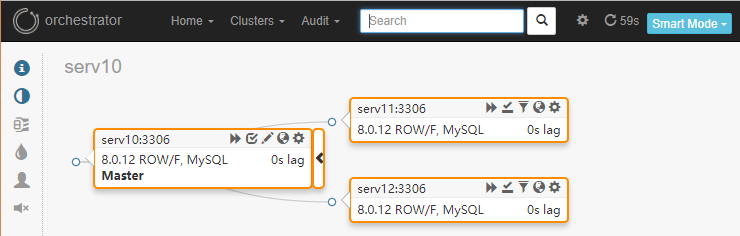
通过拖动节点,就可以改变集群的拓扑结构。
命令行方式查看:
[root@serv10 orchestrator]# orchestrator -c topology -i 127.0.0.1:22987
2018-09-24 11:53:24 DEBUG Hostname unresolved yet: 127.0.0.1
2018-09-24 11:53:24 DEBUG Cache hostname resolve 127.0.0.1 as 127.0.0.1
2018-09-24 11:53:24 DEBUG Connected to orchestrator backend: orchestrator:?@tcp(serv13:3306)/orchestrator?timeout=1s
2018-09-24 11:53:24 DEBUG Orchestrator pool SetMaxOpenConns: 128
2018-09-24 11:53:24 DEBUG Initializing orchestrator
2018-09-24 11:53:24 INFO Connecting to backend serv13:3306: maxConnections: 128, maxIdleConns: 32
2018-09-24 11:53:24 DEBUG instanceKey: serv10:3306
2018-09-24 11:53:24 DEBUG instanceKey: serv11:3306
2018-09-24 11:53:24 DEBUG instanceKey: serv12:3306
serv10:3306 [0s,ok,8.0.12,rw,ROW,>>,GTID]
+ serv11:3306 [0s,ok,8.0.12,ro,ROW,>>,GTID]
+ serv12:3306 [0s,ok,8.0.12,ro,ROW,>>,GTID]
管理节点
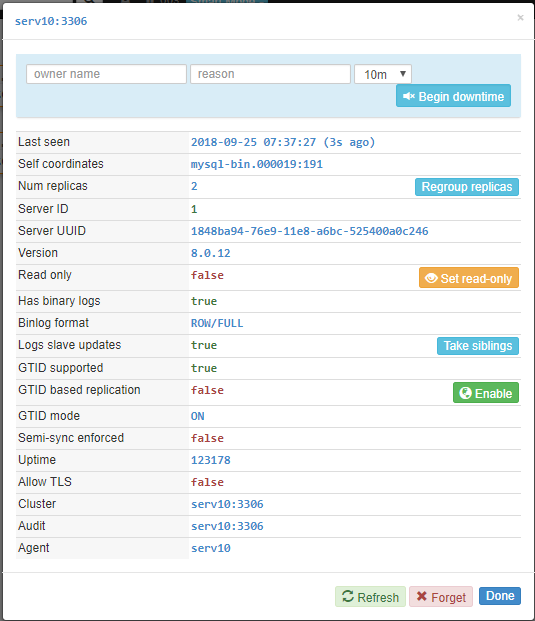
集群节点列表
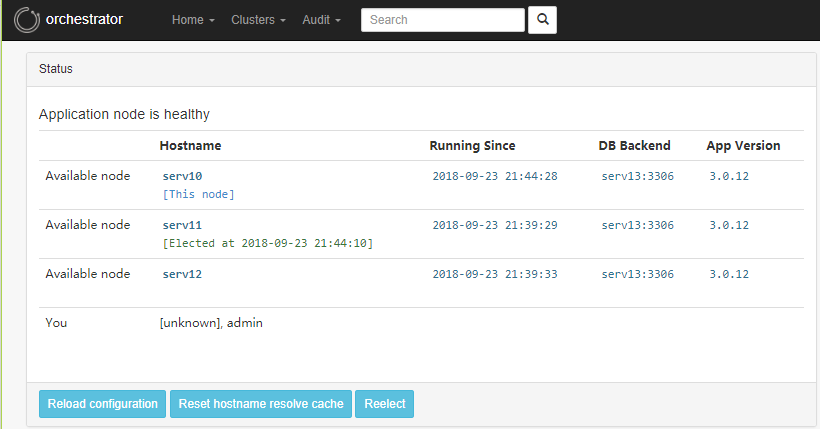
众多的管理命令
Orchestrator 提供了近130条管理命令,分下面几大类:
- Smart relocation
- Classic file:pos relocation
- Binlog server relocation
- GTID relocation
- Pseudo-GTID relocation
- Replication, general
- Replication information
- Binary logs
- Pools
- Cluster Information
- Key-value
- Instance, meta
- Instance management
- Recovery
- Meta, internal
- Internal
- Agent

















 1227
1227

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









