






 本文详细介绍DBSCAN算法,一种基于密度的聚类方法,能有效处理带噪数据并发现任意形状的簇。文中解释了核心点、边界点及噪音点的概念,并给出算法流程。
本文详细介绍DBSCAN算法,一种基于密度的聚类方法,能有效处理带噪数据并发现任意形状的簇。文中解释了核心点、边界点及噪音点的概念,并给出算法流程。
版权声明:本文为博主原创文章,未经博主允许不得转载。
最近接触到Dbscan算法,所以相对其进行研究,就多方面参考资料进行总结,下面是我的小小总结,希望博友们一起讨论!
一、基于密度的聚类算法的概述
Dbscan算法:全称为:Density-Based Spatial Clustering of Applications with Noise(具有噪声的基于密度的聚类方法)。这是一种基于密度的聚类算法,能够除去噪音点,并且聚类的结果是划分为多个簇,簇的形状是任意的。基于密度的聚类算法都是寻找被低密度区域分离的高密度区域。
基于密度的聚类算法主要的目标是寻找被低密度区域分离的高密度区域。与基于距离的聚类算法不同的是,基于距离的聚类算法的聚类结果是球状的簇,而基于密度的聚类算法可以发现任意形状的聚类,这对于带有噪音点的数据起着重要的作用。
二、基本概念
- 核心点。在半径Eps内含有超过MinPts数目的点
- 边界点。在半径Eps内点的数量小于MinPts,但是落在核心点的邻域内
- 噪音点。既不是核心点也不是边界点的点
- Eps邻域。简单来讲就是与点
的距离小于等于Eps的所有的点的集合,可以表示为
。
- 直接密度可达。如果
的Eps邻域内,则称对象
- 密度可达。对于对象链:
,
是从
关于Eps和MinPts直接密度可达的,则对象
是从对象
关于Eps和MinPts密度可达的。经过一个或多个密度范围能够找到。
- 密度相连。这是重点,简单理解就是,如果存在属于集合D的对象O,使得对象p和q都是从O关于Eps和MInPts密度可达的,那么对象p到q是关于Eps和MinPts密度相连的。而dbscan算法的目的就是要找出最大的密度相连集合。
为了便于理解我们给出了一个例子:
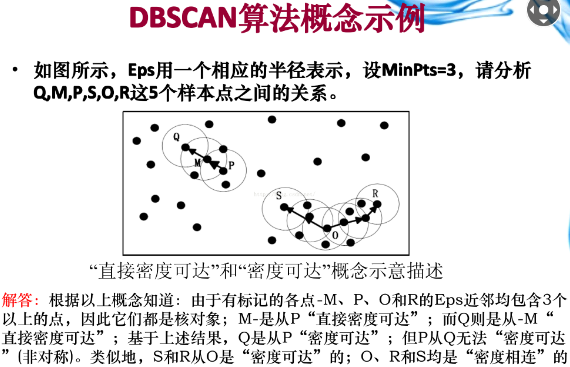
三、算法过程
-
输入:数据样本D,初始化所有点为未访问,半径ε,和最少点数MinPts。
-
1、建立neighbor队列;
- 2、如果D中数据全部处理完,则算法结束,否则从D中选择一个未处理的点,标记为已访问,获得其所有直接密度可达点,如果为非核心点则标记为noise,重复步骤2,否则生成新的cluster,进入步骤3;
- 3、将当前核心点放入该cluster,将该核心点的直接密度可达点放入neighbor队列,并遍历该队列,如果neighbor队列全部遍历完则回溯至步骤2;
- 3.1 如果该点已经访问过,则进入步骤3.2,否则标记为已访问,然后获得该点的所有密度可达点,如果这个点也为核心点,则将该点的所有直接密度可达点放入neighbor队列;
- 3.2 如果该点不属于任何cluster,则放入当前cluster;
- 4、算法结束。
或者:输入:半径ϵ,给定点在ϵ邻域内成为核心对象的最小邻域点数MinPts,数据集D
-
输出:目标类簇集合
Repeat:
(1) 判断输入点是否为核心对象
(2) 找出核心对象的ϵ邻域中的所有直接密度可达点
Until 所有输入点都判断完毕
Repeat:
针对所有核心对象的ϵ邻域内所有直接密度可达点找到最大密度相连对象集合,中间涉及到一些密度可达对象的合并
Until 所有核心对象的ϵ邻域都遍历完毕
或者:dbscan算法本质上是一个寻找类簇并不断扩展类簇的过程,要形成类簇首先数据密度要满足要求。对任意点p,若其是核心点,则以p为中心 r 为半径可以形成一个类簇C,扩展类簇的方法则是遍历簇中的点,若有点q是核心点,则将q的 r 邻域内的点也划入类C,递归执行直到C不能再扩展。
1.将数据集D中的所有点标记为未访问状态,且簇Id为0. 2. for p in D: if p 已经访问过或者p的簇Id !=0: continue; else: 标记点p已经访问过; 获取p点Eps邻域内的点集合,个数为Neps(p); if Neps(p) <=0 : 标记p的簇Id为-1(噪音点); else if Neps(p) >= MinPts: 此时标记对象p为核心点,簇Id +=1,并设置邻域内各点的簇Id; for q in p的Eps邻域所有未处理点的集合: 检查q的簇Id是否等于0,若不,则判断Neps(q)是否大于等于MInPts,满足则标记簇Id为p的簇Id.

















 12万+
12万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









