






 本文深入讲解了Python中的高级主题,包括装饰器、迭代器、生成器、内置函数、匿名函数、递归函数及二分查找算法等内容。通过具体示例介绍了如何使用这些高级特性来优化代码。
本文深入讲解了Python中的高级主题,包括装饰器、迭代器、生成器、内置函数、匿名函数、递归函数及二分查找算法等内容。通过具体示例介绍了如何使用这些高级特性来优化代码。
目录
装饰器函数
迭代器和生成器
内置函数和匿名函数
递归函数
二分查找算法
装饰器函数
作为一个会写函数的python开发,我们从今天开始要去公司上班了。写了一个函数,就交给其他开发用了。
def func1():
print('in func1')
季度末,公司的领导要给大家发绩效奖金了,就提议对这段日子所有人开发的成果进行审核,审核的标准是什么呢?就是统计每个函数的执行时间。
这个时候你要怎么做呀?
你一想,这好办,把函数一改:
import time
def func1():
start = time.time()
print('in func1')
print(time.time() - start)
func1()
来公司半年,写了2000+函数,挨个改一遍,1个礼拜过去了,等领导审核完,再挨个给删了。。。又1个礼拜过去了。。。这是不是很闹心?
你觉得不行,不能让自己费劲儿,告诉所有开发,现在你们都在自己原本的代码上加上一句计算时间的语句?
import time
def func1():
print('in func1')
start = time.time()
func1()
print(time.time() - start)
还是不行,因为这样对于开发同事来讲实在是太麻烦了。
那怎么办呢?你灵机一动,写了一个timer函数。。。
import time
def timer(func):
start = time.time()
func()
print(time.time() - start)
def func1():
print('in func1')
def func2():
print('in func2')
timer(func1)
timer(func2)
这样看起来是不是简单多啦?不管我们写了多少个函数都可以调用这个计时函数来计算函数的执行时间了。。。尽管现在修改成本已经变得很小很小了,但是对于同事来说还是改变了这个函数的调用方式,假如某同事因为相信你,在他的代码里用你的方法用了2w多次,那他修改完代码你们友谊的小船也就彻底地翻了。
你要做的就是,让你的同事依然调用func1,但是能实现调用timer方法的效果。
import time
def timer(func):
start = time.time()
func()
print(time.time() - start)
def func1():
print('in func1')
func1 =timer #要是能这样的就完美了。。。可惜报错
func1()
非常可惜,上面这段代码是会报错的,因为timer方法需要传递一个func参数,我们不能在赋值的时候传参,因为只要执行func1 = timer(func1),timer方法就直接执行了,下面的那句func1根本就没有意义。到这里,我们的思路好像陷入了僵局。。。
装饰器的形成过程
import time
def func1():
print('in func1')
def timer(func):
def inner():
start = time.time()
func()
print(time.time() - start)
return inner
func1 = timer(func1)
func1()
忙活了这么半天,终于初具规模了!现在已经基本上完美了,唯一碍眼的那句话就是还要在做一次赋值调用。。。
你觉得碍眼,python的开发者也觉得碍眼,所以就为我们提供了一句语法糖来解决这个问题!
import time
def timer(func):
def inner():
start = time.time()
func()
print(time.time() - start)
return inner
@timer #==> func1 = timer(func1)
def func1():
print('in func1')
func1()
到这里,我们可以简单的总结一下:
装饰器的本质:一个闭包函数
装饰器的功能:在不修改原函数及其调用方式的情况下对原函数功能进行扩展
还有最后一个问题要解决,刚刚我们讨论的装饰器都是装饰不带参数的函数,现在要装饰一个带参数的函数怎么办呢?
def timer(func):
def inner(a):
start = time.time()
func(a)
print(time.time() - start)
return inner
@timer
def func1(a):
print(a)
func1(1)
其实装饰带参的函数并不是什么难事,但假如你有两个函数,需要传递的参数不一样呢?
import time
def timer(func):
def inner(*args,**kwargs):
start = time.time()
re = func(*args,**kwargs)
print(time.time() - start)
return re
return inner
@timer #==> func1 = timer(func1)
def func1(a,b):
print('in func1')
@timer #==> func2 = timer(func2)
def func2(a):
print('in func2 and get a:%s'%(a))
return 'fun2 over'
func1('aaaaaa','bbbbbb')
print(func2('aaaaaa'))
现在参数的问题已经完美的解决了,可是如果你的函数是有返回值的呢?
import time
def timer(func):
def inner(*args,**kwargs):
start = time.time()
re = func(*args,**kwargs)
print(time.time() - start)
return re
return inner
@timer #==> func2 = timer(func2)
def func2(a):
print('in func2 and get a:%s'%(a))
return 'fun2 over'
func2('aaaaaa')
print(func2('aaaaaa'))
刚刚那个装饰器已经非常完美了,但是正常我们情况下查看函数的一些信息的方法在此处都会失效
def index():
'''这是一个主页信息'''
print('from index')
print(index.__doc__) #查看函数注释的方法
print(index.__name__) #查看函数名的方法
为了不让他们失效,我们还要在装饰器上加上一点来完善它:
from functools import wraps
def deco(func):
@wraps(func) #加在最内层函数正上方
def wrapper(*args,**kwargs):
return func(*args,**kwargs)
return wrapper
@deco
def index():
'''哈哈哈哈'''
print('from index')
print(index.__doc__)
print(index.__name__)
开放封闭原则
1.对扩展是开放的
为什么要对扩展开放呢?
我们说,任何一个程序,不可能在设计之初就已经想好了所有的功能并且未来不做任何更新和修改。所以我们必须允许代码扩展、添加新功能。
2.对修改是封闭的
为什么要对修改封闭呢?
就像我们刚刚提到的,因为我们写的一个函数,很有可能已经交付给其他人使用了,如果这个时候我们对其进行了修改,很有可能影响其他已经在使用该函数的用户。
装饰器完美的遵循了这个开放封闭原则。
装饰器的主要功能和装饰器的固定结构
装饰器的主要功能:
在不改变函数调用方式的基础上在函数的前、后添加功能。
装饰器的固定格式:
def timer(func):
def inner(*args,**kwargs):
'''执行函数之前要做的'''
re = func(*args,**kwargs)
'''执行函数之后要做的'''
return re
return inner
from functools import wraps
def deco(func):
@wraps(func) #加在最内层函数正上方
def wrapper(*args,**kwargs):
return func(*args,**kwargs)
return wrapper
带参数的装饰器
假如你有成千上万个函数使用了一个装饰器,现在你想把这些装饰器都取消掉,你要怎么做?
一个一个的取消掉? 没日没夜忙活3天。。。
过两天你领导想通了,再让你加上。。。
def outer(flag):
def timer(func):
def inner(*args,**kwargs):
if flag:
print('''执行函数之前要做的''')
re = func(*args,**kwargs)
if flag:
print('''执行函数之后要做的''')
return re
return inner
return timer
@outer(False)
def func():
print(111)
func()
多个装饰器装饰同一个函数
有些时候,我们也会用到多个装饰器装饰同一个函数的情况。
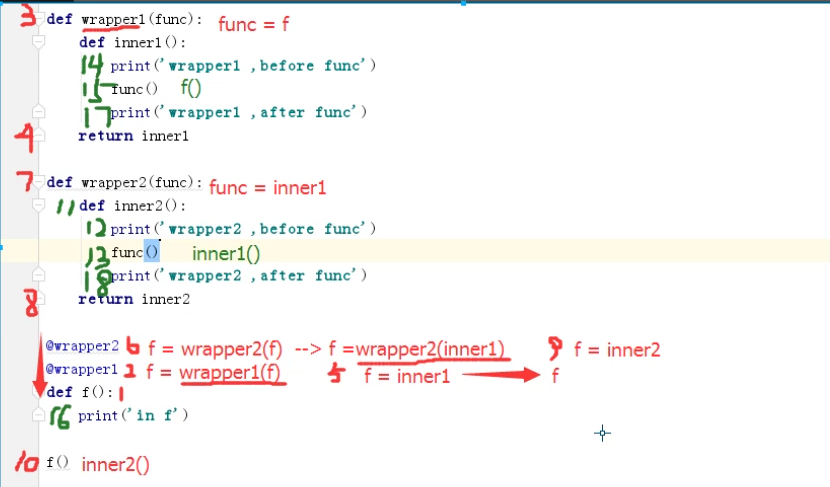
def wrapper1(func):
def inner():
print('wrapper1 ,before func')
func()
print('wrapper1 ,after func')
return inner
def wrapper2(func):
def inner():
print('wrapper2 ,before func')
func()
print('wrapper2 ,after func')
return inner
@wrapper2
@wrapper1
def f():
print('in f')
f()
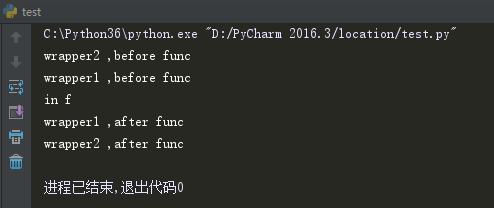
来,看下执行结果。 结果是不是执行过程的倒序。
迭代器和生成器
假如我现在有一个列表l=['a','b','c','d','e'],我想取列表中的内容,有几种方式?
首先,我可以通过索引取值l[0],其次我们是不是还可以用for循环来取值呀?
你有没有仔细思考过,用索引取值和for循环取值是有着微妙区别的。
如果用索引取值,你可以取到任意位置的值,前提是你要知道这个值在什么位置。
如果用for循环来取值,我们把每一个值都取到,不需要关心每一个值的位置,因为只能顺序的取值,并不能跳过任何一个直接去取其他位置的值。
但你有没有想过,我们为什么可以使用for循环来取值?
for循环内部是怎么工作的呢?
迭代器
python中的for循环
要了解for循环是怎么回事儿,咱们还是要从代码的角度出发。
首先,我们对一个列表进行for循环。
for i in [1,2,3,4]:
print(i)
上面这段代码肯定是没有问题的,但是我们换一种情况,来循环一个数字1234试试
for i in 1234
print(i)
结果:
Traceback (most recent call last):
File "test.py", line 4, in <module>
for i in 1234:
TypeError: 'int' object is not iterable
看,报错了!报了什么错呢?“TypeError: 'int' object is not iterable”,说int类型不是一个iterable,那这个iterable是个啥?

假如你不知道什么是iterable,我们可以翻翻词典,首先得到一个中文的解释,尽管翻译过来了你可能也不知道,但是没关系,我会带着你一步一步来分析。
迭代和可迭代协议
什么叫迭代
现在,我们已经获得了一个新线索,有一个叫做“可迭代的”概念。
首先,我们从报错来分析,好像之所以1234不可以for循环,是因为它不可迭代。那么如果“可迭代”,就应该可以被for循环了。
这个我们知道呀,字符串、列表、元组、字典、集合都可以被for循环,说明他们都是可迭代的。
我们怎么来证明这一点呢?
from collections import Iterable
l = [1,2,3,4]
t = (1,2,3,4)
d = {1:2,3:4}
s = {1,2,3,4}
print(isinstance(l,Iterable))
print(isinstance(t,Iterable))
print(isinstance(d,Iterable))
print(isinstance(s,Iterable))
结合我们使用for循环取值的现象,再从字面上理解一下,其实迭代就是我们刚刚说的,可以将某个数据集内的数据“一个挨着一个的取出来”,就叫做迭代。
可迭代协议
我们现在是从结果分析原因,能被for循环的就是“可迭代的”,但是如果正着想,for怎么知道谁是可迭代的呢?
假如我们自己写了一个数据类型,希望这个数据类型里的东西也可以使用for被一个一个的取出来,那我们就必须满足for的要求。这个要求就叫做“协议”。
可以被迭代要满足的要求就叫做可迭代协议。可迭代协议的定义非常简单,就是内部实现了__iter__方法。
接下来我们就来验证一下:
print(dir([1,2]))
print(dir((2,3)))
print(dir({1:2}))
print(dir({1,2}))
结果:
['__add__', '__class__', '__contains__', '__delattr__', '__delitem__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__getitem__', '__gt__', '__hash__', '__iadd__', '__imul__', '__init__', '__iter__', '__le__', '__len__', '__lt__', '__mul__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__reversed__', '__rmul__', '__setattr__', '__setitem__', '__sizeof__', '__str__', '__subclasshook__', 'append', 'clear', 'copy', 'count', 'extend', 'index', 'insert', 'pop', 'remove', 'reverse', 'sort'] ['__add__', '__class__', '__contains__', '__delattr__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__getitem__', '__getnewargs__', '__gt__', '__hash__', '__init__', '__iter__', '__le__', '__len__', '__lt__', '__mul__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__rmul__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', 'count', 'index'] ['__class__', '__contains__', '__delattr__', '__delitem__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__getitem__', '__gt__', '__hash__', '__init__', '__iter__', '__le__', '__len__', '__lt__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__setitem__', '__sizeof__', '__str__', '__subclasshook__', 'clear', 'copy', 'fromkeys', 'get', 'items', 'keys', 'pop', 'popitem', 'setdefault', 'update', 'values'] ['__and__', '__class__', '__contains__', '__delattr__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__gt__', '__hash__', '__iand__', '__init__', '__ior__', '__isub__', '__iter__', '__ixor__', '__le__', '__len__', '__lt__', '__ne__', '__new__', '__or__', '__rand__', '__reduce__', '__reduce_ex__', '__repr__', '__ror__', '__rsub__', '__rxor__', '__setattr__', '__sizeof__', '__str__', '__sub__', '__subclasshook__', '__xor__', 'add', 'clear', 'copy', 'difference', 'difference_update', 'discard', 'intersection', 'intersection_update', 'isdisjoint', 'issubset', 'issuperset', 'pop', 'remove', 'symmetric_difference', 'symmetric_difference_update', 'union', 'update']
总结一下我们现在所知道的:可以被for循环的都是可迭代的,要想可迭代,内部必须有一个__iter__方法。
接着分析,__iter__方法做了什么事情呢?
print([1,2].__iter__()) 结果 <list_iterator object at 0x1024784a8>
执行了list([1,2])的__iter__方法,我们好像得到了一个list_iterator,现在我们又得到了一个新名词——iterator。

iterator,这里给我们标出来了,是一个计算机中的专属名词,叫做迭代器。
迭代器协议
既什么叫“可迭代”之后,又一个历史新难题,什么叫“迭代器”?
虽然我们不知道什么叫迭代器,但是我们现在已经有一个迭代器了,这个迭代器是一个列表的迭代器。
我们来看看这个列表的迭代器比起列表来说实现了哪些新方法,这样就能揭开迭代器的神秘面纱了吧?
''' dir([1,2].__iter__())是列表迭代器中实现的所有方法,dir([1,2])是列表中实现的所有方法,都是以列表的形式返回给我们的,为了看的更清楚,我们分别把他们转换成集合,
然后取差集。 ''' #print(dir([1,2].__iter__())) #print(dir([1,2])) print(set(dir([1,2].__iter__()))-set(dir([1,2]))) 结果: {'__length_hint__', '__next__', '__setstate__'}
我们看到在列表迭代器中多了三个方法,那么这三个方法都分别做了什么事呢?
iter_l = [1,2,3,4,5,6].__iter__()
#获取迭代器中元素的长度
print(iter_l.__length_hint__())
#根据索引值指定从哪里开始迭代
print('*',iter_l.__setstate__(4))
#一个一个的取值
print('**',iter_l.__next__())
print('***',iter_l.__next__())
这三个方法中,能让我们一个一个取值的神奇方法是谁?
没错!就是__next__
在for循环中,就是在内部调用了__next__方法才能取到一个一个的值。
那接下来我们就用迭代器的next方法来写一个不依赖for的遍历。
l = [1,2,3,4] l_iter = l.__iter__() item = l_iter.__next__() print(item) item = l_iter.__next__() print(item) item = l_iter.__next__() print(item) item = l_iter.__next__() print(item) item = l_iter.__next__() print(item)
这是一段会报错的代码,如果我们一直取next取到迭代器里已经没有元素了,就会抛出一个异常StopIteration,告诉我们,列表中已经没有有效的元素了。
这个时候,我们就要使用异常处理机制来把这个异常处理掉。
l = [1,2,3,4]
l_iter = l.__iter__()
while True:
try:
item = l_iter.__next__()
print(item)
except StopIteration:
break
那现在我们就使用while循环实现了原本for循环做的事情,我们是从谁那儿获取一个一个的值呀?是不是就是l_iter?好了,这个l_iter就是一个迭代器。
迭代器遵循迭代器协议:必须拥有__iter__方法和__next__方法。
还账:next和iter方法
如此一来,关于迭代器和生成器的方法我们就还清了两个,最后我们来看看range()是个啥。首先,它肯定是一个可迭代的对象,但是它是否是一个迭代器?我们来测试一下
print('__next__' in dir(range(12))) #查看'__next__'是不是在range()方法执行之后内部是否有__next__
print('__iter__' in dir(range(12))) #查看'__next__'是不是在range()方法执行之后内部是否有__next__
from collections import Iterator
print(isinstance(range(100000000),Iterator)) #验证range执行之后得到的结果不是一个迭代器
为什么要有for循环
基于上面讲的列表这一大堆遍历方式,聪明的你立马看除了端倪,于是你不知死活大声喊道,你这不逗我玩呢么,有了下标的访问方式,我可以这样遍历一个列表啊
l=[1,2,3]
index=0
while index < len(l):
print(l[index])
index+=1
#要毛线for循环,要毛线可迭代,要毛线迭代器
没错,序列类型字符串,列表,元组都有下标,你用上述的方式访问,perfect!但是你可曾想过非序列类型像字典,集合,文件对象的感受,所以嘛,年轻人,for循环就是基于迭代器协议提供了一个统一的可以遍历所有对象的方法,即在遍历之前,先调用对象的__iter__方法将其转换成一个迭代器,然后使用迭代器协议去实现循环访问,这样所有的对象就都可以通过for循环来遍历了,而且你看到的效果也确实如此,这就是无所不能的for循环,觉悟吧,年轻人
生成器
初识生成器
我们知道的迭代器有两种:一种是调用方法直接返回的,一种是可迭代对象通过执行iter方法得到的,迭代器有的好处是可以节省内存。
如果在某些情况下,我们也需要节省内存,就只能自己写。我们自己写的这个能实现迭代器功能的东西就叫生成器。
Python中提供的生成器:
1.生成器函数:常规函数定义,但是,使用yield语句而不是return语句返回结果。yield语句一次返回一个结果,在每个结果中间,挂起函数的状态,以便下次重它离开的地方继续执行
2.生成器表达式:类似于列表推导,但是,生成器返回按需产生结果的一个对象,而不是一次构建一个结果列表
生成器Generator:
本质:迭代器(所以自带了__iter__方法和__next__方法,不需要我们去实现)
特点:惰性运算,开发者自定义
生成器函数
一个包含yield关键字的函数就是一个生成器函数。yield可以为我们从函数中返回值,但是yield又不同于return,return的执行意味着程序的结束,调用生成器函数不会得到返回的具体的值,而是得到一个可迭代的对象。每一次获取这个可迭代对象的值,就能推动函数的执行,获取新的返回值。直到函数执行结束。
import time
def genrator_fun1():
a = 1
print('现在定义了a变量')
yield a
b = 2
print('现在又定义了b变量')
yield b
g1 = genrator_fun1()
print('g1 : ',g1) #打印g1可以发现g1就是一个生成器
print('-'*20) #我是华丽的分割线
print(next(g1))
time.sleep(1) #sleep一秒看清执行过程
print(next(g1))
生成器有什么好处呢?就是不会一下子在内存中生成太多数据
假如我想让工厂给学生做校服,生产2000000件衣服,我和工厂一说,工厂应该是先答应下来,然后再去生产,我可以一件一件的要,也可以根据学生一批一批的找工厂拿。
而不能是一说要生产2000000件衣服,工厂就先去做生产2000000件衣服,等回来做好了,学生都毕业了。。。
#初识生成器二
def produce():
"""生产衣服"""
for i in range(2000000):
yield "生产了第%s件衣服"%i
product_g = produce()
print(product_g.__next__()) #要一件衣服
print(product_g.__next__()) #再要一件衣服
print(product_g.__next__()) #再要一件衣服
num = 0
for i in product_g: #要一批衣服,比如5件
print(i)
num +=1
if num == 5:
break
#到这里我们找工厂拿了8件衣服,我一共让我的生产函数(也就是produce生成器函数)生产2000000件衣服。
#剩下的还有很多衣服,我们可以一直拿,也可以放着等想拿的时候再拿
更多应用
import time
def tail(filename):
f = open(filename)
f.seek(0, 2) #从文件末尾算起
while True:
line = f.readline() # 读取文件中新的文本行
if not line:
time.sleep(0.1)
continue
yield line
tail_g = tail('tmp')
for line in tail_g:
print(line)
send
def generator():
print(123)
content = yield 1
print('=======',content)
print(456)
yield2
g = generator()
ret = g.__next__()
print('***',ret)
ret = g.send('hello') #send的效果和next一样
print('***',ret)
#send 获取下一个值的效果和next基本一致
#只是在获取下一个值的时候,给上一yield的位置传递一个数据
#使用send的注意事项
# 第一次使用生成器的时候 是用next获取下一个值
# 最后一个yield不能接受外部的值
def averager():
total = 0.0
count = 0
average = None
while True:
term = yield average
total += term
count += 1
average = total/count
g_avg = averager()
next(g_avg)
print(g_avg.send(10))
print(g_avg.send(30))
print(g_avg.send(5))
def init(func): #在调用被装饰生成器函数的时候首先用next激活生成器
def inner(*args,**kwargs):
g = func(*args,**kwargs)
next(g)
return g
return inner
@init
def averager():
total = 0.0
count = 0
average = None
while True:
term = yield average
total += term
count += 1
average = total/count
g_avg = averager()
# next(g_avg) 在装饰器中执行了next方法
print(g_avg.send(10))
print(g_avg.send(30))
print(g_avg.send(5))
yield from
def gen1():
for c in 'AB':
yield c
for i in range(3):
yield i
print(list(gen1()))
def gen2():
yield from 'AB'
yield from range(3)
print(list(gen2()))
列表推导式和生成器表达式
推导式
之前我们已经学习了最简单的列表推导式和生成器表达式。但是除此之外,其实还有字典推导式、集合推导式等等。
下面是一个以列表推导式为例的推导式详细格式,同样适用于其他推导式。
variable = [out_exp_res for out_exp in input_list if out_exp == 2] out_exp_res: 列表生成元素表达式,可以是有返回值的函数。 for out_exp in input_list: 迭代input_list将out_exp传入out_exp_res表达式中。 if out_exp == 2: 根据条件过滤哪些值可以。
列表推导式
例一:30以内所有能被3整除的数
multiples = [i for i in range(30) if i % 3 is 0] print(multiples) # Output: [0, 3, 6, 9, 12, 15, 18, 21, 24, 27]
print ( [num for num in range(1,30) if num%3 ==0 ])
例二:30以内所有能被3整除的数的平方
def squared(x):
return x*x
multiples = [squared(i) for i in range(30) if i % 3 is 0]
print(multiples)
print ( [num**2 for num in range(1,30) if num%3 ==0 ])
例三:找到嵌套列表中名字含有两个‘e’的所有名字
names = [['Tom', 'Billy', 'Jefferson', 'Andrew', 'Wesley', 'Steven', 'Joe'],
['Alice', 'Jill', 'Ana', 'Wendy', 'Jennifer', 'Sherry', 'Eva']]
print([name for lst in names for name in lst if name.count('e') >= 2]) # 注意遍历顺序,这是实现的关键
字典推导式
例一:将一个字典的key和value对调
mcase = {'a': 10, 'b': 34}
mcase_frequency = {mcase[k]: k for k in mcase}
print(mcase_frequency)
例二:合并大小写对应的value值,将k统一成小写
mcase = {'a': 10, 'b': 34, 'A': 7, 'Z': 3}
mcase_frequency = {k.lower(): mcase.get(k.lower(), 0) + mcase.get(k.upper(), 0) for k in mcase.keys()}
print(mcase_frequency)
集合推导式
例:计算列表中每个值的平方,自带去重功能
squared = {x**2 for x in [1, -1, 2]}
print(squared)
# Output: set([1, 4])
练习题:
例1: 过滤掉长度小于3的字符串列表,并将剩下的转换成大写字母
例2: 求(x,y)其中x是0-5之间的偶数,y是0-5之间的奇数组成的元祖列表
例3: 求M中3,6,9组成的列表M = [[1,2,3],[4,5,6],[7,8,9]]
生成器表达式
#老男孩由于峰哥的强势加盟很快走上了上市之路,alex思来想去决定下几个鸡蛋来报答峰哥
egg_list=['鸡蛋%s' %i for i in range(10)] #列表解析
#峰哥瞅着alex下的一筐鸡蛋,捂住了鼻子,说了句:哥,你还是给我只母鸡吧,我自己回家下
laomuji=('鸡蛋%s' %i for i in range(10))#生成器表达式
print(laomuji)
print(next(laomuji)) #next本质就是调用__next__
print(laomuji.__next__())
print(next(laomuji))
总结:
1.把列表解析的[]换成()得到的就是生成器表达式
2.列表解析与生成器表达式都是一种便利的编程方式,只不过生成器表达式更节省内存
3.Python不但使用迭代器协议,让for循环变得更加通用。大部分内置函数,也是使用迭代器协议访问对象的。例如, sum函数是Python的内置函数,该函数使用迭代器协议访问对象,而生成器实现了迭代器协议,所以,我们可以直接这样计算一系列值的和:
sum(x ** 2 for x in range(4))
而不用多此一举的先构造一个列表:
sum([x ** 2 for x in range(4)])
更多精彩请见——迭代器生成器专题:http://www.cnblogs.com/Eva-J/articles/7276796.html
本章小结
可迭代对象:
拥有__iter__方法
特点:惰性运算
例如:range(),str,list,tuple,dict,set
迭代器Iterator:
拥有__iter__方法和__next__方法
例如:iter(range()),iter(str),iter(list),iter(tuple),iter(dict),iter(set),reversed(list_o),map(func,list_o),filter(func,list_o),file_o
生成器Generator:
本质:迭代器,所以拥有__iter__方法和__next__方法
特点:惰性运算,开发者自定义
使用生成器的优点:
1.延迟计算,一次返回一个结果。也就是说,它不会一次生成所有的结果,这对于大数据量处理,将会非常有用。
2.提高代码可读性
#列表解析 sum([i for i in range(100000000)])#内存占用大,机器容易卡死 #生成器表达式 sum(i for i in range(100000000))#几乎不占内存
生成器相关的面试题
生成器在编程中发生了很多的作用,善用生成器可以帮助我们解决很多复杂的问题
除此之外,生成器也是面试题中的重点,在完成一些功能之外,人们也想出了很多魔性的面试题。
接下来我们就来看一看~
def demo():
for i in range(4):
yield i
g=demo()
g1=(i for i in g)
g2=(i for i in g1)
print(list(g1))#g1去找g取值,g再去找生成器,生成器取值range(4)得到0 1 2 3 然后打印到g1中。
print(list(g2))#g2这时候去打印,生成器的值已经被g1取走了,所以他啥也返回不了是个空。
def add(n,i):
return n+i
def test():
for i in range(4):
yield i
g=test()
for n in [1,10]:
g=(add(n,i) for i in g)
print(list(g))
#得到结果是[20,21,22,23] 为啥是个这结果
#上面的g是不是等于0,1,2,3 i 又等于g n等于[1,10] 最简单的记法, 上面的写法他只会打印出最有一个结果,10 是不是列表的第二个数,那就用列表位置数乘数值加i。
#最终等于10*2+i(0,1,2,3)
import os def init(func): def wrapper(*args,**kwargs): g=func(*args,**kwargs) next(g) return g return wrapper @init def list_files(target): while 1: dir_to_search=yield for top_dir,dir,files in os.walk(dir_to_search): for file in files: target.send(os.path.join(top_dir,file)) @init def opener(target): while 1: file=yield fn=open(file) target.send((file,fn)) @init def cat(target): while 1: file,fn=yield for line in fn: target.send((file,line)) @init def grep(pattern,target): while 1: file,line=yield if pattern in line: target.send(file) @init def printer(): while 1: file=yield if file: print(file) g=list_files(opener(cat(grep('python',printer())))) g.send('/test1') 协程应用:grep -rl /dir
内置函数和匿名函数
在讲新知识之前,我们先来复习复习函数的基础知识。
问:函数怎么调用?
函数名()
如果你们这么说。。。那你们就对了!好了记住这个事儿别给忘记了,咱们继续谈下一话题。。。
来你们在自己的环境里打印一下自己的名字。
你们是怎么打的呀?
是不是print('xxx'),好了,现在你们结合我刚刚说的函数的调用方法,你有没有什么发现?
我们就猜,print有没有可能是一个函数?
但是没有人实现它啊。。。它怎么就能用了呢?
早在我们“初识函数”的时候是不是就是用len()引出的?
那现在我们也知道len()也是一个函数,也没人实现,它好像就自己能用了。。。
之前老师给你讲你可以这样用你就用了,那你有没有想过像这样直接拿来就能用的函数到底有多少?
内置函数
接下来,我们就一起来看看python里的内置函数。截止到python版本3.6.2,现在python一共为我们提供了68个内置函数。它们就是python提供给你直接可以拿来使用的所有函数。这些函数有些我们已经用过了,有些我们还没用到过,还有一些是被封印了,必须等我们学了新知识才能解开封印的。那今天我们就一起来认识一下python的内置函数。这么多函数,我们该从何学起呢?
上面就是内置函数的表,68个函数都在这儿了。这个表的顺序是按照首字母的排列顺序来的,你会发现都混乱的堆在一起。比如,oct和bin和hex都是做进制换算的,但是却被写在了三个地方。。。这样非常不利于大家归纳和学习。那我把这些函数分成了6大类。你看下面这张图,你猜咱们今天会学哪几大类呀?

我猜你们都猜对了。我们今天就要学习用粉红色标注出来的这四大块——56个方法。还有12个方法欠着怎么办呢?我们讲完面向对象这剩下的12个会在两周之内陆续还给你们的,我保证(认真脸)。那这样,我们今天就主要关注我们要学习的这56个方法。
那要学的一共4块,咱们从哪儿开始学起呢?
作用域相关

基于字典的形式获取局部变量和全局变量
globals()——获取全局变量的字典
locals()——获取执行本方法所在命名空间内的局部变量的字典
其他

字符串类型代码的执行
http://www.cnblogs.com/Eva-J/articles/7266087.html
输入输出相关:
input() 输入
input的用法
s = input("请输入内容 : ") #输入的内容赋值给s变量 print(s) #输入什么打印什么。数据类型是str
print() 输出
print源码剖析
def print(self, *args, sep=' ', end='\n', file=None): # known special case of print """ print(value, ..., sep=' ', end='\n', file=sys.stdout, flush=False) file: 默认是输出到屏幕,如果设置为文件句柄,输出到文件 sep: 打印多个值之间的分隔符,默认为空格 end: 每一次打印的结尾,默认为换行符 flush: 立即把内容输出到流文件,不作缓存 """
file关键字的说明
f = open('tmp_file','w') print(123,456,sep=',',file = f,flush=True)
打印进度条
import time for i in range(0,101,2): time.sleep(0.1) char_num = i//2 #打印多少个'*' per_str = '\r%s%% : %s\n' % (i, '*' * char_num) if i == 100 else '\r%s%% : %s'%(i,'*'*char_num) print(per_str,end='', flush=True) #小越越 : \r 可以把光标移动到行首但不换行
数据类型相关:
type(o) 返回变量o的数据类型
内存相关:
id(o) o是参数,返回一个变量的内存地址
hash(o) o是参数,返回一个可hash变量的哈希值,不可hash的变量被hash之后会报错。
t = (1,2,3) l = [1,2,3] print(hash(t)) #可hash print(hash(l)) #会报错 ''' 结果: TypeError: unhashable type: 'list' '''
hash函数会根据一个内部的算法对当前可hash变量进行处理,返回一个int数字。
*每一次执行程序,内容相同的变量hash值在这一次执行过程中不会发生改变。
文件操作相关
open() 打开一个文件,返回一个文件操作符(文件句柄)
操作文件的模式有r,w,a,r+,w+,a+ 共6种,每一种方式都可以用二进制的形式操作(rb,wb,ab,rb+,wb+,ab+)
可以用encoding指定编码.
模块操作相关
__import__导入一个模块
import time
os = __import__('os')
print(os.path.abspath('.'))
帮助方法
在控制台执行help()进入帮助模式。可以随意输入变量或者变量的类型。输入q退出
或者直接执行help(o),o是参数,查看和变量o有关的操作。。。
和调用相关
callable(o),o是参数,看这个变量是不是可调用。
如果o是一个函数名,就会返回True
def func():pass print(callable(func)) #参数是函数名,可调用,返回True print(callable(123)) #参数是数字,不可调用,返回False
查看参数所属类型的所有内置方法
dir() 默认查看全局空间内的属性,也接受一个参数,查看这个参数内的方法或变量
print(dir(list)) #查看列表的内置方法 print(dir(int)) #查看整数的内置方法
和数字相关

数字——数据类型相关:bool,int,float,complex
数字——进制转换相关:bin,oct,hex
数字——数学运算:abs,divmod,min,max,sum,round,pow
和数据结构相关

序列——列表和元组相关的:list和tuple
序列——字符串相关的:str,format,bytes,bytearry,memoryview,ord,chr,ascii,repr
ret = bytearray('alex',encoding='utf-8')
print(id(ret))
print(ret[0])
ret[0] = 65
print(ret)
print(id(ret))
ret = memoryview(bytes('你好',encoding='utf-8'))
print(len(ret))
print(bytes(ret[:3]).decode('utf-8'))
print(bytes(ret[3:]).decode('utf-8'))
序列:reversed,slice
l = (1,2,23,213,5612,342,43) print(l) print(list(reversed(l)))
l = (1,2,23,213,5612,342,43) sli = slice(1,5,2) print(l[sli])
数据集合——字典和集合:dict,set,frozenset
数据集合:len,sorted,enumerate,all,any,zip,filter,map
filter和map:http://www.cnblogs.com/Eva-J/articles/7266192.html
sorted方法:http://www.cnblogs.com/Eva-J/articles/7265992.html
匿名函数
匿名函数:为了解决那些功能很简单的需求而设计的一句话函数
#这段代码
def calc(n):
return n**n
print(calc(10))
#换成匿名函数
calc = lambda n:n**n
print(calc(10))

上面是我们对calc这个匿名函数的分析,下面给出了一个关于匿名函数格式的说明
函数名 = lambda 参数 :返回值 #参数可以有多个,用逗号隔开 #匿名函数不管逻辑多复杂,只能写一行,且逻辑执行结束后的内容就是返回值 #返回值和正常的函数一样可以是任意数据类型
我们可以看出,匿名函数并不是真的不能有名字。
匿名函数的调用和正常的调用也没有什么分别。 就是 函数名(参数) 就可以了~~~
练一练:
请把以下函数变成匿名函数
def add(x,y):
return x+y
上面是匿名函数的函数用法。除此之外,匿名函数也不是浪得虚名,它真的可以匿名。在和其他功能函数合作的时候
l=[3,2,100,999,213,1111,31121,333]
print(max(l))
dic={'k1':10,'k2':100,'k3':30}
print(max(dic))
print(dic[max(dic,key=lambda k:dic[k])])
res = map(lambda x:x**2,[1,5,7,4,8])
for i in res:
print(i)
输出
1
25
49
16
64
res = filter(lambda x:x>10,[5,8,11,9,15])
for i in res:
print(i)
输出
11
15
面试题练一练
现有两个元组(('a'),('b')),(('c'),('d')),请使用python中匿名函数生成列表[{'a':'c'},{'b':'d'}]
#答案一
test = lambda t1,t2 :[{i:j} for i,j in zip(t1,t2)]
print(test(t1,t2))
#答案二
print(list(map(lambda t:{t[0]:t[1]},zip(t1,t2))))
#还可以这样写
print([{i:j} for i,j in zip(t1,t2)])
1.下面程序的输出结果是:
d = lambda p:p*2
t = lambda p:p*3
x = 2
x = d(x)
x = t(x)
x = d(x)
print x
2.现有两元组(('a'),('b')),(('c'),('d')),请使用python中匿名函数生成列表[{'a':'c'},{'b':'d'}]
3.以下代码的输出是什么?请给出答案并解释。
def multipliers():
return [lambda x:i*x for i in range(4)]
print([m(2) for m in multipliers()])
请修改multipliers的定义来产生期望的结果。
本章小结
说学习内置函数,不如说整理自己的知识体系。其实整理这些内置函数的过程也是在整理自己的知识体系。
我们讲课的时候会归类:常用或者不常用,主要还是根据场景而言。
一个优秀的程序员就应该是在该用这个方法的时候信手拈来,把每一个内置的函数都用的恰到好处。
要想做到这一点,至少要先了解,才能在需要的时候想起,进而将它用在该用的地方。
但是在这里,我还是以自己的一点经验之谈,把几个平时工作中相对更常用的方法推荐一下,请务必重点掌握:
其他:input,print,type,hash,open,import,dir
str类型代码执行:eval,exec
数字:bool,int,float,abs,divmod,min,max,sum,round,pow
序列——列表和元组相关的:list和tuple
序列——字符串相关的:str,bytes,repr
序列:reversed,slice
数据集合——字典和集合:dict,set,frozenset
数据集合:len,sorted,enumerate,zip,filter,map
参考文档:
https://docs.python.org/3/library/functions.html#object
递归函数
在讲今天的内容之前,我们先来讲一个故事,讲的什么呢?从前有座山,山里有座庙,庙里有个老和尚讲故事,讲的什么呢?从前有座山,山里有座庙,庙里有个老和尚讲故事,讲的什么呢?从前有座山,山里有座庙,庙里有个老和尚讲故事,讲的什么呢?从前有座山,山里有座庙,庙里有个老和尚讲故事,讲的什么呢......这个故事你们不喊停我能讲一天!我们说,生活中的例子也能被写成程序,刚刚这个故事,让你们写,你们怎么写呀?
while True:
story = "
从前有个山,山里有座庙,庙里老和尚讲故事,
讲的什么呢?
"
print(story)
你肯定是要这么写的,但是,现在我们已经学了函数了,什么东西都要放到函数里去调用、执行。于是你肯定会说,我就这么写:
def story():
s = """
从前有个山,山里有座庙,庙里老和尚讲故事,
讲的什么呢?
"""
print(s)
while True:
story()
但是大家来看看,我是怎么写的!
def story():
s = """
从前有个山,山里有座庙,庙里老和尚讲故事,
讲的什么呢?
"""
print(s)
story()
story()
先不管函数最后的报错,除了报错之外,我们能看的出来,这一段代码和上面的代码执行效果是一样的。
初识递归
递归的定义——在一个函数里再调用这个函数本身
现在我们已经大概知道刚刚讲的story函数做了什么,就是在一个函数里再调用这个函数本身,这种魔性的使用函数的方式就叫做递归。
刚刚我们就已经写了一个最简单的递归函数。
递归的最大深度——997
正如你们刚刚看到的,递归函数如果不受到外力的阻止会一直执行下去。但是我们之前已经说过关于函数调用的问题,每一次函数调用都会产生一个属于它自己的名称空间,如果一直调用下去,就会造成名称空间占用太多内存的问题,于是python为了杜绝此类现象,强制的将递归层数控制在了997(只要997!你买不了吃亏,买不了上当...).
拿什么来证明这个“997理论”呢?这里我们可以做一个实验:
def foo(n):
print(n)
n += 1
foo(n)
foo(1)
由此我们可以看出,未报错之前能看到的最大数字就是997.当然了,997是python为了我们程序的内存优化所设定的一个默认值,我们当然还可以通过一些手段去修改它:
import sys print(sys.setrecursionlimit(100000))
我们可以通过这种方式来修改递归的最大深度,刚刚我们将python允许的递归深度设置为了10w,至于实际可以达到的深度就取决于计算机的性能了。不过我们还是不推荐修改这个默认的递归深度,因为如果用997层递归都没有解决的问题要么是不适合使用递归来解决要么是你代码写的太烂了~~~
看到这里,你可能会觉得递归也并不是多么好的东西,不如while True好用呢!然而,江湖上流传这这样一句话叫做:人理解循环,神理解递归。所以你可别小看了递归函数,很多人被拦在大神的门槛外这么多年,就是因为没能领悟递归的真谛。而且之后我们学习的很多算法都会和递归有关系。来吧,只有学会了才有资本嫌弃!
再谈递归
这里我们又要举个例子来说明递归能做的事情。
例一:
现在你们问我,alex老师多大了?我说我不告诉你,但alex比 egon 大两岁。
你想知道alex多大,你是不是还得去问egon?egon说,我也不告诉你,但我比武sir大两岁。
你又问武sir,武sir也不告诉你,他说他比金鑫大两岁。
那你问金鑫,金鑫告诉你,他40了。。。
这个时候你是不是就知道了?alex多大?
1 金鑫 40
2 武sir 42
3 egon 44
4 alex 46
首先,你是不是问alex的年龄,结果又找到egon、武sir、金鑫,你挨个儿问过去,一直到拿到一个确切的答案,然后顺着这条线再找回来,才得到最终alex的年龄。这个过程已经非常接近递归的思想。我们就来具体的我分析一下,这几个人之间的规律。你为什么能知道的?
age(4) = age(3) + 2 age(3) = age(2) + 2 age(2) = age(1) + 2 age(1) = 40
那这样的情况下,我们的函数应该怎么写呢?
def age(n):
if n == 1:
return 40
else:
return age(n-1)+2
print(age(4))
递归函数与三级菜单
menu = {
'北京': {'海淀': {'五道口': {'soho': {},'网易': {},},'中关村': {'爱奇艺': {},'汽车之家': {},},},},
'上海': {'闵行': {"人民广场": {'炸鸡店': {}}},'闸北': {'火车战': {'携程': {}}},'浦东': {},},
'山东': {'火车战': {'携程': {}}},
}
def threeLM(dic):
while True:
for k in dic.keys():print(k)
key = input('input>>').strip()
if key == 'b' or key == 'q':return
elif key in dic.keys() and dic[key]:
print(dic[key])
ret = threeLM(dic[key])
if ret == 'q': return
threeLM(menu)
还记得之前写过的三级菜单作业么?现在咱们用递归来写一下~
l = [menu]
while l:
for key in l[-1]:print(key)
k = input('input>>').strip() # 北京
if k in l[-1].keys() and l[-1][k]:l.append(l[-1][k])
elif k == 'b':l.pop()
elif k == 'q':break
二分查找算法
如果有这样一个列表,让你从这个列表中找到66的位置,你要怎么做?
l = [2,3,5,10,15,16,18,22,26,30,32,35,41,42,43,55,56,66,67,69,72,76,82,83,88]
你说,so easy!
l.index(66)...
我们之所以用index方法可以找到,是因为python帮我们实现了查找方法。如果,index方法不给你用了。。。你还能找到这个66么?
l = [2,3,5,10,15,16,18,22,26,30,32,35,41,42,43,55,56,66,67,69,72,76,82,83,88]
i = 0
for num in l:
if num == 66:
print(i)
i+=1
上面这个方法就实现了从一个列表中找到66所在的位置了。
但我们现在是怎么找到这个数的呀?是不是循环这个列表,一个一个的找的呀?假如我们这个列表特别长,里面好好几十万个数,那我们找一个数如果运气不好的话是不是要对比十几万次?这样效率太低了,我们得想一个新办法。
二分查找算法
l = [2,3,5,10,15,16,18,22,26,30,32,35,41,42,43,55,56,66,67,69,72,76,82,83,88]
你观察这个列表,这是不是一个从小到大排序的有序列表呀?
如果这样,假如我要找的数比列表中间的数还大,是不是我直接在列表的后半边找就行了?

这就是二分查找算法!
那么落实到代码上我们应该怎么实现呢?
简单版二分法
l = [2,3,5,10,15,16,18,22,26,30,32,35,41,42,43,55,56,66,67,69,72,76,82,83,88]
def func(l,aim):
mid = (len(l)-1)//2
if l:
if aim > l[mid]:
func(l[mid+1:],aim)
elif aim < l[mid]:
func(l[:mid],aim)
elif aim == l[mid]:
print("bingo",mid)
else:
print('找不到')
func(l,66)
func(l,6)
升级版二分法
def search(num,l,start=None,end=None):
start = start if start else 0
end = end if end is None else len(l) - 1
mid = (end - start)//2 + start
if start > end:
return None
elif l[mid] > num :
return search(num,l,start,mid-1)
elif l[mid] < num:
return search(num,l,mid+1,end)
elif l[mid] == num:
return mid

def search(num,l,start=None,end=None):
start = start if start else 0
end = end if end is None else len(l) - 1
mid = (end - start)//2 + start
if start > end:
return None
elif l[mid] > num :
return search(num,l,start,mid-1)
elif l[mid] < num:
return search(num,l,mid+1,end)
elif l[mid] == num:
return mid

















 3642
3642

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









