






 针对大量重复数据排序效率低下的问题,本文介绍了一种双路快速排序算法。该算法通过设置标志数据v,并将等于v的数据分为两部分,有效提高了排序效率。此外,还采用了随机选择元素标志和小规模数据使用插入排序等优化措施。
针对大量重复数据排序效率低下的问题,本文介绍了一种双路快速排序算法。该算法通过设置标志数据v,并将等于v的数据分为两部分,有效提高了排序效率。此外,还采用了随机选择元素标志和小规模数据使用插入排序等优化措施。
双路快速排序算法分析
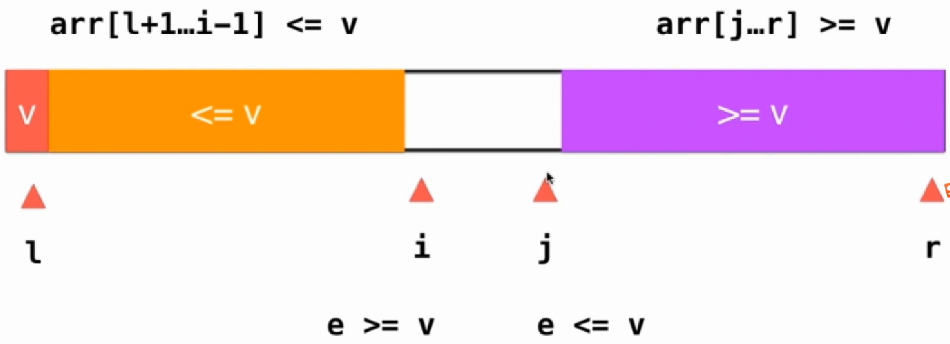
对于具有大量重复数据的排序按照之前的方式性能会很低,现在我们增加两个标志,想办法把大量重复的数据分到两部分,例如设置v作为标志数据,让等于v的数据分为两部分,如下图所示,这样可以避免两边的数据出现一边倒的情况。
根据以上算法的思想,代码修改如下:
//双路快速排序算法:解决具有大量重复源数据排序慢的问题
template<typename T>
int _partition2Ways(T arr[], int l, int r)
{
//优化点2:通过随机选择元素标志,防止对几乎有序的数据排序慢的问题
srand(time(NULL));
swap(arr[l], arr[rand()%(r-l+1)+l]);
T v = arr[l];
int i = l+1, j = r; //arr[l+1...j] < v ; arr[j+1...r] > v
while(true)
{
while(i <= r && arr[i] < v)
i++;
while(j >= l && arr[j] > v)
j--;
if(i > j)
break;
swap(arr[i], arr[j]);
i++;
j--;
}
swap(arr[l], arr[j]);
return j;
}
template<typename T>
void _quickSort2Ways(T arr[], int l, int r)
{
//优化点1:小规模数据使用插入排序
if(r-l <= 15)
{
insertionSort(arr, l, r);
return;
}
int p = _partition2Ways(arr, l, r); //调用双路快速排序
_quickSort2Ways(arr, l, p-1);
_quickSort2Ways(arr, p+1, r);
}
template<typename T>
void quickSort2Ways(T arr[], int n)
{
srand(time(NULL));
_quickSort2Ways(arr, 0, n-1);
}
经过性能测试,双路排序算法对具有大量重复的数据排序性能很好,但是在此基础上还可以进行优化,请查看三路快速排序算法的实现。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









