






 本文探讨了不同操作系统如Linux和Windows下结构体的内存布局及数据对齐原理,展示了如何计算结构体大小,并解释了对齐策略对结构体大小的影响。
本文探讨了不同操作系统如Linux和Windows下结构体的内存布局及数据对齐原理,展示了如何计算结构体大小,并解释了对齐策略对结构体大小的影响。

彻底搞清计算结构体大小和数据对齐原则
By Qianghaohao
数据对齐:
许多计算机系统对基本数据类型合法地址做出了一些限制,要求某种类型对象的地址必须是
某个值K(通常是2,4或8)的倍数。这种对齐限制简化了形成处理器和存储器系统之间的接口的硬件
设计。例如,假设一个处理器总是从存储器中取出8个字节,则地址必须为8的倍数。如果我们能保
证将所有的double类型数据的地址对齐成8的倍数,那么就可以用一个存储器操作来读或者写值了。
否则,我们可能需要执行两次存储器访问,因为对象可能被分放在两个8字节存储块中。
当数据类型为结构体时,编译器可能需要在结构体字段的分配中插入间隙,以保证每个结构元素都
满足它的对齐要求。而结构本身对它的地址也有一些对齐要求,此时可能需要在结构末尾填充一些
空间,以满足结构体整体的对齐----向结构体元素中最大的元素对齐。稍后会用代码说明!!!
Linux和Microsoft Windows的对齐方式有何不同:
一.Linux的对齐策略:
在Linux中2字节数据类型(例如short)的地址必须是2的倍数,而较大的数据类型(例如int,int *
,float和double)的地址必须是4的倍数。也就是说Linux下要么2字节对齐,要么4字节对齐,没
有其他格式的对齐。
二.Microsoft Windows的对齐策略:
在Windows中对齐要求更严--任何K字节基本对象的地址都必须是K的倍数,K=2,4,或者8.
特别地,double或者long long类型数据的地址应该是8的倍数。可以看出Windows的对齐策略和
Linux还是不同的。稍后用代码说明!!!
接下来用代码和图文说明两者的对齐方式(不同的对齐方式产生的结构体大小不同):
测试代码如下:
/////////////////////////////////////
// filename:DataAlignment
/////////////////////////////////////
#include<stdio.h>
typedef struct
{
char c;
int i[2];
double v;
}S;
int main()
{
printf("size of S = %d\n", sizeof(S));
return 0;
}
一.在红帽Linux i686上编译编译后结构S的布局如下:
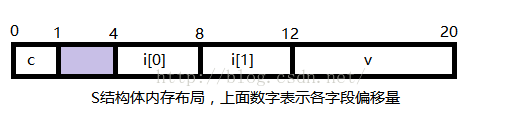
由于要保证结构体每个元素都要数据对齐,因此必须在c和i[0]之间插入3字节的间隙(图中阴影部分为编译器插入的间隙)
使得i[0]和后面的元素的的偏移量都为4的倍数,这样最终S结构大小为20字节。
运行程序结果为:
size of S = 20
二.在Microsoft Windows 上编译后S的内存布局如下:
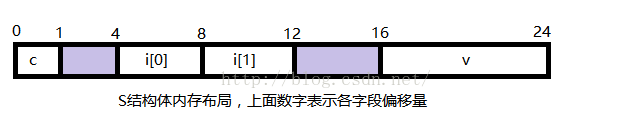
在windows下int类型4个字节,因此int类型要向4字节对齐,double类型8字节,因此要向8字节对齐。因此在
c和i[0]之间插入3字节的间隙(图中阴影部分),使得i[0]的偏移量为4的倍数,同时在i[1]和v之间插入4字节的间隙,
使得v的偏移量为8的倍数。这样最终S结构的大小为24字节。
运行程序结果为:
size of S = 24
从以上对比可以看出Linux下和windows下的对齐策略是不同的,这就导致在两个平台下结构体的大小不同。
现在考虑如下代码:
#include<stdio.h>
typedef struct
{
int i;
int j;
char c;
}S1;
int main()
{
printf("size of S1 = %d\n", sizeof(S1));
return 0;
}
可能很多人认为编译后运行结果为9,以为结构体的每个元素都满足各自的对齐要求。其实不然,别忘了还有要考虑
结构体整体的对齐。假如有如下声明:
S1 d[4];
如果这样分配9个字节,不可能满足d的每个元素的对齐要求,因为这些元素的地址分别为xd,xd+9,xd+18,
xd+27。这样只有第一个元素满足4字节对齐的要求,而其他的元素的地址都不是4的倍数。
因此编译器会在结构体的末尾填充3字节满足结构体整体的对齐要求,填充后的内存布局如下:

这样一来,d的元素的地址分别为xd,xd+12,xd+24,xd+36,满足4字节的整数倍,这样最终S1的大小
为12字节,而不是9字节.
总结:通过代码的对比,可以看出Linx和Windwos的数据对齐有所差异,这就导致
在一些情况下两者平台结构体类型大小的不同。通过以上示例分析我们可以很简单的
计算出在任何平台下结构体的大小。读者可以找相关的练习题继续练习下,验证结果
的正确性。相信仔细阅读本文应该能搞定所有类似的问题!!!
本文参考书籍:
链接:
深入理解计算机系统原书第2版

















 40
40

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









