



 本文深入解析AC3音频解码算法,包括心理声学模型的应用、比特分配原理及其实现过程。介绍AC3如何利用人耳掩蔽效应进行高效压缩,并详细阐述了解码流程中的关键步骤。
本文深入解析AC3音频解码算法,包括心理声学模型的应用、比特分配原理及其实现过程。介绍AC3如何利用人耳掩蔽效应进行高效压缩,并详细阐述了解码流程中的关键步骤。
[原创]桓泽学音频编解码(1):MPEG1 MP3 系统算法分析
[原创]桓泽学音频编解码(2):AC3/Dolby Digital 系统算法分析
[原创]桓泽学音频编解码(4):MP3 和 AAC 中反量化原理,优化设计与参考代码中实现
[原创]桓泽学音频编解码(5):MP3 和 AAC 中IMDCT算法的原理,优化设计与参考代码中实现
[原创]桓泽学音频编解码(6):MP3 无损解码模块算法分析
[原创]桓泽学音频编解码(7):MP3 和 AAC 中huffman解码原理,优化设计与参考代码中实现
[原创]桓泽学音频编解码(8):关于MP3和AAC量化器设计的研究
[原创]桓泽学音频编解码(9):MP3 多相滤波器组算法分析
[原创]桓泽学音频编解码(12):AC3 Mantissa(小数部分)模块算法分析
1 编码概述
在ac3中,对mantissa的编码是使用变长编码。但是他的变长编码不是熵编码,而是通过心理声学模型去计算在以不引人可感知的量化噪声或在规定限度内的量化噪声的现定下每个mantissa可以分配的bit位数。然后由解码器从码流中读出mantissa数据。通常心理声学模型计算可分配位数的过程只在编码器中进行,ac3引入解码器的方式要求解码器和编码器的计算结果都一样。所以为了避免由于计算的类型和位宽导致的计算差异。AC3规定,位分配计算统一使用整数计算和查表的方式实现。
2 解码原理
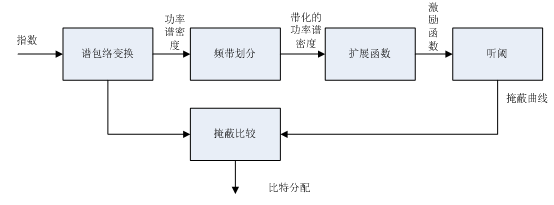
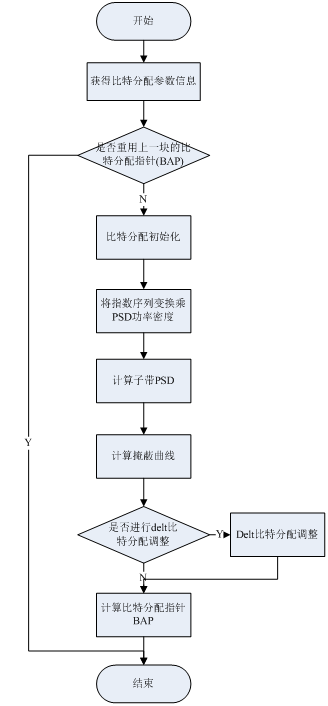
AC-3采用了基于人耳掩蔽效应的失真准则,综合了前向和后向自适应比特分配算法的优点,在一个以后向自适应比特分配为核心的基础之上,提出了新的棍合算法——参数比特分配(Parameter Bit Allocation).因此在AC-3比特流中只需传送一些影响掩蔽曲线的形状、幅度从而影响比特分配的心理声学模型的关键参数,而这些参数所占用的比特远小于总体比特分配信息.这样,在不改变解码设备的情况下,编码器可以通过改变这些参数从而改善系统的性能.因此,AC-3解码器必须根据编码流来产生相应的比特分配信息,并采用编码流传送过来的参数修正比特分配,它不需确定比特分配策略,只须与编码器相同的顺序计算即可。它的步骤如下图所示。
2 算法原理
比特指派对音频信号从掩蔽效应分析它的频谱包络,以确定分配给各频谱系数的尾数所需要的比特数。比特指派包含一个由频率函数表示的人耳听觉的参数模型,用来估算噪声域值。在编码器中,根据输入信号的特性确定听觉模型的各种参数,将模型参数同其它附带信息传送到解码器。解码器先计算出细颗粒均匀频率标度上的输入信号功率谱密度(PSD),再根据传送的模型参数计算出粗颗粒频率标度上的噪声域值,将两者差值用来查比特指派指针(BAP)表格的索引,查表得到比特指派指针信息。以上解码流程在AC3解码程序的比特指派子函数中分为7个子步骤如下:
a. 初始化: 对正在被解码的声道计算出其起始或终止频率。
b. 映射: 将指数解码解出的频率指数映射为13比特带符号的对数功率谱密度函数。
c. PSD积分:将上述每个频率的PSD值在50个频带内分别作积分,计算出每个频带内对应的PSD积分值。
d. 计算激励函数:根据上述每个频带的PSD积分值及码流中发送的人耳听觉模型参数计算出整个频谱的激励函数。
e. 计算掩盖曲线:结合激励函数和听觉域值计算出掩蔽曲线,即每个频率的噪声域值。
f. 增量比特指派:根据码流中的DBA(增量比特指派)信息对上步计算出的约定掩盖曲线以进行调整的方式修改比特分派,从而获得音频质量的改善。
g. 计算比特指派:将掩蔽曲线从第二步计算出的频谱细颗粒度PSD值数组中减去,将其作为查BAP表格的索引,得到指示尾数占用比特数的BAP数组。
算法流程图如下
3 参考代码
3.1 伪代码
Step1:初始化比特流参数
|
|
|
|
| csnroffst | 6bit |
|
| fsnroffst[ch] | 4bit |
|
| cplfsnoffst | 4bit |
|
| lfefsnoffst | 4bit |
|
Step2:由exponent计算法PSD。
把exponent映射到13比特有符号的对数功率谱密度函数PSD,PSD的单位是dB。代码如下
for (bin=start; bin<end; bin++)
{
psd[bin] = (3072 - (exps[bin] << 7));
}
变量属性
|
| I/O | 位宽 | 范围 |
| exps[bin] | I | 5位 | 0~24 |
| psd[bin] | O | 13位 | 0~3072 |
Step3:PSD积分。
每个1/6倍频程的整数频带内对PSD进行积分。积分用对数加实现。对数加用查表实现。查表的地址是2个输入参数的差的绝对值除2。
bndtab[k]:第k带宽中第一个mantissa
bndsz[k]:第k带宽中包含的mantissa的个数
masktab[start]:从mantissa号到对应的1/6倍频程的号的映射
输入:
psd[]:psd值
中间变量:
输出:
bndpsd[]:psd积分值
代码如下
/* 积分 the psd function over each bit allocation band */
j = start;
k = masktab[start];
do
{
lastbin = min(bndtab[k] + bndsz[k], end);
bndpsd[k] = psd[j];
j++;
for (i = j; i < lastbin; i++)
{
bndpsd[k] = logadd(bndpsd[k], psd[j]);
j++;
}
k++;
} while (end > lastbin);
static inline short logadd(short a, short b)
{
short c;
short address;
c = a - b;
address = min((abs(c) >> 1), 255);
if (c >= 0)
return(a + latab[address]);
else
return(b + latab[address]);
}
Step4:计算激励函数。
输入:
bndpsd[]:psd积分值
中间变量:
输出:
代码如下
/* Compute excitation function */
bndstrt = masktab[start];
bndend = masktab[end - 1] + 1;
if (bndstrt == 0) /* For fbw and lfe channels */
{
lowcomp = calc_lowcomp(lowcomp, bndpsd[0], bndpsd[1], 0);
excite[0] = bndpsd[0] - fgain - lowcomp;
lowcomp = calc_lowcomp(lowcomp, bndpsd[1], bndpsd[2], 1);
excite[1] = bndpsd[1] - fgain - lowcomp;
begin = 7 ;
/* Note: Do not call calc_lowcomp() for the last band of the lfe channel, (bin = 6) */
for (bin = 2; bin < 7; bin++)
{
if (!(is_lfe && (bin == 6)))
lowcomp = calc_lowcomp(lowcomp, bndpsd[bin], bndpsd[bin+1], bin);
fastleak = bndpsd[bin] - fgain;
slowleak = bndpsd[bin] - sgain;
excite[bin] = fastleak - lowcomp;
if (!(is_lfe && (bin == 6)))
{
if (bndpsd[bin] <= bndpsd[bin+1])
{
begin = bin + 1 ;
break;
}
}
}
for (bin = begin; bin < min(bndend, 22); bin++)
{
if (!(is_lfe && (bin == 6)))
lowcomp = calc_lowcomp(lowcomp, bndpsd[bin], bndpsd[bin+1], bin);
fastleak -= fdecay ;
fastleak = max(fastleak, bndpsd[bin] - fgain);
slowleak -= sdecay ;
slowleak = max(slowleak, bndpsd[bin] - sgain);
excite[bin] = max(fastleak - lowcomp, slowleak);
}
begin = 22;
}
else /* For coupling channel */
{
begin = bndstrt;
}
for (bin = begin; bin < bndend; bin++)
{
fastleak -= fdecay;
fastleak = max(fastleak, bndpsd[bin] - fgain);
slowleak -= sdecay;
slowleak = max(slowleak, bndpsd[bin] - sgain);
excite[bin] = max(fastleak, slowleak) ;
}
Step5:计算掩蔽曲线。
这一步从激励函数计算掩蔽曲线。其中excite[]为激励函数,mask[]为掩蔽曲线。使用码流中fscod,deltbaie,cpldeltbae,deltbae[ch],cpldeltnseg,cpldeltoffst[seg],cpldeltlen[seg],cpldeltba[seg],deltnseg[ch],deltoffst[ch][seg],deltlen[ch][seg],deltba[ch][seg]变量。
代码如下
输入:
中间变量:
输出:
bndstrt = masktab[start];
bndend = masktab[end - 1] + 1;
/* Compute the masking curve */
for (bin = bndstrt; bin < bndend; bin++)
{
if (bndpsd[bin] < dbknee)
{
excite[bin] += ((dbknee - bndpsd[bin]) >> 2);
}
mask[bin] = max(excite[bin], hth[fscod][bin]);
}
Step6:应用delta比特分配。
代码如下
/* Perform delta bit modulation if necessary */
if ((deltbae == DELTA_BIT_REUSE) || (deltbae == DELTA_BIT_NEW))
{
sint_16 band = 0;
sint_16 seg = 0;
for (seg = 0; seg < deltnseg+1; seg++)
{
band += deltoffst[seg];
if (deltba[seg] >= 4)
{
delta = (deltba[seg] - 3) << 7;
}
else
{
delta = (deltba[seg] - 4) << 7;
}
for (k = 0; k < deltlen[seg]; k++)
{
mask[band] += delta;
band++;
}
}
}
Step7:完成比特分配计算。
计算比特分配指针数组bap[]。在前一步中的snroffset调整极端的掩蔽曲线,把它从微粒psd[]数组中减去,差值右移5位,用阈值切割,然后用作地址差表获得最后地分配。
/* Compute the bit allocation pointer for each bin */
i = start;
j = masktab[start];
do
{
lastbin = min(bndtab[j] + bndsz[j], end);
mask[j] -= snroffset;
mask[j] -= floor;
if (mask[j] < 0)
mask[j] = 0;
mask[j] &= 0x1fe0;
mask[j] += floor;
for (k = i; k < lastbin; k++)
{
address = (psd[i] - mask[j]) >> 5;
address = min(63, max(0, address));
bap[i] = baptab[address];
i++;
}
j++;
} while (end > lastbin);
3.2 C代码
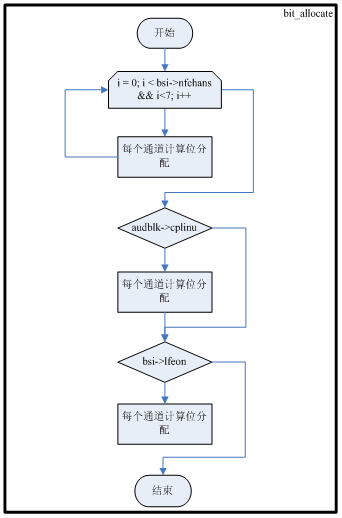
位分配算法在C参考代码中的bit_allocate()函数中实现,代码流程图如下
每个通道内计算位分配依次使用4个函数完成上述的7个步骤,流程图如下
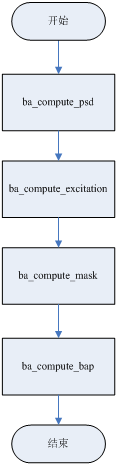
每个函数内部的代码和伪代码几乎一致,所以不再赘述。

















 942
942

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









