






 本文介绍了一个简单的网站文章采集示例,使用request发起HTTP请求获取网页内容,并利用cheerio解析HTML,提取文章标题和简介。该采集器适用于特定格式的文章列表页面。
本文介绍了一个简单的网站文章采集示例,使用request发起HTTP请求获取网页内容,并利用cheerio解析HTML,提取文章标题和简介。该采集器适用于特定格式的文章列表页面。
目的:采集网站文章。
两个依赖项:
request :https://github.com/request/request
cheerio:https://github.com/cheeriojs/cheerio
package.json文件:
{ "name":"zqz", "version":"1.0.1", "private":false, "dependencies":{ "request":"*", "cheerio":"*" } }
cdm中执行:npm install 进行安装依赖的2个包。
app.js文件:
/** * 数据采集 */ //引入需要的包 var request = require('request'); var cheerio = require('cheerio'); //定义常量 var dolphin = 'http://cn.dolphin.com/blog'; //数据请求 function dataRequest(dataUrl) { //发送请求 request({ url : dataUrl, method : 'GET' },function(err, red, body) { //请求到body if(err){ console.log(dataUrl); console.error('[ERROR]Collection' + err); return; } if(dataUrl && dataUrl === dolphin){ dataPraseDolphin(body); } }) } /** * 解析html */ function dataPraseDolphin(body) { var $ = cheerio.load(body); var atricles = $('#content').children('.status-publish'); for(var i = 0;i < atricles.length;i++){ var article = atricles[i]; var $a = $(article).find('.post-title .entry-title a'); var $p = $(article).find('.post-content p'); var $aVal = $($a).text(); var $pVal = $($p).text(); if($p) { console.info('--------------'+ (i+1) +' Chapter------------------'); console.info('标题:' + $aVal); console.info('简介:' + $pVal); console.info('时间:' + new Date) console.info('---------------------------------------------------'); } } } //开始发送请求 并 采集数据 dataRequest(dolphin);
Sublime 中 ctrl+B 执行
结果: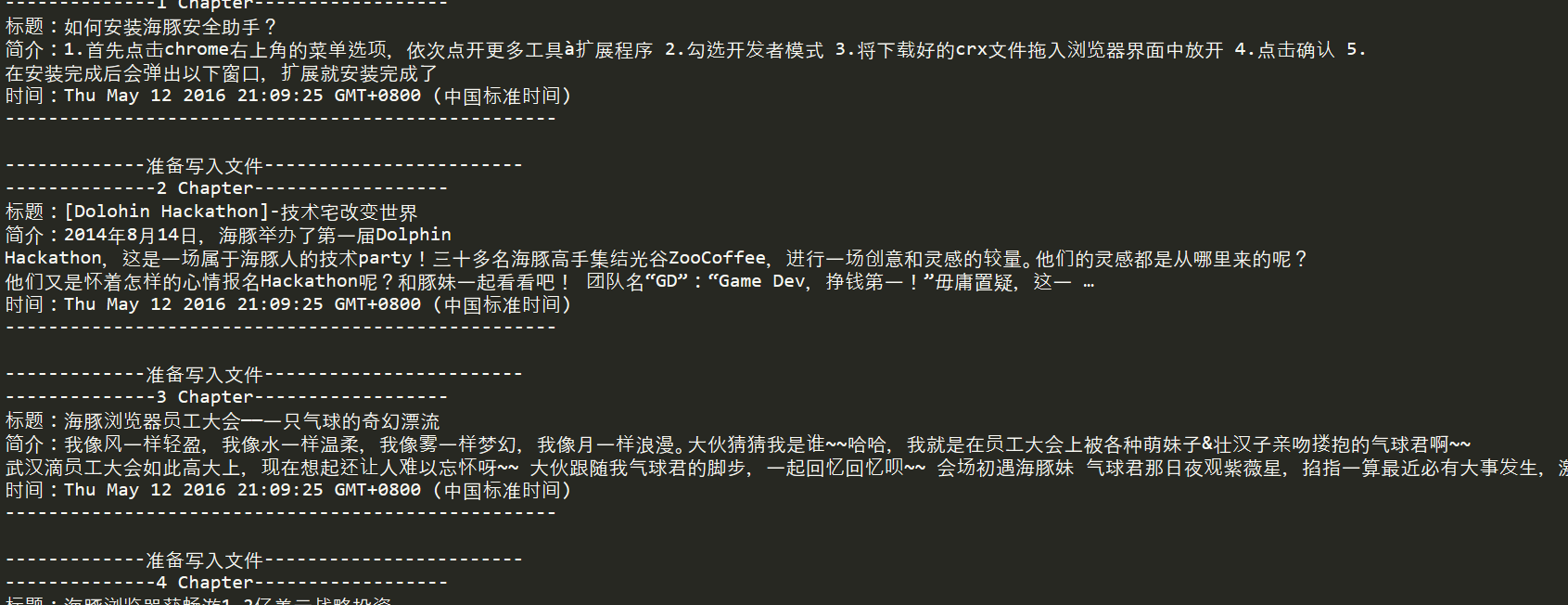


















 1101
1101

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









