






 本文详细介绍Apache Derby数据库在客户机-服务器模式下的启动、配置及使用方法,并提供两个Java程序示例,演示如何通过JDBC访问本地及远程Derby数据库。
本文详细介绍Apache Derby数据库在客户机-服务器模式下的启动、配置及使用方法,并提供两个Java程序示例,演示如何通过JDBC访问本地及远程Derby数据库。

零、回顾
这部分先来回顾一下上一篇博客中的主要内容。上一篇博客中主要简单介绍了Derby数据的历史,特点,安装以及使用的两种模式。这篇文章主要介绍这两种模式中的一种模式
一、启动服务端程序
第一部分主要来启动Derby数据库的服务端程序来接收客户端过来的请求。启动服务端程序有两种情况,一种是本机作为服务端,一种是远程的某台主机作为服务端程序。下面将对这两种情况分别介绍。(说明,我使用的是Linux环境,使用Windodws环境的类似,可自行查阅使用手册)
先来介绍第一种情况,即本机当做服务器端。首先打开一个终端,切换到一个位置。需要特别注意的是这个位置非常重要,它将作为数据库访问时根目录对待。如我现在切换到一个叫Testdata的文件夹下面,那么我之后用于指定数据库路径的根目录即为Testdata,Derby将从Testdata开始递归的查找数据库所在的目录。我下的bin版本的Derby数据库,所以里面有很多编译好的脚本文件可以使用,位置在DERBY_HOME/bin/文件夹下面。该文件夹下的内容如下图:
从上图中可以看出,bin文件大多都是两两对应的,即一个是用于Linux/Unix系统的脚本文件(无文件扩展名),一个是用于Windodws系统下的脚本文件(文件扩展名为.bat)。我这里使用的是Linux系统,但是不会介绍所有的脚本文件,只介绍其中的一部分。
我们现在的目标是把本机当做服务端,并启动服务。Step1:需要做的事情是先把启动服务端需要的jar文件添加到CLASSPATH环境变量中,这里可以用终端执行命令
setNetworkServerCP该脚本会自动帮助把需要的jar文件(derbytools.jar, derbynet.jar)添加到CLASSPATH环境变量中。当然也可以自己手动完成,即执行命令:
export CLASSPATH=$DERBY_HOME/lib/derbytools.jar:$DERBY_HOME\lib\derbynet.jar:接下来就可以启动服务端的数据库程序了。Step2:启动服务端程序,执行命令:
startNetworkServer或者手动开启服务端进程,执行命令:
java -jar derbyrun.jar server start这样我们就可以对从客户端对数据库进行访问了,运行后终端提示内容如下:

接下来介绍第二种情况,即远程主机做为数据库的服务进程。启动需要运行数据库的主机一个终端按照第一种情况的Step1完成配置环境变量CLASSPATH的操作。但是Setp2会有所不同。首先先来解释一些,第一种情况的默认启动的方式,默认启动时数据库服务进程只监听本机客户端发来的请求,拒绝接受其他主机客户端发来的请求,所以对于第二种情况我们不能够使用这种默认的启动服务端的模式。我们使用脚本文件NetworkServerControl。执行命令:
NetworkServerControl start -h MASTER_IP_ADDRESS -p MASTER_PORT_NUMBER或者手动执行命令:
java org.apache.derby.drda.NetworkServerControl start -h MASTER_IP_ADDRESS -p MASTER_PORT_NUMBER上述的MASTER_IP_ADDRESS时主机的ip地址,MASTER_PORT_NUMBER是主机用来监听的端口号,根据自己的需求自行指定。终端出现类似上图的提示即说明服务进程已启动,可以接收来自不同客户端的服务请求了。
二、客户端访问本地服务
启动好本机的服务进程后在打开一个终端。先配置好CLASSPATH的环境变量,输入命令:
setNetworkClientCP或者使用命令:
export CLASSPATH=$DERBY_HOME/lib/derbytools.jar:$DERBY_HOME\lib\ derbyclient.jar:在这里先插一句,Derby提供了3个工具:
- sysinfo:显示你的Java环境信息和Derby的版本信息。
- ij:进行数据库交互,执行SQL脚本,如查询、增删改、创建表等等。
- dblook:可以将全部或者部分数据库的DDL定义导出到控制台或者文件中。(使用时需要指定一下参数,请自行查阅)
从上面三个工具的简单介绍可知,我们要使用的工具是ij,在终端中输入ij或者命令java -jar $DERBY_HOME/lib/derbyrun.jar ij会显示以下信息:
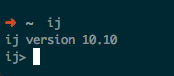
这样我们就可以使用这个工具来链接数据库,并且可以用SQL语句完成数据库的操作了。首先先要链接数据库,输入命令:
connect 'jdbc:derby:myDB;create=true';简单解释一下,connect是连接的命令,前面的jdbc:derby是使用的协议,myDB是数据库的路径和名称,这里需要注意以下,查找数据库路径的位置是以当前启动ij的文件夹作为根目录进行查找。后面的create=true代表了数据库如果不存在就创建。完成这个命令后会发现对应的路径位置上多了一myDB的文件夹,这里面存放的就是数据。另外,需要注意力的是,这里没有指定用户名和密码,默认的用户名和密码是app。
接下来就可以执行SQL语句对当前连接的数据库进行操作了,这里就不在赘述,可以自行查阅SQL的语法规则。另外,ij工具本身还有一些自身的命令,可以输入help命令查看。
三、程序访问本地服务
注意需要选择的Driver为:org.apache.derby.jdbc.ClientDriver即可。下面附上程序:
package triangle23.derby.demo.first;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.ResultSetMetaData;
import java.sql.SQLException;
import java.sql.Statement;
public class DerbyDemo {
private Connection conn = null;
private Statement stmt = null;
public static void main(String[] args) {
String ipAddress = "localhost";
String portNumber = "1527";
String dbPath = "Testdata";
String dbName = "myDB";
String dbURL = "jdbc:derby://" + ipAddress + ":" + portNumber + "/"
+ dbPath + "/" + dbName + ";create=true;";
String tableName = "basicinfo";
String createTableQuery = "create table " + tableName
+ "(id int not null, name varchar(12), cityname varchar(12))";
String selectQuery = "select * from " + tableName;
DerbyDemo dd = new DerbyDemo();
dd.createConnection(dbURL);
dd.createTable(createTableQuery);
dd.insert(tableName, 0, "Trianlge23", "Beijing");
dd.select(selectQuery);
dd.shutdown(dbURL);
}
private void createConnection(String dbURL) {
try {
Class.forName("org.apache.derby.jdbc.ClientDriver").newInstance();
conn = DriverManager.getConnection(dbURL);
} catch (Exception except) {
except.printStackTrace();
}
}
private void createTable(String createTableQuery) {
try {
stmt = conn.createStatement();
stmt.execute(createTableQuery);
stmt.close();
} catch (SQLException sqlExcept) {
sqlExcept.printStackTrace();
}
}
private void insert(String tableName, int id, String Name, String cityName) {
try {
stmt = conn.createStatement();
stmt.execute("insert into " + tableName + " values (" + id + ",'"
+ Name + "','" + cityName + "')");
stmt.close();
} catch (SQLException sqlExcept) {
sqlExcept.printStackTrace();
}
}
private void select(String selectQuery) {
try {
stmt = conn.createStatement();
ResultSet results = stmt.executeQuery(selectQuery);
ResultSetMetaData rsmd = results.getMetaData();
int numberCols = rsmd.getColumnCount();
for (int i = 1; i <= numberCols; i++) {
System.out.print(rsmd.getColumnLabel(i) + "\t\t\t");
}
System.out
.println("\n-------------------------------------------------------------");
while (results.next()) {
int id = results.getInt(1);
String Name = results.getString(2);
String cityName = results.getString(3);
System.out.println(id + "\t\t\t" + Name + "\t\t\t" + cityName);
}
results.close();
stmt.close();
} catch (SQLException sqlExcept) {
sqlExcept.printStackTrace();
}
}
private void shutdown(String dbURL) {
try {
if (stmt != null) {
stmt.close();
}
if (conn != null) {
DriverManager.getConnection(dbURL + "shutdown=true");
conn.close();
}
} catch (SQLException sqlExcept) {
// sqlExcept.printStackTrace();
}
}
}注意到程序中故意注释掉了一行,如果取消注释会报出一个异常java.sql.SQLNonTransientConnectionException。困扰了我好半天,查一下才知道,这个并没有问题,Derby的工作方式就是这样,或者说是Derby的一个bug,详细请参考参考资料4,5
四、客户端访问远程服务
和第二部分客户端访问本地服务类似,先要启动ij工具,之后执行命令
connect 'jdbc:derby://MASTER_IP_ADDRESS:MASTER_PROT_NUMBER/DB_PATH/DB_NAME;create=true';连接上数据库后即可用SQL语句执行命令了。上面的命令中和第二部分类似,需要指出协议,数据库的路径和名字,但是不同的时还需要指定数据库服务进程主机的ip地址和监听端口号。其实第二部分的连接命令是省略的写法,1527是Derby数据库默认指定的端口号,完整的写法如下:
connect 'jdbc:derby://localhost:1527/DB_PATH/DB_NAME;create=true';五、程序访问远程服务
明白了第三部分的程序示例,程序远程访问的示例和气类似,只是把对应的主机ip地址和监听端口号指定好就行了,这里就不举例了。
六、后续工作
这篇博客介绍了Derby数据库作为客户机-服务器(C/S)连接的使用,并给出了两个Java程序使用JDBC连接的例子。后续将继续介绍内嵌模式(Enbedded)的使用。至于关闭数据库的服务进程,很简单,自行查阅一下文档或者根据bin文件夹下的脚本名即可,这里就不在给出。
七、参考资料
- Derby Network Server:http://db.apache.org/derby/papers/DerbyTut/ns_intro.html
- Class NetworkServerControl:
http://db.apache.org/derby/docs/10.0/publishedapi/org/apache/derby/drda/NetworkServerControl.html - ij Basics: http://db.apache.org/derby/papers/DerbyTut/ij_intro.html
- JavaDB/Derby Error 08006:
http://stackoverflow.com/questions/2723622/javadb-derby-error-08006 - Shutting down the system:
http://db.apache.org/derby/docs/10.5/devguide/tdevdvlp20349.html - Creating a Java application to access a Derby database:
http://db.apache.org/derby/integrate/plugin_help/derby_app.html

















 2647
2647

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









