 Hadoop集群搭建指南
Hadoop集群搭建指南




 本文详细介绍了如何在本地环境中搭建Hadoop集群,包括关闭防火墙、安装配置JDK、SSH免密登录、hosts配置、Hadoop下载与解压、配置文件修改、环境变量设置、集群格式化与启动等步骤。
本文详细介绍了如何在本地环境中搭建Hadoop集群,包括关闭防火墙、安装配置JDK、SSH免密登录、hosts配置、Hadoop下载与解压、配置文件修改、环境变量设置、集群格式化与启动等步骤。

准备工作:
一、先关闭防火墙
systemctl stop firewalld
二、安装jdk
参考:https://my.oschina.net/u/3746234/blog/3006621
三、配置ssh免密登录
参考:https://my.oschina.net/u/3746234/blog/3006580
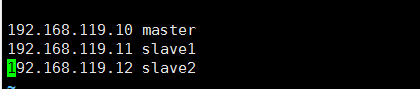
四、配置hosts
vim /etc/hosts
正式开始:
一、下载hadoop
wget http://mirrors.shu.edu.cn/apache/hadoop/common/hadoop-2.6.5/hadoop-2.6.5.tar.gz
二、解压
tar -zxvf hadoop-2.6.5.tar.gz
三、进入hadoop安装目录下的配置文件目录
cd hadoop-2.6.5/etc/hadoop/

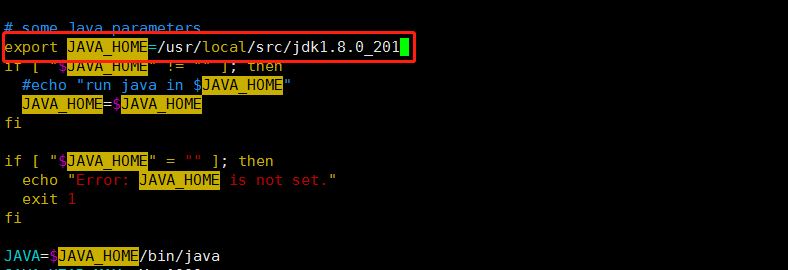
四、修改hadoop-env.sh文件,配置jdk路径
vim hadoop-env.sh

五、修改yarn-env-sh文件,配置jdk路径
vim yarn-env.sh
六、修改slaves文件,配置从节点
vim slaves

七、修改core-site.xml文件
vim core-site.xml
<property>
<name>fs.defaultFS</name>
<value>hdfs://192.168.119.10:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/src/hadoop-2.6.5/tmp/</value>
</property>

八、修改hdfs-site.xml文件
vim hdfs-site.xml
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>master:9001</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/src/hadoop-2.6.5/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/src/hadoop-2.6.5/dfs/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>

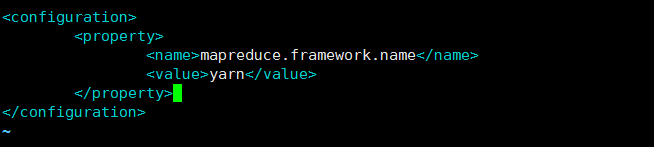
九、配置mapred-site.xml文件
复制出一个文件(原本没有mapred-site.xml)
cp mapred-site.xml.template mapred-site.xml
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>

修改vim mapred-site.xml
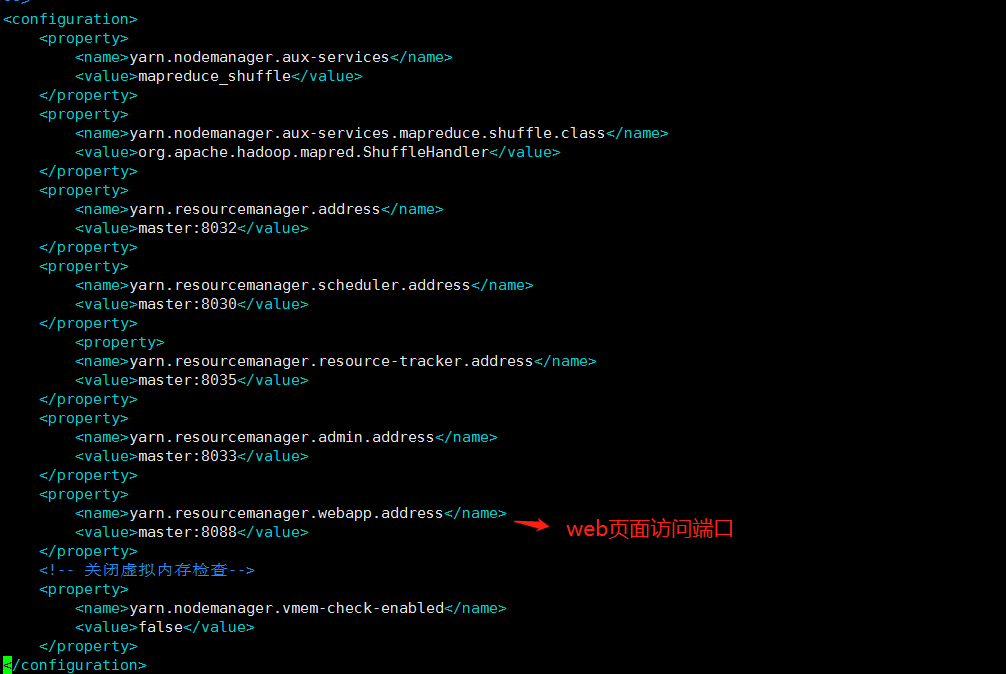
十、修改yarn-site.xml文件
vim yarn-site.xml
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>master:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:8035</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>master:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master:8088</value>
</property>
<!-- 关闭虚拟内存检查-->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
十一、创建临时目录和文件目录
mkdir /usr/local/src/hadoop-2.6.5/tmp
mkdir -p /usr/local/src/hadoop-2.6.5/dfs/name
mkdir -p /usr/local/src/hadoop-2.6.5/dfs/data
十二、配置环境变量
vim ~/.bashrc
HADOOP_HOME=/usr/local/src/hadoop-2.6.5
export PATH=$PATH:$HADOOP_HOME/bin

刷新环境变量:source ~/.bashrc
十三、拷贝hadoop安装包到各个子节点
scp -r /usr/local/src/hadoop-2.6.5 root@slave1:/usr/local/src/hadoop-2.6.5
scp -r /usr/local/src/hadoop-2.6.5 root@slave2:/usr/local/src/hadoop-2.6.5
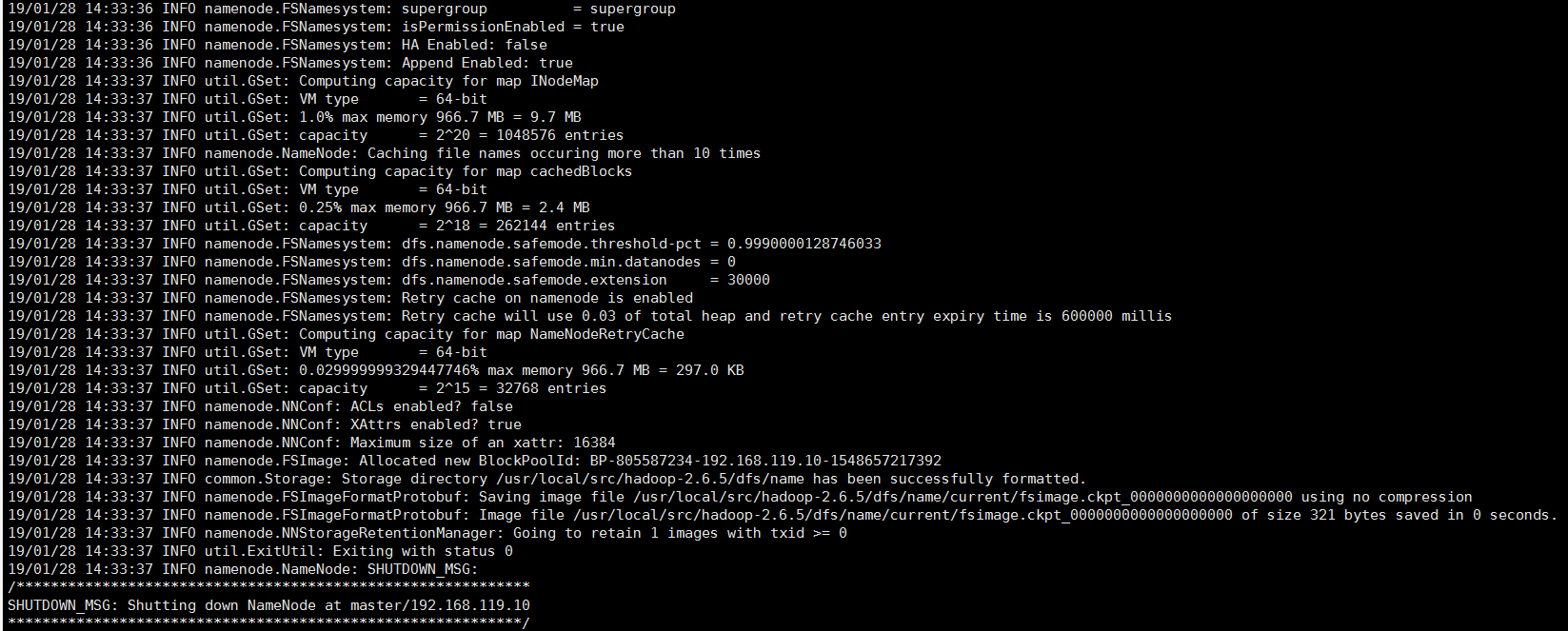
十四、第一次启动集群前,要先格式化一下(个人理解是将本地文件系统装成hdfs文件系统)
hadoop namenode -format
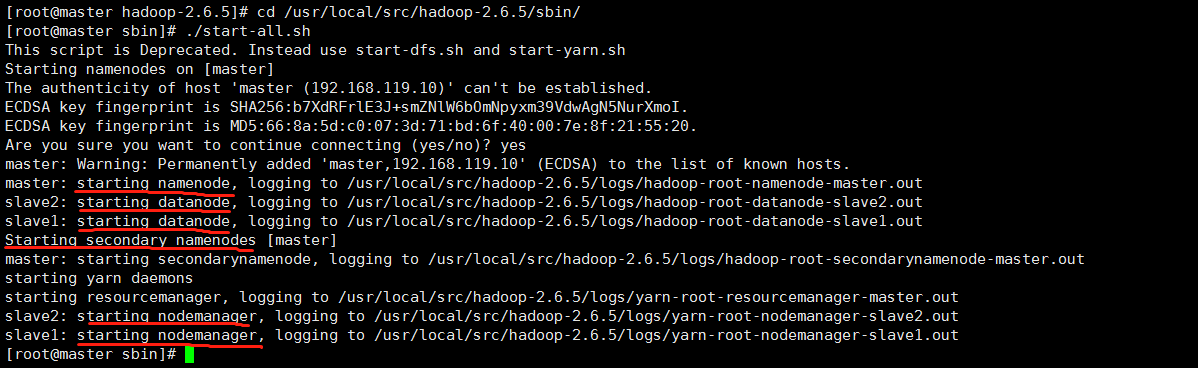
十五、启动hadoop
进入可执行命令文件夹:cd /usr/local/src/hadoop-2.6.5/sbin/
启动:./start-all.sh
十六、测试:查看集群状态
主节点: 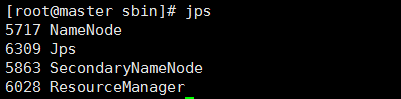
各个子节点:
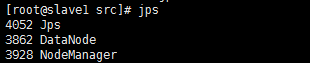
十七、测试:查看web监控页面
十八、测试:上传和查看个文件试试

十九、成功!!!

















 2245
2245

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









