 解决MySQL唯一约束添加失败
解决MySQL唯一约束添加失败





问题描述:线上数据库表字段需要添加一个唯一约束(之前该字段有索引)。添加的时候报错(下文操作均为测试环境问题复现)
root@localhost:mysql.sock 17:42:18 [practice]>drop index idx_name on test;
Query OK, 0 rows affected (0.02 sec)
Records: 0 Duplicates: 0 Warnings: 0
root@localhost:mysql.sock 17:44:30 [practice]>alter table test add unique idx_name(name);
ERROR 1062 (23000): Duplicate entry 'eeee' for key 'idx_name'
root@localhost:mysql.sock 17:47:55 [practice]>delete from test where id in (SELECT t1.id from test as t1,test as t2 where t1.name = t2.name and t1.id !=t2.id);
ERROR 1093 (HY000): You can't specify target table 'test' for update in FROM clause
root@localhost:mysql.sock 18:04:14 [practice]>delete from test where id in (SELECT t1.id from (select * from test as tmp) as t1,(select * from test as tmp) as t2 where t1.name = t2.name and t1.id !=t2.id);
Query OK, 5 rows affected (0.01 sec)纳尼?查下官方文档吧,看来是不支持这样搞(我的版本是5.7.14)
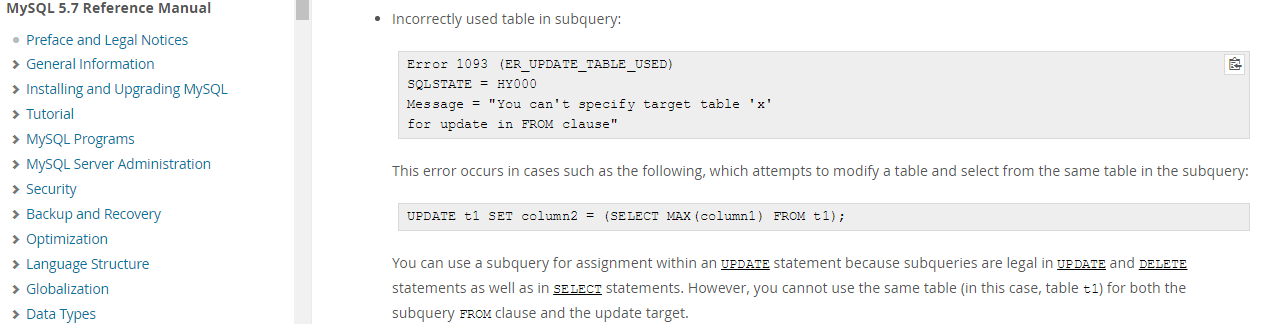
解决办法:
方案一:这个命令在MySQL5.1.37之前是可以的,在5.1.48以后就行不通了,它会删除重复数据,建立唯一索引。另外这个方式在percona server中也是行不通的(用不了)
alter ignore table test addunique idx_name (name);方案二:重建表
创建一个中间表,对数据去重插入中间表,再drop原表,rename中间表
root@localhost:mysql.sock 18:37:56 [practice]>insert into uniq_test select * from test group by name;
Query OK, 6 rows affected (0.01 sec)
Records: 6 Duplicates: 0 Warnings: 0
root@localhost:mysql.sock 18:42:26 [practice]>drop table test;
root@localhost:mysql.sock 18:42:51 [practice]>rename table uniq_test to test;
方案三:利用中间表(推荐)
| tmp_ids | CREATE TABLE `tmp_ids` (
`id` int(11) DEFAULT NULL,
`name` char(20) DEFAULT NULL
) ENGINE=innodb DEFAULT CHARSET=utf8 |
root@localhost:mysql.sock 19:36:02 [practice]>insert into tmp_ids select max(id),name from test group by name having count(*)>1 orderr by null;
Query OK, 1 row affected (0.01 sec)
Records: 1 Duplicates: 0 Warnings: 0
root@localhost:mysql.sock 19:38:07 [practice]>delete a.* from test a,tmp_ids b where b.name=a.name and a.id<b.id;
Query OK, 2 rows affected (0.04 sec)
为了方便大家交流,本人开通了微信公众号,和QQ群291519319。喜欢技术的一起来交流吧


















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









