






 本文深入解析了Elasticsearch中的分词机制,包括内置分析器、分词器及过滤器的工作原理,并通过.NET Nest代码示例展示了如何自定义分词器与过滤器。
本文深入解析了Elasticsearch中的分词机制,包括内置分析器、分词器及过滤器的工作原理,并通过.NET Nest代码示例展示了如何自定义分词器与过滤器。
概念解释:
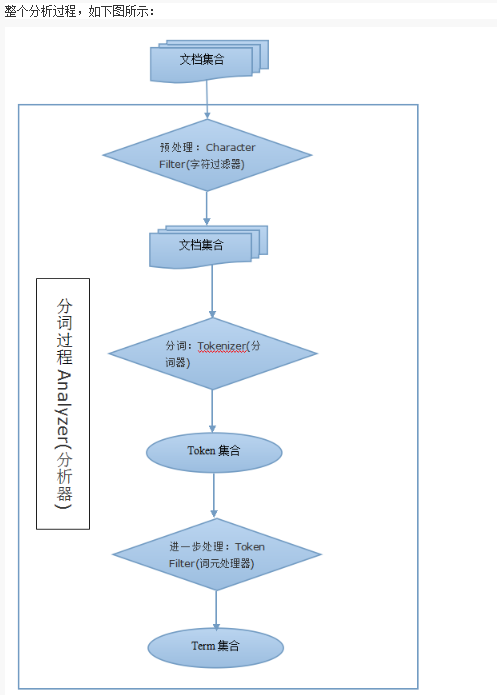
全文搜索引擎会用某种算法对要建索引的文档进行分析, 从文档中提取出若干Token(词元), 这些算法称为Tokenizer(分词器), 这些Token会被进一步处理, 比如转成小写等, 这些处理算法被称为Token Filter(词元处理器), 被处理后的结果被称为Term(词), 文档中包含了几个这样的Term被称为Frequency(词频)。 引擎会建立Term和原文档的Inverted Index(倒排索引), 这样就能根据Term很快到找到源文档了。 文本被Tokenizer处理前可能要做一些预处理, 比如去掉里面的HTML标记, 这些处理的算法被称为Character Filter(字符过滤器), 这整个的分析算法被称为Analyzer(分析器)。
一个分析器是3个顺序执行的组件的结合(字符过滤器Character Filter(0/N个),分词器Tokenizer(1个),词元处理器Token Filter(0/N个)):
1)Character Filters的作用就是对文本进行一个预处理,例如把文本中所有“&”换成“and”,把“?”去掉等等操作
2)Tokenizer的作用是进行分词,例如,“tom is a good doctor”,分词器Tokenizer会将这个文本分出很多词来:“tom”、“is”、“a”、“good”、“doctor”
3)Token Filter的作用就是对分词出来的词元进行处理,得到term,例如tom可能被处理成"t","o","m",最后得出来的结果集合,就是最终的集合
ES中关于内置分析器,分词器的定义在: https://www.elastic.co/guide/en/elasticsearch/reference/current/analysis.html
常用分词器介绍:http://jingyan.baidu.com/article/cbcede071e1b9e02f40b4d19.html
http://blog.youkuaiyun.com/i6448038/article/details/51614220
http://blog.youkuaiyun.com/i6448038/article/details/51509439
1 ES内置的分析器
| analyzer | logical name | description |
|---|---|---|
| standard analyzer | standard | standard tokenizer, standard filter, lower case filter, stop filter |
| simple analyzer | simple | lower case tokenizer |
| stop analyzer | stop | lower case tokenizer, stop filter |
| keyword analyzer | keyword | 不分词,内容整体作为一个token(not_analyzed) |
| pattern analyzer | whitespace | 正则表达式分词,默认匹配\W+ |
| language analyzers | lang | 各种语言 |
| snowball analyzer | snowball | standard tokenizer, standard filter, lower case filter, stop filter, snowball filter |
| custom analyzer | custom | 一个Tokenizer, 零个或多个Token Filter, 零个或多个Char Filter |
2 ES内置的分词器
| tokenizer | logical name | description |
|---|---|---|
| standard tokenizer | standard | |
| edge ngram tokenizer | edgeNGram | |
| keyword tokenizer | keyword | 不分词 |
| letter analyzer | letter | 按单词分 |
| lowercase analyzer | lowercase | letter tokenizer, lower case filter |
| ngram analyzers | nGram | |
| whitespace analyzer | whitespace | 以空格为分隔符拆分 |
| pattern analyzer | pattern | 定义分隔符的正则表达式 |
| uax email url analyzer | uax_url_email | 不拆分url和email |
| path hierarchy analyzer | path_hierarchy | 处理类似/path/to/somthing样式的字符串 |
ES内置的过滤器:
| token filter | logical name | description |
|---|---|---|
| standard filter | standard | |
| ascii folding filter | asciifolding | |
| length filter | length | 去掉太长或者太短的 |
| lowercase filter | lowercase | 转成小写 |
| ngram filter | nGram | |
| edge ngram filter | edgeNGram | |
| porter stem filter | porterStem | 波特词干算法 |
| shingle filter | shingle | 定义分隔符的正则表达式 |
| stop filter | stop | 移除 stop words |
| word delimiter filter | word_delimiter | 将一个单词再拆成子分词 |
| stemmer token filter | stemmer | |
| stemmer override filter | stemmer_override | |
| keyword marker filter | keyword_marker | |
| keyword repeat filter | keyword_repeat | |
| kstem filter | kstem | |
| snowball filter | snowball | |
| phonetic filter | phonetic | 插件 |
| synonym filter | synonyms | 处理同义词 |
| compound word filter | dictionary_decompounder, hyphenation_decompounder | 分解复合词 |
| reverse filter | reverse | 反转字符串 |
| elision filter | elision | 去掉缩略语 |
| truncate filter | truncate | 截断字符串 |
| unique filter | unique | |
| pattern capture filter | pattern_capture | |
| pattern replace filte | pattern_replace | 用正则表达式替换 |
| trim filter | trim | 去掉空格 |
| limit token count filter | limit | 限制token数量 |
| hunspell filter | hunspell | 拼写检查 |
| common grams filter | common_grams | |
| normalization filter | arabic_normalization, persian_normalization |
ES内置的字符过滤器:
| character filter | logical name | description |
|---|---|---|
| mapping char filter | mapping | 根据配置的映射关系替换字符 |
| html strip char filter | html_strip | 去掉HTML元素 |
| pattern replace char filter | pattern_replace | 用正则表达式处理字符串 |
自定义一个拼音分析器的命令:


/test --建索引命令 post /test/_settings --修改索引setting的命令 put { --设置参数 "index": { "analysis": { "analyzer": { --自定义分析器 "pinyinanalyzer": { "tokenizer": "lishuai_pinyin", --使用下面自定义的分词器 "filter": [ --使用过滤器 "lowercase", "mynGramFilter" --自定义的过滤器 ] } }, "tokenizer": { --自定义分词器 "lishuai_pinyin": { "type": "pinyin", --对应plugin中分词器的名称 "first_letter": "prefix", --前缀分词器 "padding_char": "" } }, "filter": { --自定义过滤器 "mynGramFilter": { --如果词的长度大于最短词长度则分词,则依次分成最小长度递进到最大长度的词。 "type": "nGram", "min_gram": "2", --词语2个以上才会分词 "max_gram": "5" --词语最多分成长度为5个的词语 } } } } } "padding_char": " " --分此后 每个词元以指定符号区分: "first_letter": "prefix" --是否分出每个字的首字母 ,如果配置了,词语刘德华会被分成ldh liu de hua mappings: post /test/product/_mapping --为索引设置type 指定mapping { "product": { "properties": { "name": { "type": "string", "store": "yes", "index": "analyzed", "term_vector": "with_positions_offsets" --表示额外索引的当前和结束位置 "analyzer": "pinyinanalyzer" } } } }
.NET nest实现代码:
1)es的mapping模型和自定义的分词插件
1 [ElasticsearchType(Name = "associationtype")] 2 public class AssociationInfo 3 { 4 [String(Store = true, Index = FieldIndexOption.Analyzed, TermVector = TermVectorOption.WithPositionsOffsets, Analyzer = "mypinyinanalyzer")] 5 public string keywords { get; set; } 6 [String(Store = true, Index = FieldIndexOption.NotAnalyzed)] 7 public string webSite { get; set; } 8 } 9 10 /// <summary> 11 /// 自定义拼音分词器 12 /// </summary> 13 public class PinYinTokenizer : ITokenizer 14 { 15 16 17 public string Type 18 { 19 get { return "pinyin"; } 20 } 21 22 public string Version 23 { 24 get 25 { 26 return string.Empty; 27 } 28 set 29 { 30 throw new NotImplementedException(); 31 } 32 } 33 34 public string first_letter 35 { 36 get { return "prefix"; } //开启前缀匹配 37 } 38 39 public string padding_char { 40 get { return " "; } 41 } 42 43 public bool keep_full_pinyin 44 { 45 get { return true; } 46 47 } 48 49 } 50 /// <summary> 51 /// 自定义拼音词元过滤器 52 /// </summary> 53 public class PinYinTF : ITokenFilter 54 { 55 /// <summary> 56 /// 连词过滤器 57 /// </summary> 58 public string Type 59 { 60 get { return "nGram"; } 61 } 62 63 public string Version 64 { 65 get 66 { 67 return ""; 68 } 69 set 70 { 71 throw new NotImplementedException(); 72 } 73 } 74 75 public int min_gram 76 { 77 get 78 { 79 return 2; 80 } 81 } 82 public int max_gram 83 { 84 get 85 { 86 return 5; 87 } 88 } 89 }
2)创建索引
1 /// <summary> 2 /// 创建索引 3 /// </summary> 4 public void CreateIndex() 5 { 6 //使用es默认的过滤器 7 //List<string> filters = new List<string>() { "word_delimiter" }; // word_delimiter 将一个单词再拆成子分词,nGram 连词过滤器 8 //自定义的分词器和过滤器 9 var pinYinTokenizer = new PinYinTokenizer(); 10 var pinYinTF = new PinYinTF(); 11 //一个自定义分析器需要设置1个分词器,0/n个Token Filters和0到多个Char Filters 12 var create = new CreateIndexDescriptor("shuaiindex").Settings(s => s.Analysis(a => //自定义一个分析器 13 a.Tokenizers(ts => ts.UserDefined("pinyintoken", pinYinTokenizer)) //1 为分析器创建一个用户自定义的pinyin分词器,当然还可以创建自定义TokenFilters表征过滤器,自定义CharFilters字符过滤器 14 .TokenFilters(tf => tf.UserDefined("pinyintf", pinYinTF)) 15 .Analyzers(c => c.Custom("mypinyinanalyzer", f => //2设置自定义分析器的名称 16 f.Tokenizer("pinyintoken").Filters("pinyintf"))) //3 为分析器设置1个刚才自定义的pinyin分词器和一个自定义的词元过滤器 17 )) 18 //设置mapping 19 .Mappings(map => map.Map<AssociationInfo>(m => m.AutoMap())); 20 21 var client = ElasticSearchCommon.GetInstance().GetElasticClient(); 22 var rs = client.CreateIndex(create); 23 client.IndexMany(CreateAssociationInfo(), "shuaiindex", "associationtype"); 24 } 25 public List<AssociationInfo> CreateAssociationInfo() 26 { 27 List<AssociationInfo> AssociationInfos = new List<AssociationInfo>(); 28 AssociationInfos.Add(new AssociationInfo() { keywords = "牛奶牛肉", webSite = "1" }); 29 AssociationInfos.Add(new AssociationInfo() { keywords = "小牛", webSite = "1" }); 30 AssociationInfos.Add(new AssociationInfo() { keywords = "果苹", webSite = "1" }); 31 AssociationInfos.Add(new AssociationInfo() { keywords = "牛肉", webSite = "1" }); 32 AssociationInfos.Add(new AssociationInfo() { keywords = "牛肉干", webSite = "1" }); 33 AssociationInfos.Add(new AssociationInfo() { keywords = "牛奶", webSite = "1" }); 34 AssociationInfos.Add(new AssociationInfo() { keywords = "肥牛", webSite = "1" }); 35 AssociationInfos.Add(new AssociationInfo() { keywords = "牛头", webSite = "1" }); 36 AssociationInfos.Add(new AssociationInfo() { keywords = "苹果", webSite = "1" }); 37 AssociationInfos.Add(new AssociationInfo() { keywords = "车厘子", webSite = "1" }); 38 return AssociationInfos; 39 40 }
3)查询
1 public List<AssociationInfo> query(string key) 2 { 3 QueryContainer query = new QueryContainer(); 4 //query=Query<AssociationInfo>.Prefix(s => s.Field(f => f.keywords).Value(key)); 5 query = Query<AssociationInfo>.Term("keywords", key); 6 //match 会把词语拆开,匹配每一项 7 //query = Query<AssociationInfo>.Match(m => m 8 // .Field(p => p.keywords) 9 // .Query(key) 10 // ); 11 var client = ElasticSearchCommon.GetInstance().GetElasticClient(); 12 13 SearchRequest request = new SearchRequest("shuaiindex", "associationtype"); 14 request.Query = query; 15 //request.Analyzer = "mypinyinanalyzer"; 16 ISearchResponse<AssociationInfo> response = client.Search<AssociationInfo>(request); 17 List<AssociationInfo> re = new List<AssociationInfo>(); 18 19 if (response.Documents.Count() > 0) 20 { 21 re = response.Documents.ToList(); 22 } 23 return re; 24 }

















 244
244

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









