




算法实现在本类下另外一篇文章
Kmeans算是是聚类中的经典算法,过程如下:
选择K个点作为初始质心
repeat
将每个点指派到最近的质心,形成K个簇
重新计算每个簇的质心
until 簇不发生变化或达到最大迭代次数
算法中的K需要人为的指定。确定K的做法有很多,比如多次进行试探,计算误差,得出最好的K。这样需要比较长的时间。我们可以根据Canopy算法来粗略确定K值(可以认为相等)。看一下Canopy算法的过程:
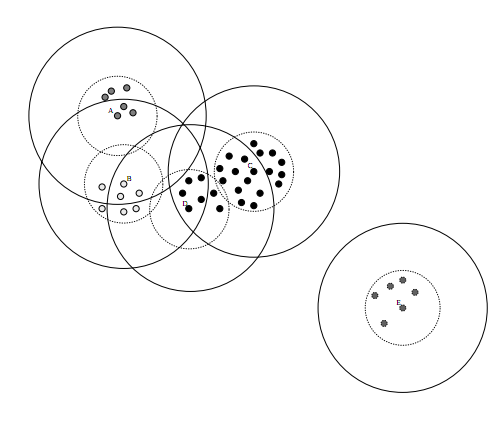
(1)设样本集合为S,确定两个阈值t1和t2,且t1>t2。
(2)任取一个样本点p,作为一个Canopy,记为C,从S中移除p。
(3)计算S中所有点到p的距离dist
(4)若dist<t1,则将相应点归到C,作为弱关联。
(5)若dist<t2,则将相应点移出S,作为强关联。
(6)重复(2)~(5),直至S为空。
Canopy 个数完全可以作为这个K值

















 3382
3382

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









