import json #处理 JSON 字符串
from typing import Iterable #解码 POST 表单字符串
import urllib.parse #用 BeautifulSoup 解析 HTML 页面
import bs4 #读取 Excel / CSV 文件
import scrapy #Scrapy 框架核心
import pandas #发送模拟表单 POST 请求
from scrapy import FormRequest, Request
from paper.items import ZhiwangItem #自定义数据结构
import os
import subprocess
root_path = os.getcwd()
class ZhiwangspiderSpDDider(scrapy.Spider):
name = "zhiwangspider"
allowed_domains = ["kns.cnki.net"] #限定爬虫的网站
cookies = {
"Ecp_ClientId": "h250415025900118829",
"Ecp_IpLoginFail": "250418139.227.167.167",
"SID_kns_new": "kns2618105",
"updatetime-advInput": "2025-04-18 09:44:47",
"knsadv-searchtype": '{"BLZOG7CK":"gradeSearch,majorSearch","MPMFIG1A":"gradeSearch,majorSearch,sentenceSearch","T2VC03OH":"gradeSearch,majorSearch","JQIRZIYA":"gradeSearch,majorSearch,sentenceSearch","S81HNSV3":"gradeSearch","YSTT4HG0":"gradeSearch,majorSearch,authorSearch,sentenceSearch","ML4DRIDX":"gradeSearch,majorSearch","WQ0UVIAA":"gradeSearch,majorSearch","VUDIXAIY":"gradeSearch,majorSearch","NN3FJMUV":"gradeSearch,majorSearch,authorSearch,sentenceSearch","LSTPFY1C":"gradeSearch,majorSearch,sentenceSearch","HHCPM1F8":"gradeSearch,majorSearch","OORPU5FE":"gradeSearch,majorSearch","WD0FTY92":"gradeSearch,majorSearch,authorSearch,sentenceSearch","BPBAFJ5S":"gradeSearch,majorSearch,authorSearch,sentenceSearch","EMRPGLPA":"gradeSearch,majorSearch","PWFIRAGL":"gradeSearch,majorSearch,sentenceSearch","U8J8LYLV":"gradeSearch,majorSearch","R79MZMCB":"gradeSearch","J708GVCE":"gradeSearch,majorSearch","HR1YT1Z9":"gradeSearch,majorSearch","JUP3MUPD":"gradeSearch,majorSearch,authorSearch,sentenceSearch","NLBO1Z6R":"gradeSearch,majorSearch","RMJLXHZ3":"gradeSearch,majorSearch,sentenceSearch","1UR4K4HZ":"gradeSearch,majorSearch,authorSearch,sentenceSearch","NB3BWEHK":"gradeSearch,majorSearch","XVLO76FD":"gradeSearch,majorSearch"}',
"SID_sug": "018104",
"knsadvisearchtype": "gDoCkPaXdjDCcKq91XRchA==",
"dblang": "both",
"createtime-advInput": "2025-04-18 19:02:41",
"tfstk": "giejKvftVEYbcWYumZIrARqwR9H_hP6F5hiTxlp2XxHA55Ztz-lauSP71yrKkxrZu33tyRww_qjmCfUTkPGGmVut5PrTggWFLoqmIAp189WEnE9NdrOxMdIt2Did4mn47yPZIAQFzthoY7DgkMoviSERVcoEDdU9HQB-rDAxBqh9yQnKyVHTWqp-2DmpBCntB3ISj4ntBAUtexFkc0dKPoscHjLV4Kl4D499B-Bii2soo0m4FEhS8oeyBdCicjgLD4QAlwhtwlc_IhvsuoF3SDUvkwl0X7aScA6yMvE76yiuH98jqSr8Y4EBjdqxh8wSv8I9pVybak3SdhBYVxgj9-lACGaLVlFEN8SdKxMxk5k0bH_4V-a4m8ZwXQHj37GQhvBHkVPzARi_INX7Rk2uP0UdCZIyUpuCxbA6VXvsV2S5VCAGTyRu2FsN4ghxq0fNVgOnzjnoV2S5VCAiM0mlogsWt45.."
}
school = pandas.read_csv(os.path.join(root_path,"..","school.csv"))
beida = pandas.read_excel(os.path.join(root_path,"..","北核期刊.xlsx"))
nanda = pandas.read_excel(os.path.join(root_path,"..","南核期刊.xlsx"))
headers = {
"accept": "*/*",
"accept-encoding": "gzip, deflate, br, zstd",
"accept-language": "zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6",
"content-type": "application/x-www-form-urlencoded; charset=UTF-8",
"origin": "https://kns.cnki.net",
"referer": "https://kns.cnki.net/kns8s/AdvSearch?crossids=YSTT4HG0,LSTPFY1C,JUP3MUPD,MPMFIG1A,WQ0UVIAA,BLZOG7CK,PWFIRAGL,EMRPGLPA,NLBO1Z6R,NN3FJMUV",
"sec-ch-ua": '"Microsoft Edge";v="135", "Not-A.Brand";v="8", "Chromium";v="135"',
"sec-ch-ua-mobile": "?0",
"sec-ch-ua-platform": '"Windows"',
"sec-fetch-dest": "empty",
"sec-fetch-mode": "cors",
"sec-fetch-site": "same-origin",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/135.0.0.0 Safari/537.36 Edg/135.0.0.0",
"x-requested-with": "XMLHttpRequest"
}
def start_requests(self):
for school in self.school.values:
school = school[0]
for magazine in self.nanda.values:
magazine = magazine[3]
zongfenlei=magazine[0][2:] #去掉前两个编号 只取分类名称
school = school
magazine = magazine
data = 'boolSearch=true&QueryJson={"Platform":"","Resource":"CROSSDB","Classid":"WD0FTY92","Products":"","QNode":{"QGroup":[{"Key":"Subject","Title":"","Logic":0,"Items":[],"ChildItems":[{"Key":"input[data-tipid=gradetxt-3]","Title":"作者单位","Logic":0,"Items":[{"Key":"input[data-tipid=gradetxt-3]","Title":"作者单位","Logic":0,"Field":"AF","Operator":"FUZZY","Value":"学校名称","Value2":""}],"ChildItems":[]},{"Key":"input[data-tipid=gradetxt-4]","Title":"文献来源","Logic":0,"Items":[{"Key":"input[data-tipid=gradetxt-4]","Title":"文献来源","Logic":0,"Field":"LY","Operator":"DEFAULT","Value":"杂志名称","Value2":""}],"ChildItems":[]}]},{"Key":"ControlGroup","Title":"","Logic":0,"Items":[],"ChildItems":[]}]},"ExScope":"0","SearchType":1,"Rlang":"CHINESE","KuaKuCode":"YSTT4HG0,LSTPFY1C,JUP3MUPD,MPMFIG1A,WQ0UVIAA,BLZOG7CK,EMRPGLPA,PWFIRAGL,NLBO1Z6R,NN3FJMUV"}&pageNum=1&pageSize=20&dstyle=listmode&boolSortSearch=false&sentenceSearch=false&productStr=YSTT4HG0,LSTPFY1C,RMJLXHZ3,JQIRZIYA,JUP3MUPD,1UR4K4HZ,BPBAFJ5S,R79MZMCB,MPMFIG1A,WQ0UVIAA,NB3BWEHK,XVLO76FD,HR1YT1Z9,BLZOG7CK,EMRPGLPA,J708GVCE,ML4DRIDX,PWFIRAGL,NLBO1Z6R,NN3FJMUV,&aside=(作者单位:学校名称(模糊))AND(文献来源:杂志名称(精确))&searchFrom=资源范围:总库;++时间范围:更新时间:不限;++&CurPage=1'
#构造一个知网接口接收POST表单
data = data.replace('学校名称', school).replace('杂志名称', magazine)
#自动替换关键词
decoded_form_data = urllib.parse.parse_qs(data) #把URL格式的表单字符串data转换成Scrapy能用的字典形式
data = {key: value[0] if value else "" for key, value in decoded_form_data.items()}
yield FormRequest(url='https://kns.cnki.net/kns8s/brief/grid',cookies=self.cookies,headers=self.headers,callback=self.parse,formdata=data,cb_kwargs={'学校':school,'期刊':magazine,'总分类':zongfenlei})
#发送post请求,并交给self.parse() 来处理返回的搜索结果
#对每一个【学校 + 期刊】组合,构造一个 POST 表单,模拟从知网“高级检索”搜索论文数量,并发出请求,交给 parse() 去处理返回结果。
def parse(self, response,**kwargs):
response=response.text
try:
soup = int(bs4.BeautifulSoup(response, 'html.parser').find('span', class_='pagerTitleCell').find(
'em').text.strip())
except:
soup=-99
ite=ZhiwangItem()
school=kwargs['学校']
magazine=kwargs['期刊']
zongfenlei=kwargs['总分类']
print(school,magazine,soup)
ite['学校']=school
ite['期刊']=magazine
ite['数量']=soup
ite['总分类']=zongfenlei
ite['属于']='南核'
yield ite
if __name__ == '__main__':
subprocess.run(['scrapy', 'crawl', 'zhiwangspider', '-o', '南核data.csv'])







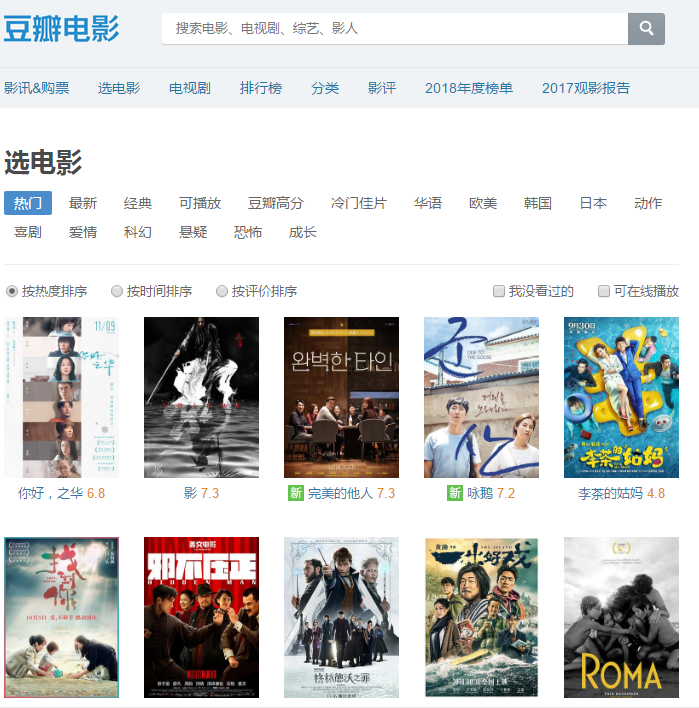
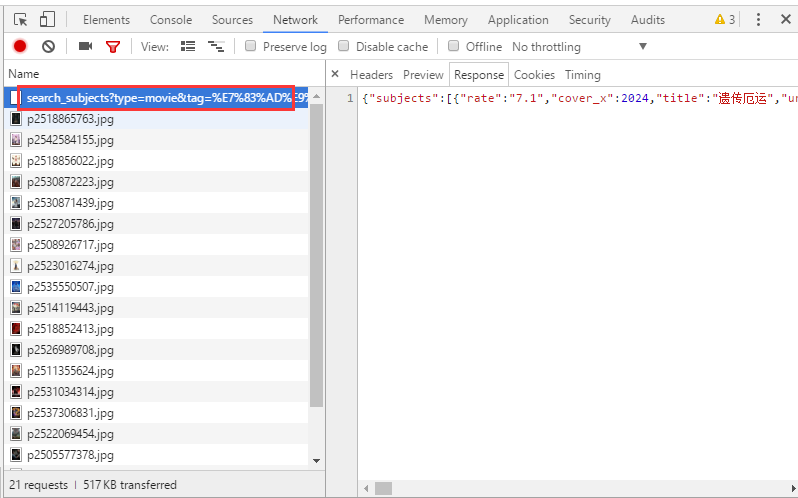
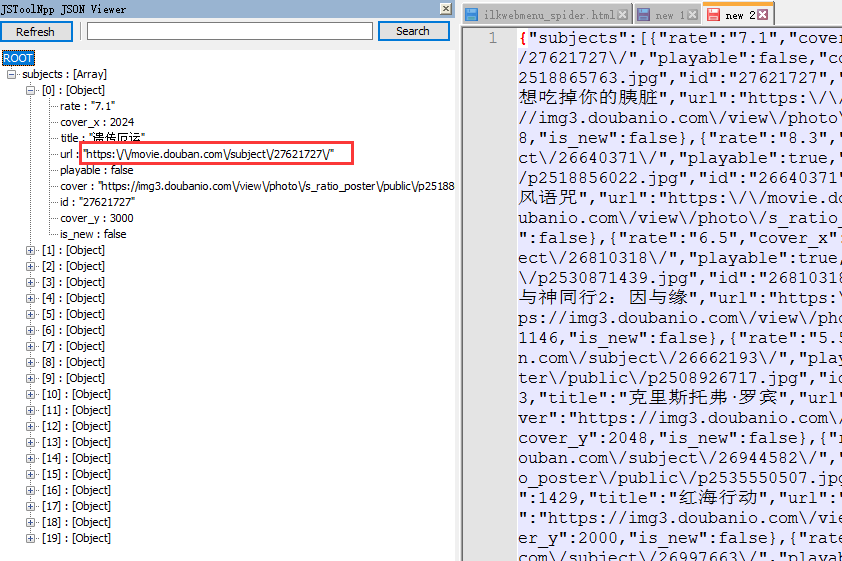
 本文详细介绍了使用前嗅ForeSpider进行链接抽取的实战教程,包括如何处理链接在POST请求中的情况,通过示例展示了如何利用浏览器开发者工具定位链接数据,以及在JSON数组中循环抽取链接的具体脚本实现。
本文详细介绍了使用前嗅ForeSpider进行链接抽取的实战教程,包括如何处理链接在POST请求中的情况,通过示例展示了如何利用浏览器开发者工具定位链接数据,以及在JSON数组中循环抽取链接的具体脚本实现。


















 4863
4863

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









