



 本文详细介绍如何在本地环境中安装和配置Scala 2.11.5及Spark 1.2.0,并设置Spark伪分布式运行环境。文章还介绍了如何通过一系列步骤验证Spark集群是否正确配置,包括启动Spark伪分布式、检查Hadoop集群状态、使用Spark Shell进行简单的MapReduce任务等。
本文详细介绍如何在本地环境中安装和配置Scala 2.11.5及Spark 1.2.0,并设置Spark伪分布式运行环境。文章还介绍了如何通过一系列步骤验证Spark集群是否正确配置,包括启动Spark伪分布式、检查Hadoop集群状态、使用Spark Shell进行简单的MapReduce任务等。

1、下载scala2.11.5版本,下载地址为:http://www.scala-lang.org/download/2.11.5.html
2、安装和配置scala:
第一步:上传scala安装包 并解压


第二步 配置SCALA_HOME环境变量到bash_profile

第三步 source 使配置环境变量生效:

第四步 验证scala:

3、下载spark 1.2.0,具体下载地址:http://spark.apache.org/downloads.html
4、安装和配置spark:
第一步 解压spark:


第二步 配置SPARK_HOME环境变量:

第三步 使用source生效:

进入spark的conf目录:
第四步 修改slaves文件,首先打开该文件:


slaves修改后:

第五步 配置spark-env.sh
首先把spark-env.sh.template拷贝到spark-env.sh:

然后 打开“spark-env.sh”文件:

spark-env.sh文件修改后:

5、启动spark伪分布式帮查看信息:
第一步 先保证hadoop集群或者伪分布式启动成功,使用jps看下进程信息:

如果没有启动,进入hadoop的sbin目录执行 ./start-all.sh
第二步 启动spark:
进入spark的sbin目录下执行“start-all.sh”:
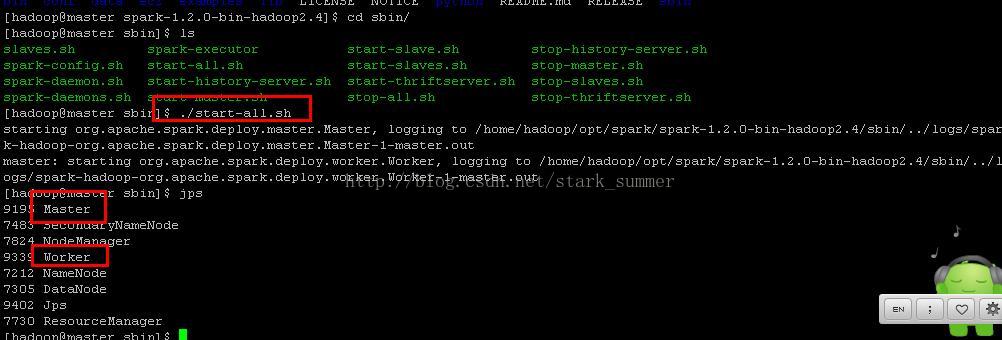
此刻 我们看到有新进程“Master” 和"Worker"
我们访问“http://master:8080/”,进如spark的web控制台页面:

从页面上可以看到一个Worker节点的信息。
我们进入spark的bin目录,使用“spark-shell”控制台:


通过访问"http://master:4040",进入spark-shell web控制台页面:

6、测试spark伪分布式:
我们使用之前上传到hdfs中的/data/test/README.txt文件进行mapreduce
取得hdfs文件:

对读取的文件进行一下操作:

使用collect命令提交并执行job:
readmeFile.collect

查看spark-shell web控制台:

states:

端口整理:
master端口是7077
master webui是8080
spark shell webui端口是4040


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









