



 本文深入探讨了SQLServer In-Memory OLTP的内部机制,包括行和索引存储、Range索引及列存储索引等关键概念。通过具体实例介绍了Bwtree数据结构以及列存储索引的压缩算法和技术细节。
本文深入探讨了SQLServer In-Memory OLTP的内部机制,包括行和索引存储、Range索引及列存储索引等关键概念。通过具体实例介绍了Bwtree数据结构以及列存储索引的压缩算法和技术细节。
行和索引存储
Range索引
Range 索引在 2014 的时候还是不支持的。 Range index 使用 bwtree 数据结构。 Bwtree 和 btree 一样有叶子结点和中间节点。最重要的不通点是, bwtree page 指针是一个逻辑的 page id ,而不是物理的 page no 。 PID 表示 mapping table 上的位置, mapping table 把 PID 和物理内存地址关联。 Bwtree 的 index page 是从来不更新的,而是增加一个新的,然后让 mapping table 的相同 PID 指向一个不同的物理内存地址。具体的bwtree的算法可以看:http://www.cnblogs.com/Amaranthus/p/4375331.html
列存储索引
列存储索引基本结构
SQL Server 2016 内存优化表支持聚集的列存储索引。列存储索引是高复合的索引,并不是由行来组织,而是用列来组织的。行被分为多个组,一个组最多可以有 2^20 行,然后把某一列的数据放入行组中,不会去管剩下的行。每个行组,SQL Server都会使用Vertipaq压缩算法,重新编码和排列行组中的顺序来打到最有的压缩效果。每个行组中的列都是独立保存的,这个结构称之为段(segment),每个段都是一个LOB,保存在LOB的分配段元中。段是数据读写的基本单元,如图,表示吧一组多个索引列转化为几个段
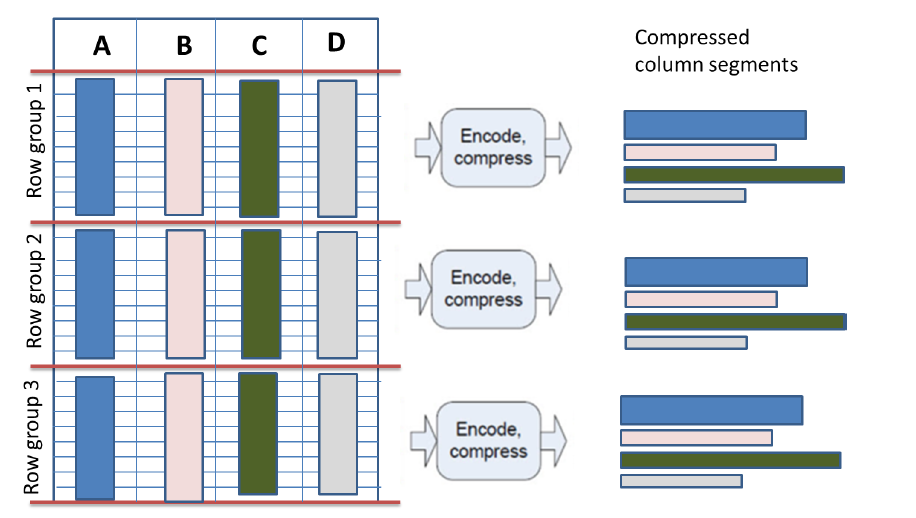
上图中,表被分为3个行组,每个行组有4个段,一共有12个段。
为了支持聚集行存储索引的更新,有2个额外的结构。一个独立的内部表(deleted rows table DRT)。顾名思义是用来做被删除行的bitmap,用来保存所有已经删除的行的rowid。新行加入会被保存在一个堆中,Delta Store。当行数达到一定行数(通常是2^20或者10万行),SQL Server会吧这些行转化为新的压缩的行组。
内存优化表中聚集列存储索引和内存优化表的非聚集索引是分开保存的,是数据的一个副本。实际上,内存优化表的聚集列存储索引你可以理解为,保存了所有列的非聚集列存储索引。因为数据是高效压缩的,因此开销比较少。因为类存储索引可以压缩到原始数据的10%,因此开销也只有10%。
所有的类存储索引段都是在内存中的。为了恢复的目的,每个行组在内存优化文件组中都保存成一个独立的文件类型为LARGE DATA,在文件中对于某个行组,所有的段都是存放在一起的。SQL Server也维护了一个指针,指向每个段并且可以访问这个段,特别是访问了部分列的时候。这个部分会在下面CHECKPOINT FILES的时候介绍。新的行会被以列存储索引保存,但是并不会马上加入到压缩行组中,新的行只能使用内存优化表的其他索引来访问。如图,新的行和整个表分开维护的。你可以认为这些行是“delta rowgroup”和磁盘表的Delta Store类似,但是这些行是内存优化表的一部分,但是不是技术上的列存储索引的一部分。实际上是课件的delta rowgroup
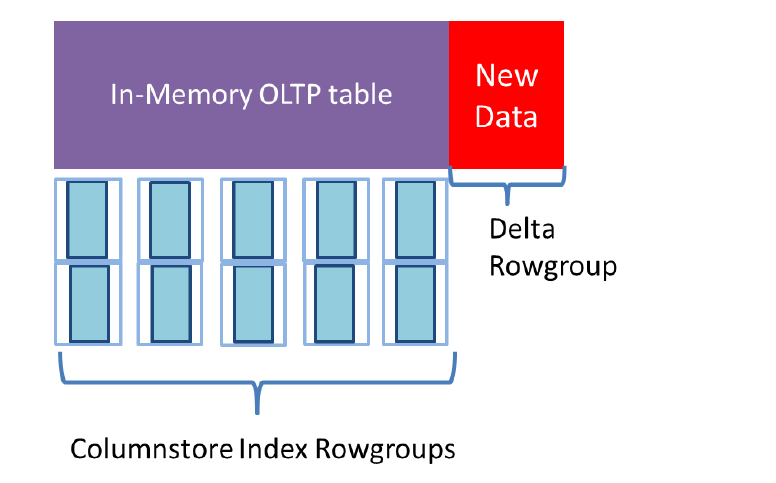
内存优化表中的列存储索引只能在interop模式下由优化器进行选择。查询使用类存储索引可以并发并且对于高性能有很多好处。原生编译过程是不会使用列存储索引的,并且所有的查询都不会并发执行。若一个SQL Server 2016的内存优化表有聚集列存储索引,那么就有2个varheap,一个用于压缩行组,另外一个用来保存新行,可以让SQL Server快速识别哪些行还没有进入压缩段,这些行也在可见的delta rowgroup中。
有2个后台线程每2分钟执行一次,用来检查delta rowgroup中的行。注意这些行包含最新插入的,和update的,在内存优化表update就是delete+insert。如果这些行数超过10万那么就有下面2个操作:
- 行会被复制到一个或者多个行组,每个段都会被压缩转化变成聚集列存储索引的一部分。
- 行会从特定的内存分配器移到常规的内存存储。
SQL Server并不会是实际统计行数,而是使用评估。没有行组的行数可以超过1048576.如果超过有10万行,那么就会创建另外一个行组。如果小于10万行那么这些行还是会被留在原来的地方。
因为最新插入的行会被频繁更新,或者会被删除,想要延迟对最新行的压缩,可以设置一个等待量。当内存优化表有聚集列存储索引,那么就可以增加一个COMPRESSION_DELAY的参数,指定新行必须在delta rowgroup中呆多久。只有超过参数的行数超过10万才会被压缩到常规的列存储索引行组中。
当行被转换到压缩rowgroup之后,所有删除的行都会被放到Delete Rows表中,和磁盘表的聚集列存储索引。当行多的时候查询会很没有效率。这种情况下重组列存储索引并没有什么用,除非删除并且重建索引。一旦rowgroup中90%的行被删除,剩下的10%会自动被插入到未压缩的varheap,在内存优化表的Delta rowgroup中。Rowgroup的存储会被进行垃圾回收。
Note:
前面提到的,如果内存优化表有任何LOB或者溢出列,列存储索引不能在上面被创建。因为最大的行不能超过8060字节。另外一旦内存优化表有一个列存储索引,就不能使用alter table操作。需要先删除列存储索引,alter,然后再创建列存储索引。
以下是创建内存优化表的脚本,有2个索引,一个range索引一个列存储索引,然后查询内存消费。并且设置COMPRESSION_DELAY为60分钟。
AND c.index_id = i.index_id;
返回的结果:
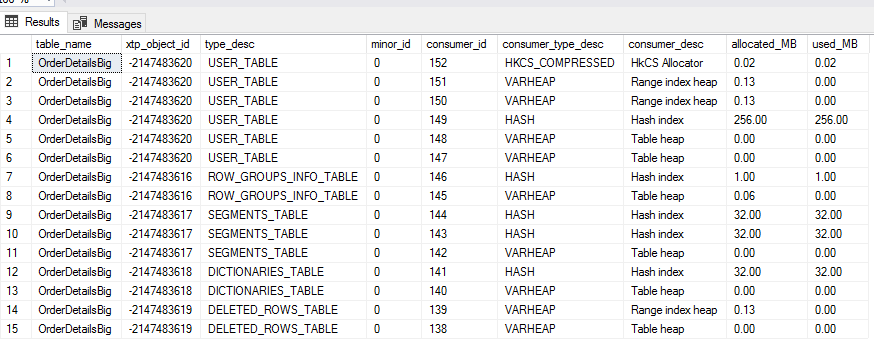
上图,显示表自己有6行。有一个内存消费者用于压缩rowgroup(HKCS_COMPRESSED消费者),2个用于range index,1个用于hash index,2个用于表的行存储(rowstore)(这个和白皮书中说的不同),行存储中其中一个是为了表中的行,第二个是delta rowgroup。每个有列存储索引的表都有4个内部表,xtp_object_id都不相同。每个内部表为了访问方便至少有一个索引用于数据访问。四个内部表:ROW_GROUP_INFO_TABLE(+hash索引),SEGMENTS_TABLE(+2个hash索引),DICTIONARIES_TABLE(+hash 索引),DELETED_ROW_TABLE(+hash索引)。(这些内部表的细节白皮书没有介绍)
除了看内存消费者之外,另外一个要检查的DMV是sys.dm_db_column_store_row_group_ physical_stats,这个视图不单单是显示了每个COMPRESSED并且OPEN的rowgroup的行数。你可以用一下脚本查看:
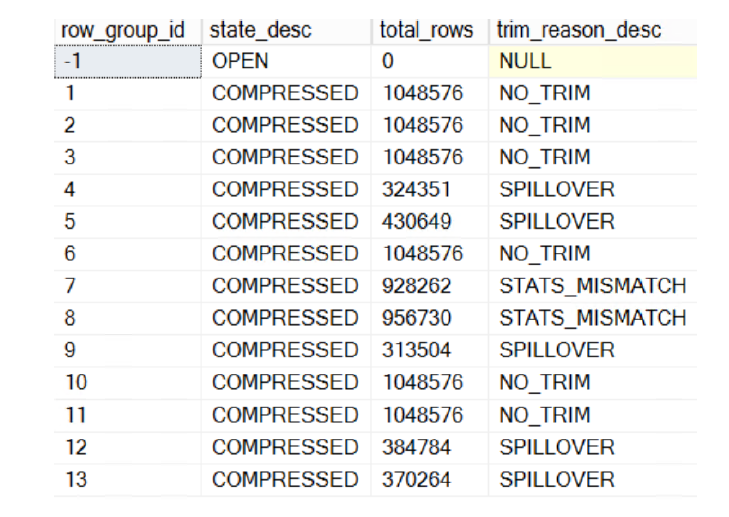
可以通过time_reason_desc字段可以查看为什么rowgroup的行会少于1048576行。如果没有小于1048576那么就显示NO_TRIM。因为OPEN的rowgroup是不压缩的,因此为null,若为STATS_MISMATCH表示行太少,若为SPILLOVER表示有移除导致。
本文转自 Fanr_Zh 博客园博客,原文链接:http://www.cnblogs.com/Amaranthus/p/7808255.html,如需转载请自行联系原作者

















 6061
6061

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









