






Microsoft的XML大师Chris Lovett发布了一个新的SGML解析器(应该是2008年的版本),叫做SgmlReader(早期的SgmlReader在2006年以前就出了),它可以解析HTML文件,甚至将它们转换成一个格式规范的结构。SgmlReader派生于XmlReader,这就是说,你可以像运用诸如XmlTextReader这样的类来解析XML文件那样来解析HTML文件。
将其实际应用的结果如图:
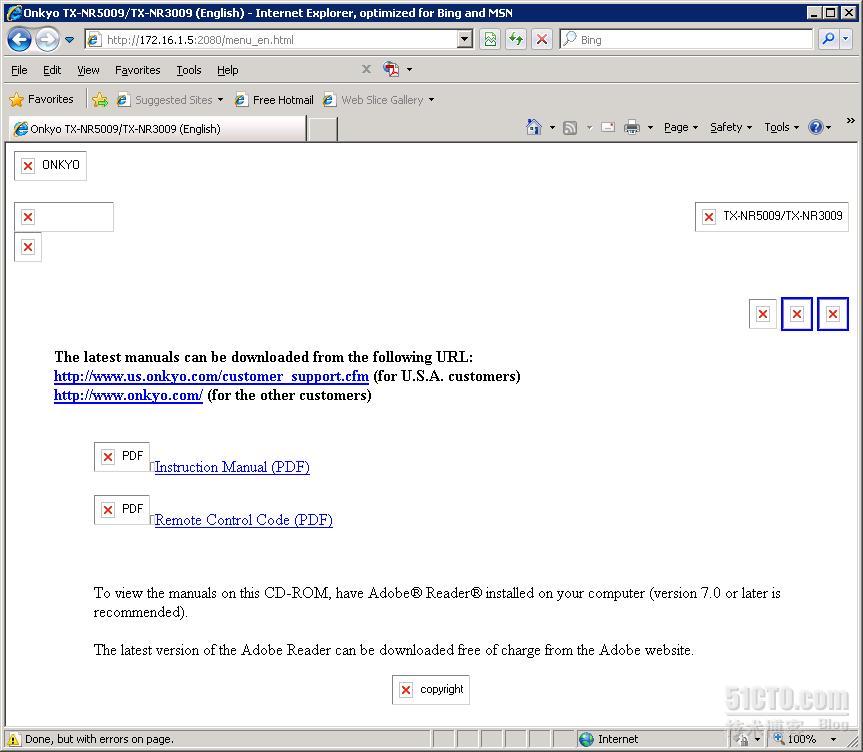
1. 示例网页(我们需要获取的):
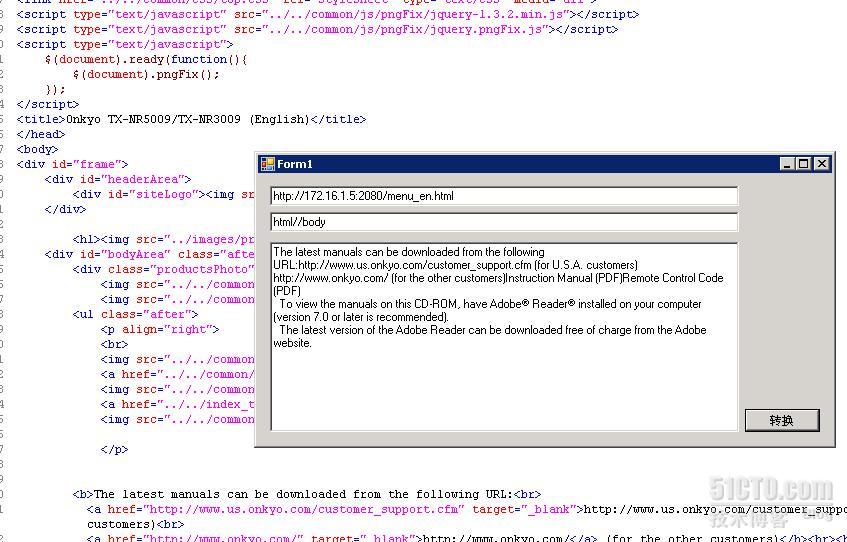
2. 获取<body>内所有标签的值
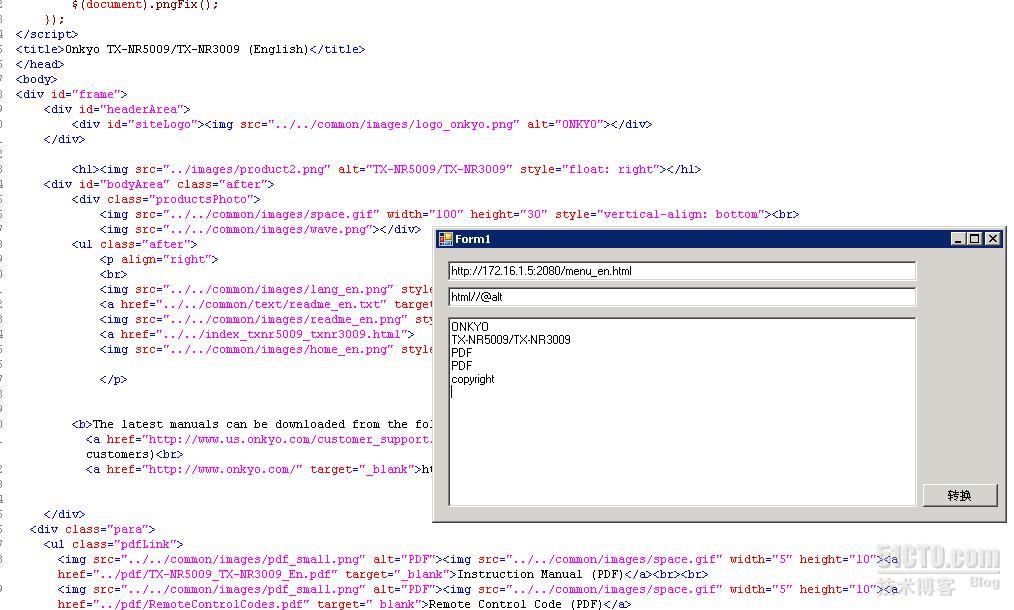
3. 获取<html>内所有alt属性值(图片提示信息)
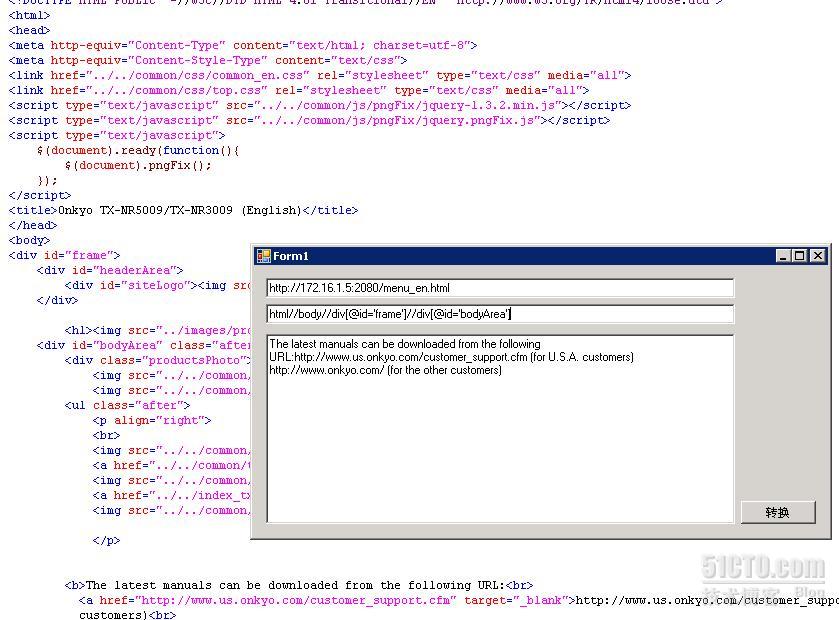
4. 获取<body>内<div>标签属性id为"frame"下,<div>标签属性id为"bodyArea",层内所有标签值
5. 以上示例都是获取远端HTML页面(http://172.16.1.5/menu_en.html)源码内容的示例,以下是获取本地HTML内标签值示例。

- private string GetWellFormedHTMLFile(string filePath, string xpath)
- {
- StreamReader sReader = null;
- StringWriter sw = null;
- SgmlReader reader = null;
- XmlTextWriter writer = null;
- try
- {
- sReader = new StreamReader(filePath);
- reader = new SgmlReader();
- reader.DocType = "HTML";
- reader.InputStream = new StringReader(sReader.ReadToEnd());
- sw = new StringWriter();
- writer = new XmlTextWriter(sw);
- writer.Formatting = Formatting.Indented;
- //writer.WriteStartElement("Test");
- while (reader.Read())
- {
- if (reader.NodeType != XmlNodeType.Whitespace)
- {
- writer.WriteNode(reader, true);
- }
- }
- //writer.WriteEndElement();
- if (xpath == null)
- {
- return sw.ToString();
- }
- else
- { //Filter out nodes from HTML
- StringBuilder sb = new StringBuilder();
- XPathDocument doc = new XPathDocument(new StringReader(sw.ToString()));
- XPathNavigator nav = doc.CreateNavigator();
- XPathNodeIterator nodes = nav.Select(xpath);
- while (nodes.MoveNext())
- {
- sb.Append(nodes.Current.Value + ((char)13).ToString());
- }
- return sb.ToString();
- }
- }
- catch (Exception exp)
- {
- writer.Close();
- reader.Close();
- sw.Close();
- sReader.Close();
- return exp.Message;
- }
- }
初步总结:
可以比较方便地根据指定url地址获取我们想要的页面内容,或者获取本地html文件的指定内容。
可以说已经初步解决基本HTML格式的EnjoyTR 字数统计问题(早期通过正则表达式删除标签的方式不可靠,而且无法将Unit区分),
EnjoyTR翻译由于没有还原的方法,我现在能想到的,就是原文替换的方式进行翻译(缺点,无法定位,当1个原文有多个译文的时候,无法一一对应)。
还需要研究的是:
根据图5,
我们可以看出,当javascript或者vbscript出现在我们需要的标签内时,从语法上是正确的,此时会将其一并获取,因此需要我们对标签进行筛选;
但,当script中出现实际要显示在页面的内容时,我们可能要对script的内容进行字符串筛选,
例如:
<script text='javascript'>
****.innerHtml='需要显示在页面上';
</script>
或者
<script text='javascript'>
var strDisplay='需要显示在页面上'; //变量
****.innerHtml=strDisplay;
</script>
字符串:“需要显示在页面上”,也是我们需要获取和翻译的内容。
XPath语法学习:
相关参考:
转载于:https://blog.51cto.com/116833/743346

















 2350
2350

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









