



 本文介绍了如何利用ELK(Elasticsearch + Logstash + Kibana)方案实现日志统一收集,重点阐述了在日志传输过程中遇到的LVS分发UDP请求问题的解决方法,包括在keepalived.conf中配置MISC_CHECK来成功检测并分发日志。同时,文章还解决了日志乱序和es集群脑裂的问题,提供了实用的解决策略。
本文介绍了如何利用ELK(Elasticsearch + Logstash + Kibana)方案实现日志统一收集,重点阐述了在日志传输过程中遇到的LVS分发UDP请求问题的解决方法,包括在keepalived.conf中配置MISC_CHECK来成功检测并分发日志。同时,文章还解决了日志乱序和es集群脑裂的问题,提供了实用的解决策略。

实时日志统一收集的好处:
1、快速定位集群中问题机器
2、无需下载整个日志文件(往往比较大,下载耗时多)
3、可以对日志进行统计
a、发现出现次数最多的异常,进行调优处理
b、统计爬虫ip
c、统计用户行为,做聚类分析等
基于上面的需求,我采用了 ELK(elasticsearch + logstash + kibana)的方案,安装方法可以参考我的项目 ELK_Tutorial,这里我主要讲讲我遇到的问题。
1、LVS 分发UDP请求不成功的问题
为了不影响线上集群的性能,我们采取了UDP的方式传输日志消息,如下图:

而负载均衡我采用了LVS,在配置LVS时,我发现需要在keepalived.conf里面使用MISC_CHECK方法才能在 protocol=UDP的情况下成功检测到real_server,并且分发成功,在keepalived.conf中关键配置的地方是:
real_server 机器A 12201 {
weight 1
MISC_CHECK {
misc_path "/etc/keepalived/udp_check.sh 机器A 12201"
misc_timeout 10
}
}而udp_check.sh 这个文件是我自己写的,里面的内容很简单:
/usr/bin/nc -uz -w1 $1 $2 | grep succeeded >/dev/null
exit $? 这里需要注意的是udp_check.sh 这个文件的权限,我这里设置的是 755
2、logstash集群发送的日志乱序
这个问题解决方法很简单,统一每台logstash机器的系统时间即可。
3、elasticsearch 集群脑裂
出现脑裂,即无法选举出master的情况,解决方式是加大心跳检测时间,高负载的情况下,可能出现master响应较慢,这时不能极端的认为master down掉了。
附下面是应用后场景(点击查看大图)
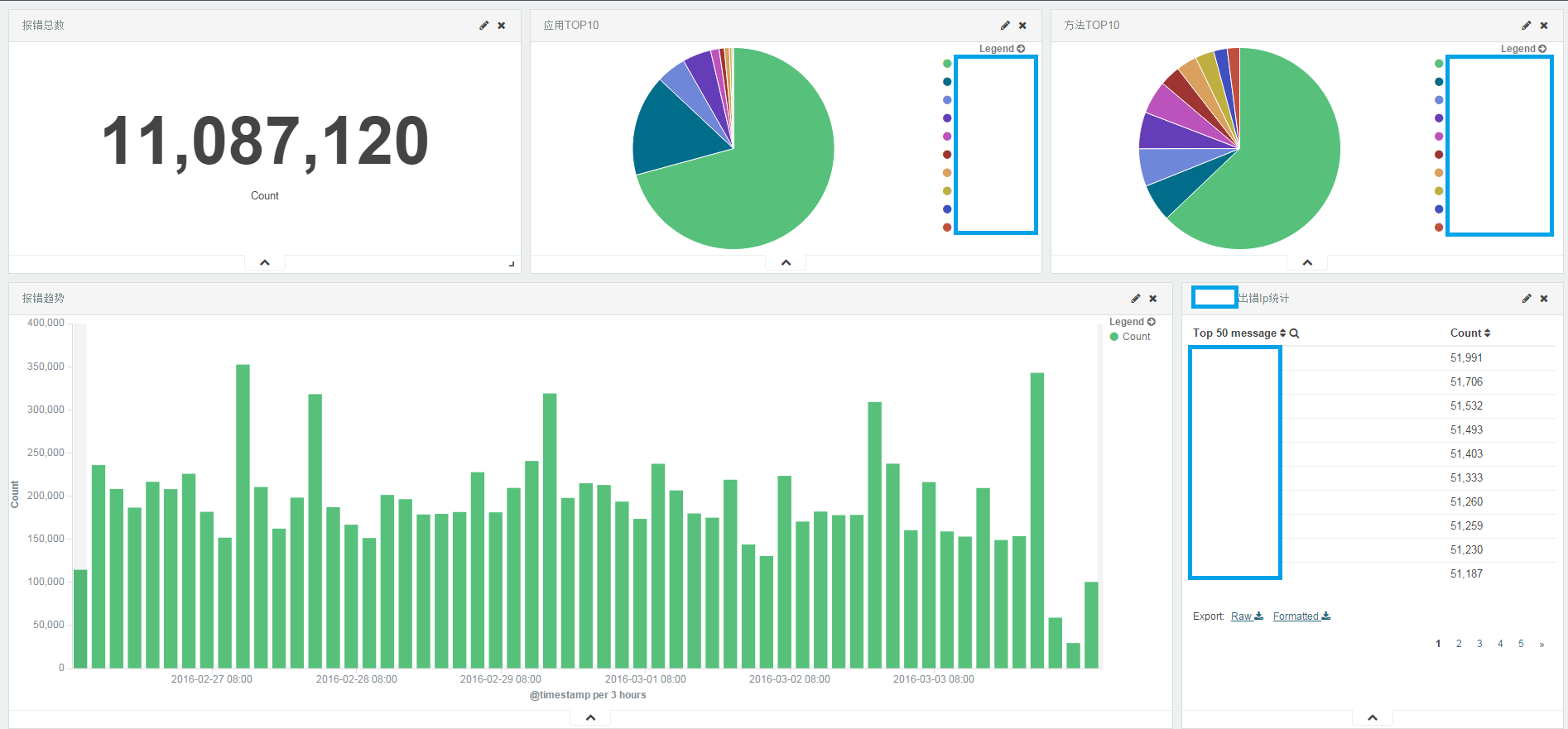
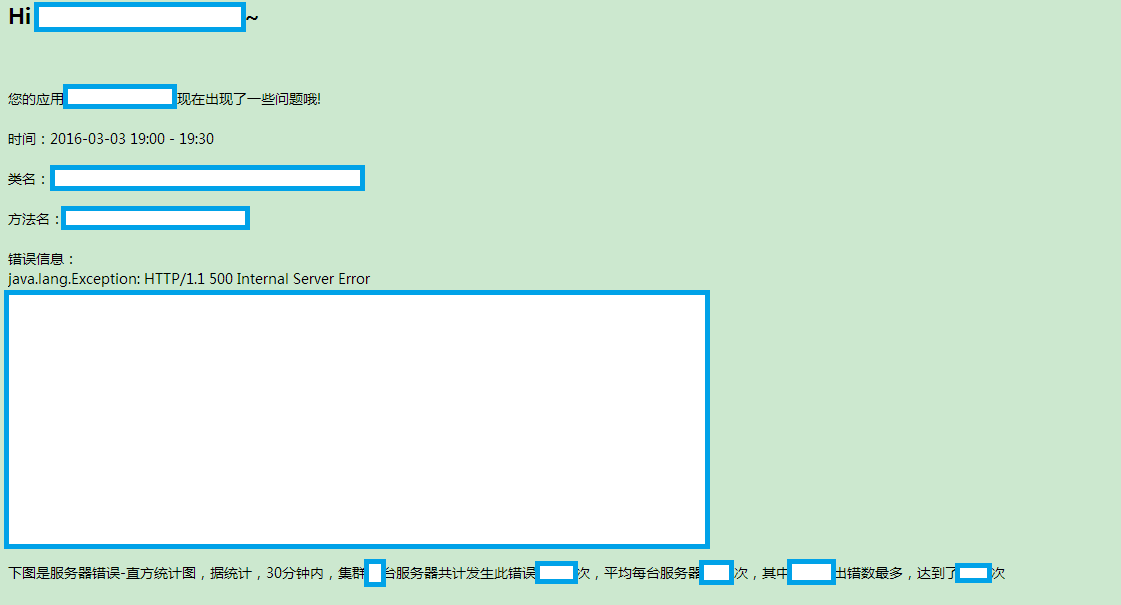
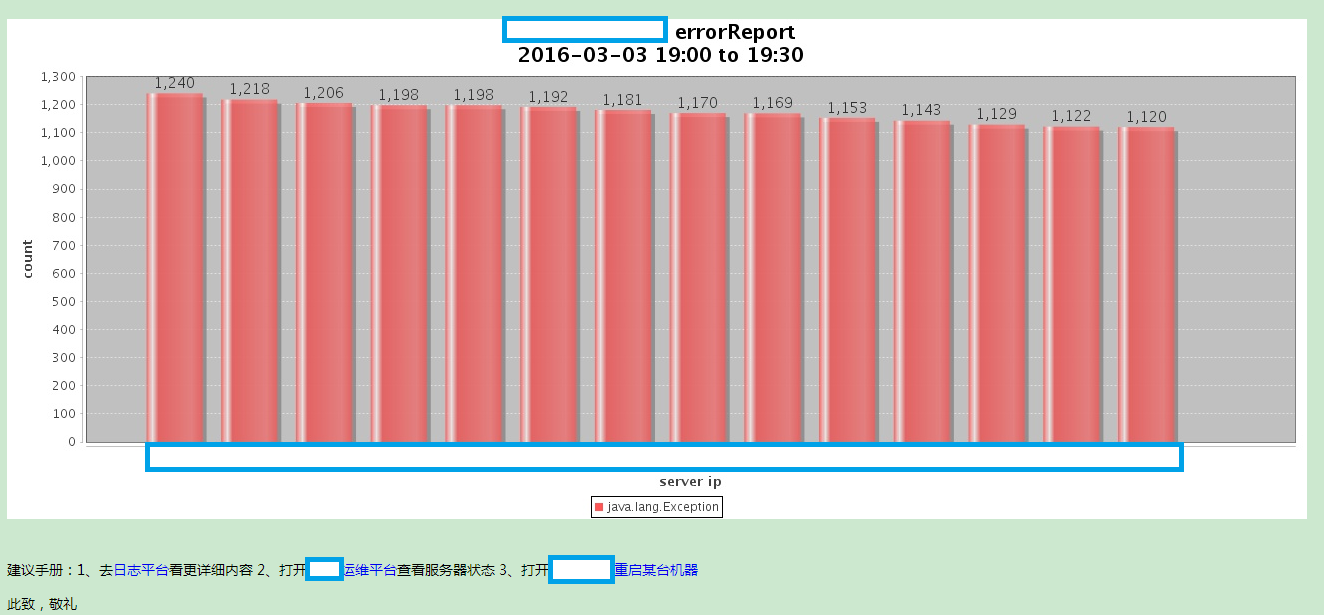
另外我们还基于ES API做了分析


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









