




产业:
Nuance:全球最大的语音识别技术提供商
IBM:具有强大数学底蕴的老牌语音识别研究机构
Microsoft:Vista操作系统中首次加入语音识别功能
Google:凭借互联网方面的优势GOOG-411,音乐搜索
学术:
Cambridge:HTK工具对学术界研究推动巨大
CMU:SPHINX-李开复
SRI,MIT,RWTH,ATR
语音识别实用化方面的两种论调
悲观:缺少杀手级应用,与人类的语音识别水平还有很大差距
乐观:Nuance能如此成功,计算机存储和运算能力的不断提高
语音识别各种具体应用
命令词系统
识别语法网络相对受限,对用户要求较严格
菜单导航,语音拨号,车载导航,数字字母识别等等
• 智能交互系统
对用户要求较为宽松,需要识别和其他领域技术的结合
呼叫路由,POI语音模糊查询,关键词检出
• 大词汇量连续语音识别系统
海量词条,覆盖面广,保证正确率的同时实时性较差
• 结合互联网的语音搜索
实现语音到文本,语音到语音的搜索
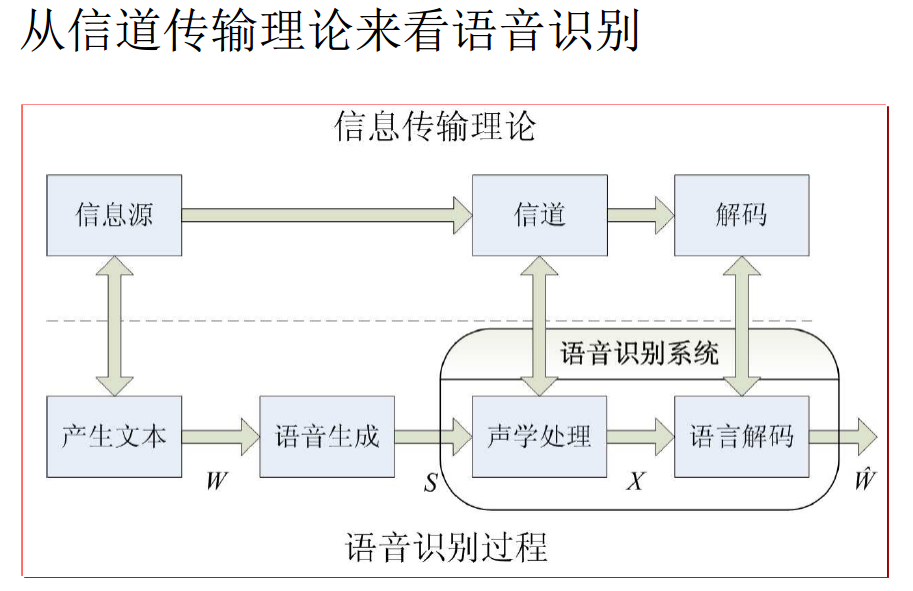
语音识别基本原理
贝叶斯统计建模框架(MAP/最大后验概率决策准则)
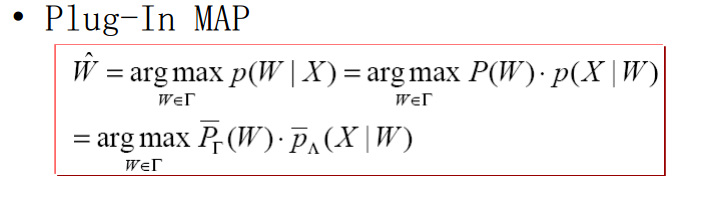

声学特征提取
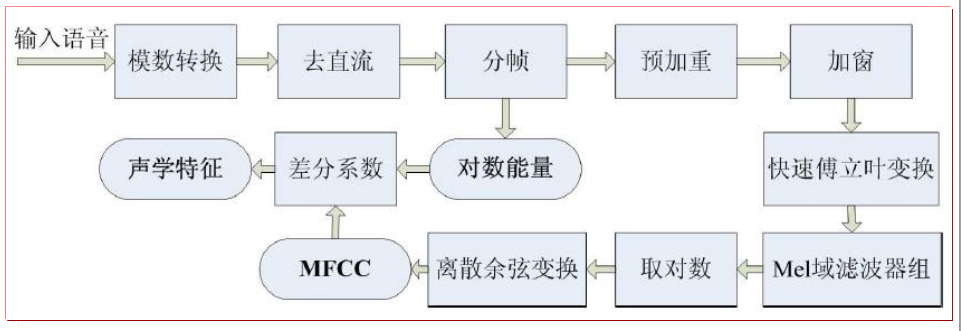
简单来说, x是一个帧序列,而每帧就是一个多维向量
声学模型
声学单元应该具有的特性
• 一致性:不同语音实例中相同的语音单元在声学上一致
• 可训练性:建模单元需要足够的训练数据来进行参数估计
• 可共享性:不同的建模单元之间共享某些具有共性的训练数据
• 声学单元如何挑选?
• 句子(sentence): 科大讯飞实验室
• 单词(word): 科大-讯飞-实验室
• 单字(syllable): 科-大-讯-飞-实-验-室
• 音素(phone): k-e-d-a-x-un-f-ei-sh-i-y-an-sh-i
• 考虑协同发音的三元音素(tri-phone):ei-sh+i和an-sh+I
• 精细建模和训练数据量之间的矛盾如何解决?参数绑定
• 声学单元对应的模型形式应该是什么?
• 隐Markov模型(HMM),神经网络(NN)
Markov过程和Markov链
• 描述了一个最小记忆系统的随机行为
/**安德雷·安德耶维齐·马尔可夫**/
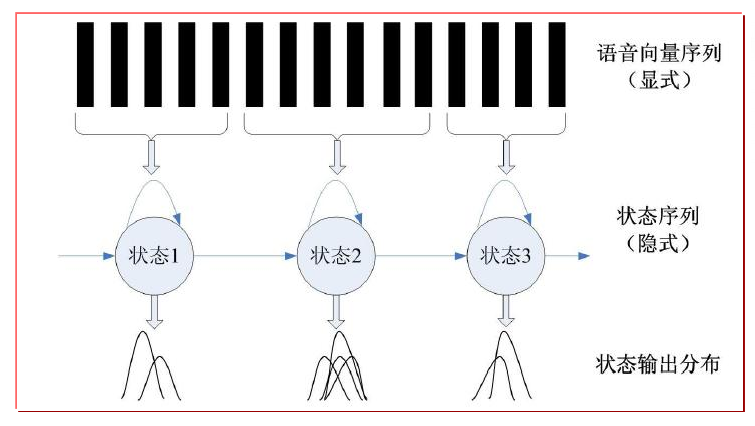
• HMM的几要素

HMM的两假设
1、一阶Markov假设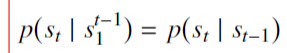
2、输出无关假设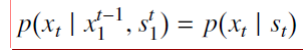
HMM的三个问题
• 评估问题
• 给定HMM模型参数以及一串观测序列,如何求得观测序列的似然度
• 解码问题
• 给定HMM模型参数以及一串观测序列,如何搜索出最优的状态序列
• 训练问题
• 给定观测序列,如何得到模型参数
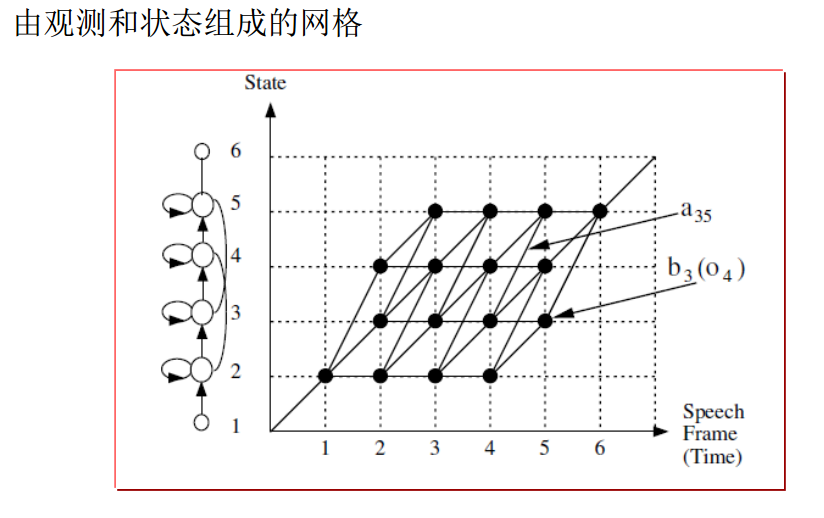
评估问题
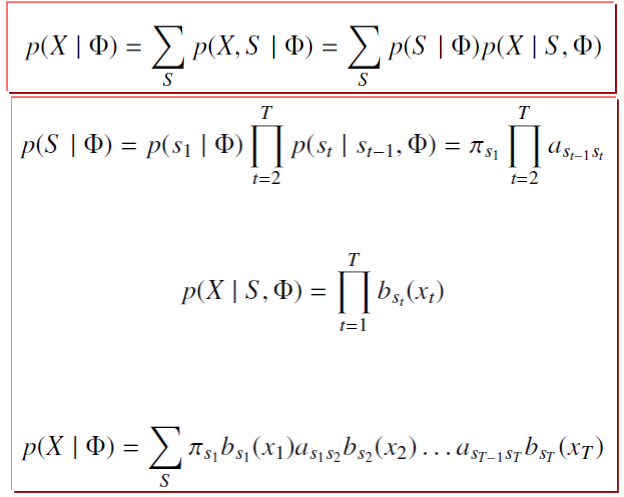
运算量太大,需要寻找快速算法—前向算法(Forward Algorithm)

解码问题—Viterbi算法

训练问题—最大似然估计
• EM算法( Expectation-Maximization Algorithm)
• Baum-Welch算法/前后向算法(Forward-Backward )
语言模型

解码搜索
• Viterbi算法
• 时间同步和时间异步
• 搜索空间裁减
• N-best和Word-Graph
• 对于命令词/孤立词识别网络,情况要简化很多
• 对于每条命令词先扩展成HMM序列,然后计算得分
• 选择得分最大的作为识别输出结果
语音识别的难点及其他相关技术介绍
• 说话人的差异
• 不同说话人:发音器官,口音,说话风格
• 同一说话人:不同时间,不同状态
• 噪声影响
• 背景噪声
• 传输信道,麦克风频响
• 鲁棒性技术
• 区分性训练
• 特征补偿和模型补偿

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









