






 本文详细介绍了Hadoop MapReduce框架的基础案例,通过具体步骤演示如何使用MapReduce进行大数据处理,包括集群启动、数据源准备、Mapper与Reducer实现,以及作业测试运行。
本文详细介绍了Hadoop MapReduce框架的基础案例,通过具体步骤演示如何使用MapReduce进行大数据处理,包括集群启动、数据源准备、Mapper与Reducer实现,以及作业测试运行。

Hadoop MapReduce基础案例
MapReduce:Hadoop分布式并行计算框架
思想:分治法
通俗解释
工厂给客户交付货物1000吨,卡车A运量50吨,需要顺序20次,如果平时客户不忙20次运输所需的时间客户能够接受,突然市场竞争激烈,工厂为了提供失效,每次运输从单台卡车运输提高到20台卡车运输,这样整个运量1次就搞定,Map Reduce类似,就是将一些廉价机器组成一个集群,每个节点都处理整个作业的一部分,最后进行汇总,从而快速提高大数据的处理能力
MapReduce工作流程图
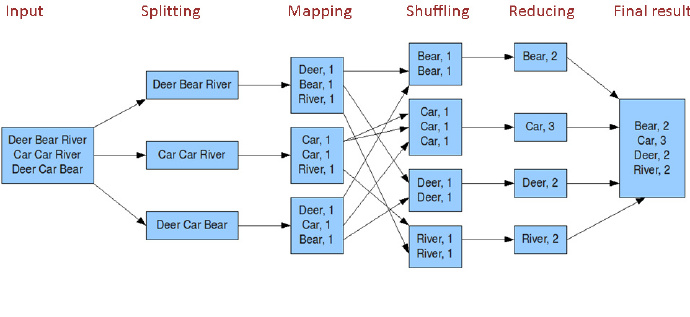
Maprreduce工作流程
HDFS提供数据源,经过splitting将数据切割成数据片,表示为K-V数据模型作为Mapping的输入,Mapping对数据进行进一步的处理,并形成客户需要的数据K-V数据模型,Shuffing对Mapping产生的K-V数据模型根据key进行排序汇总,然后将数据传给Reduce作业,reduce对key-ValueList进行相应的处理,最终汇总出最终的结果
基础案例:统计文本中出现的单词及个数wordcount
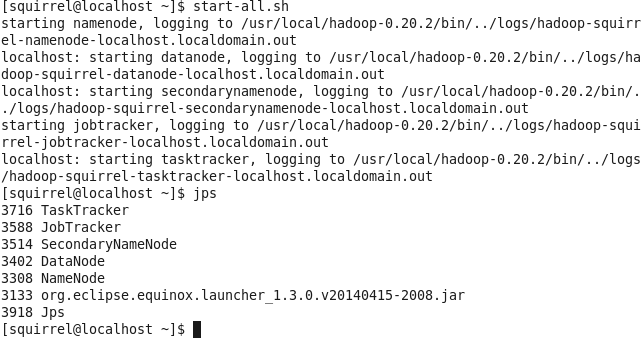
① :启动Hadoop集群:start-all.sh
② :准备测试的数据源
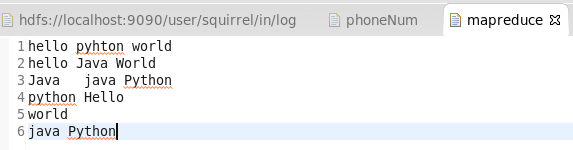
HDFS的存储目录
③ :创建Mapper:数据分割
package mapreduce;
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class WcMapper extends Mapper<LongWritable,Text,Text, IntWritable>{
@Override
public void map(LongWritable key,Text value,Context context) throws IOException, InterruptedException{
String line = value.toString();
StringTokenizer st = new StringTokenizer(line); //分词工具类
while(st.hasMoreTokens()){
String word = st.nextToken(); //获取单词信息
/**
* 将数据写入shufer过程,用于reduce的结果合并
* new Text(word):作为key
* new IntWritable(1):作为value,reduce会对其进行合并
*/
context.write(new Text(word), new IntWritable(1));
}
}
}
Mapper泛型参数解释:
-
LongWritable,Text,Text, IntWritable
-
LongWritable:Hadoop序列化的类型,可理解成Long的包装类,这里表示splitting Data的编号,hadoop默认按照”行”进行数据切割,这里可以近似理解为第N行
-
Text:表示输入数据的格式:这里文件中存放的是字符串,使用Text
-
Text:表示map函数输出的key的类型,因此是单词计数,所以是单词为key,Text类型
-
IntWritable:表示map函数的输出的value的类型,这里表示单词出现的次数
-
context.write(new Text(word), new IntWritable(1)); 表示每次出现一个单词就向shuffling输出数据:单词及次数1,也就是说每次单词出现一次就输出1
④ :创建Reducer:数据汇总
package mapreduce;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class WcReducer extends Reducer<Text, IntWritable, Text, IntWritable>{
@Override
protected void reduce(Text text, Iterable<IntWritable> iterable,
Reducer<Text, IntWritable, Text, IntWritable>.Context context)
throws IOException, InterruptedException {
int sum = 0;
for(IntWritable intWritable:iterable){
sum = sum+intWritable.get();
}
context.write(new Text(text), new IntWritable(sum));
}
}
Reducer泛型参数解释:
- Text, IntWritable, Text, IntWritable
说明Mapper传递参数和Reducer的输出参数是字符串和整型,对应单词和单词次数
reduce方法形参解释
- Text:表示Mapper传递的Key的值
- Iterable:表示Mapper传递的Key对应的值列表
例如:Map传递的值可能是片段
zhangsan 1
zhangsan 1
Map过后进入shuffling过程,shuffling会将Mapper的数据进行汇总,变成类似形式 zhangsan{1,1},也就是key-valueList数据模型,然后将其传递给reduce函数
int sum = 0;
for(IntWritable intWritable:iterable){
sum = sum+intWritable.get();
}
context.write(new Text(text), new IntWritable(sum));
对valueList集合中的值进行汇总,得到单个单词的累计出现次数
⑤ :创建Job测试类:Job作为Mapreduce作业的启动类,主要是将作业交给JobTracker,JobTacker通过调度Hadoop集群中的taskTracker进行作业处理
package mapreduce;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
/**
*运行mapreduce作业:mapreduce打成jar包
*控制台运行:hadoop jar jar包路径 JobRun类即可运行
*
*MapReduce web访问端口:50030
*/
public class WcJobRun {
public static void main(String[] args) {
Configuration conf = new Configuration();
conf.set("mapred.job.tracker", "localhost:9001");
try{
Job job = new Job();
job.setJarByClass(WcJobRun.class); //设置启动作业类
job.setMapperClass(WcMapper.class); //设置Map类
job.setReducerClass(WcReducer.class);
job.setMapOutputKeyClass(Text.class); //设置mapper输出的key类型
job.setMapOutputValueClass(IntWritable.class); //设置mapper输出的value类型
job.setNumReduceTasks(1); //设置Reduce Task的数量
//设置mapreduce的输入和输出目录
FileInputFormat.addInputPath(job, new Path("/user/squirrel/in"));
FileOutputFormat.setOutputPath(job, new Path("/user/squirrel/out") );
//等待mapreduce整个过程完成
System.exit(job.waitForCompletion(true)?0:1);
}catch(Exception e){
e.printStackTrace();
}
}
}
⑥ :MapReduce作业测试运行
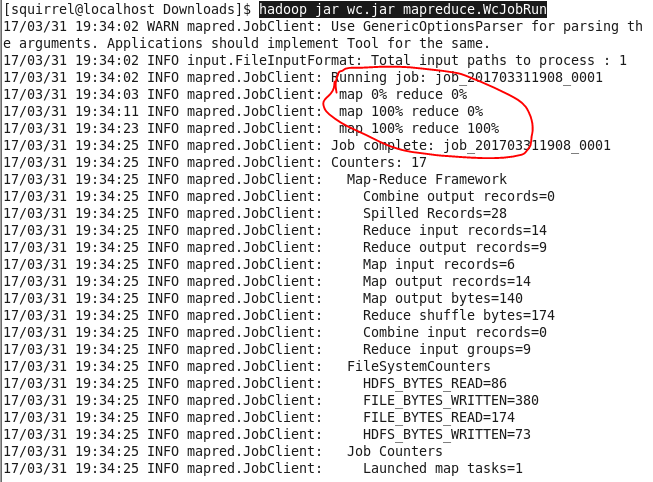
Eclipse将相关类打包为jar文件,通过”hadoop jar 包名 job类名”运行mapreduce作业 命令:hadoop jar wc.jar mapreduce.WcJobRun
控制台日志:
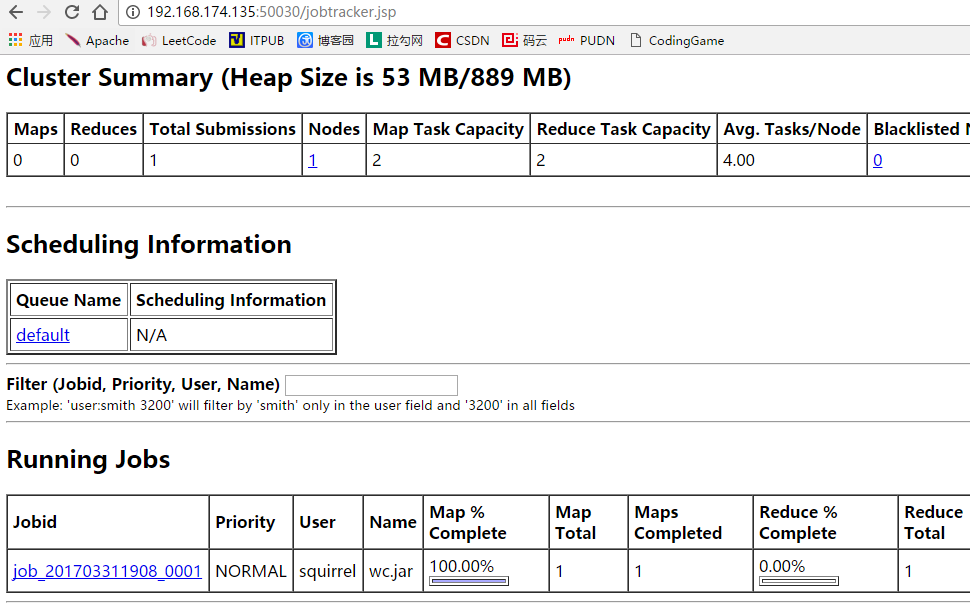
web监控mapreduce作业过程:http://192.168.174.135:50030
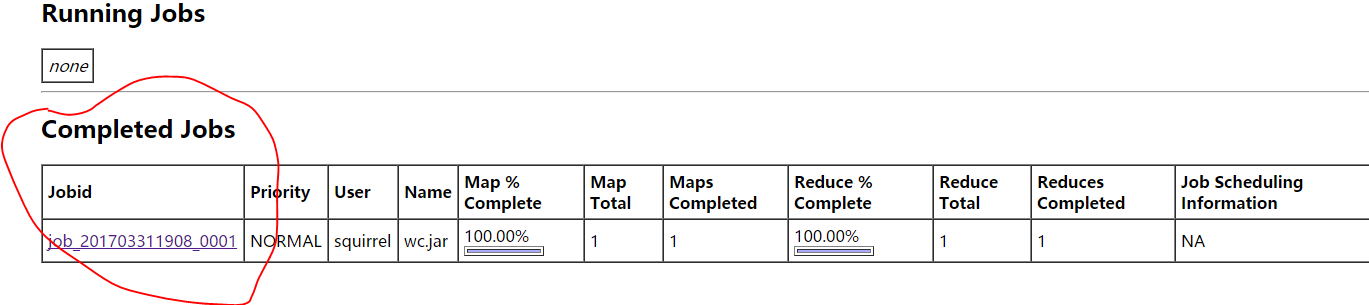
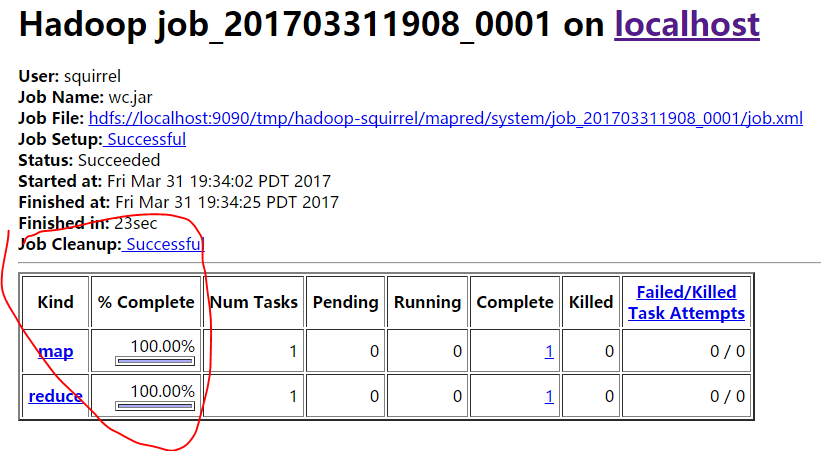
查看MapReduce处理之后的文件:注意存储在HDFS文件系统上
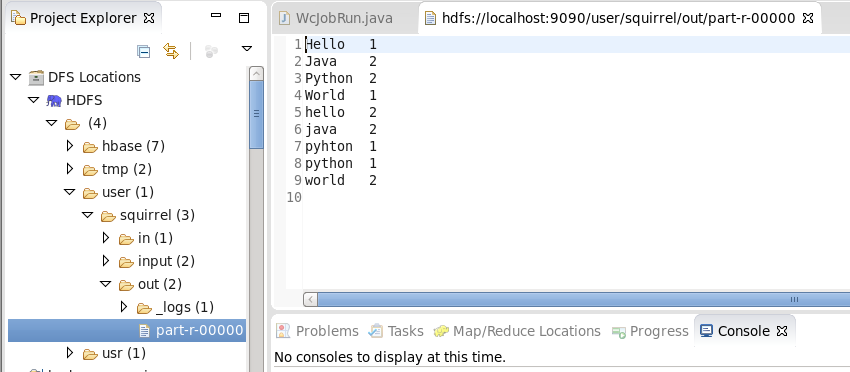
注意:
MapReduce结果的存放目录之前不能够在HDFS文件存在,否则抛出异常,如果想提高MapReduce作业的灵活性完全可以将Job类的HDFS输入和输出路径引用为main方法的形参args[0]、args[1],通过”hadoop jar wc.jar mapreduce.WcJobRun HDFS输入路径 HDFS输出路径”处理即可

















 839
839

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









