






 本文介绍了大数据融合的概念及其独特需求,探讨了大数据融合对象的独特性,包括多元性、演化性、真实性和隐含性等特性。
本文介绍了大数据融合的概念及其独特需求,探讨了大数据融合对象的独特性,包括多元性、演化性、真实性和隐含性等特性。
本节书摘来自华章出版社《大数据管理概论》一书中的第2章,第2.2节,作者 孟小峰,更多章节内容可以访问云栖社区“华章计算机”公众号查看
2.2 大数据融合的概念
众所周知,大数据价值链是一个阶梯式循环过程:“离散数据→集成化数据→知识理解→普适机理凝练→解释客观现象、回归自然”,每一个链条是对大数据的一次价值提升。为了实现这一价值,我们提出了大数据融合的概念,它是获取高品质知识、最大程度发挥大数据价值的一种手段,它的重要性毋庸置疑。但是,大数据的特征已经发生变化,人们对数据的需求也从多源集成提供丰富的数据上升到需要呈现多维度、多粒度、动态演化知识的新阶段。所以,大数据融合必然有其独到之处。
2.2.1 大数据融合需求的独特性
21世纪初,人们为了利用深网中丰富、专业的数据,开发了深网数据集成[13],集成多个数据源使之成为领域性专用知识库。到了大数据初期,数据繁杂、增长速度快[23],为了实现智能化语义检索[17],人们又开发了各种各样的知识库,如DBpedia、YAGO、Freebase、Probase[24]等。但是,当下为了缓解数据的无限性、知识的零散性与用户需求无法满足之间的矛盾,需要把数据变成有上下文意义的灵活的数据结构,实现数据智能,最大限度地提升大数据的价值,进而实现社会智能,必须要有新的融合方式,此即大数据融合。大数据融合不同于以往的数据融合,它不仅需要对数据进行融合,还需要对得到的集成化数据进行理解,更需要将理解的结果反馈给融合过程,提升融合的效率和准确性。
下面用一个排查犯罪嫌疑人的小案例来说明这种需求的独特性。可用线索:①嫌疑人A在作案后潜逃,但他在犯罪现场留下了脚印等少量犯罪证据;②作案前,人员B与A一起生活了40年,房产权归A所有,并且,B与A经常通话;③案发前,A与D一起来过作案现场几次,期间他们频繁通话;④案发后,A消失,但在另外一个地方出现了人员C,C在ATM机上对A的银行卡有过取款记录;⑤案发后,C与D有密切联系,并与D一起住了几次旅馆;⑥之后C还去过B的住宅并与B有过通信;⑦C与D的交通违章照片在微博、微信等社交媒体上频繁转播;⑧公安部门以往卷宗中记录D有犯罪前科。这些数据以及涉案相关人员与嫌疑人A的关系如图2-1所示。
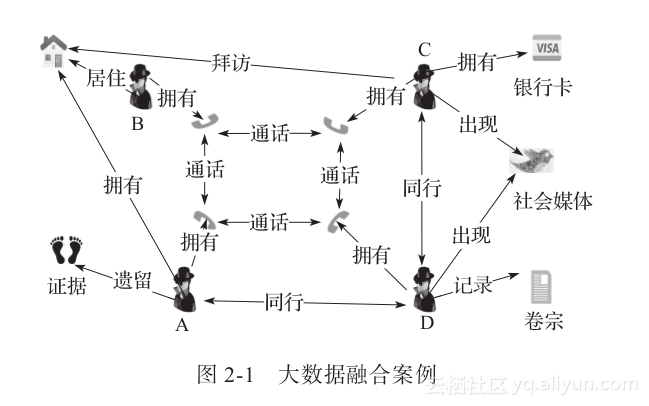
图2-1中关系看似简单,但它涉及8个不同的数据源,分别是房产局的房产登记数据、电信运营商的手机入网数据和通话记录数据、派出所提供的身份证号、银行提供的卡号和交易信息、客运站提供的旅客出行数据、旅店提供的住宿数据、公安部门提供的案犯卷宗信息,以及社交媒体上抽取的新闻数据等。这些数据是跨媒体的,有记录型的、文本型的,还有图片和视频。并且根据图2-1案例数据,我们可以得到以下信息:数据1中的脚印数据可以判断A的大概身高和体重,这里主要用到历史数据分析归纳出的普适知识。数据2暗含了A与B可能是亲属关系。数据3暗含了A与C可能是共犯。由数据4可以判断出C拥有A的银行卡和密码。由数据3~5可以判断A与C很可能是同一个人。数据7中C的体型数据可以与经过理解的数据1比较得出A与C极有可能是同一个人,数据6更加确定A与C是同一个人。
由上述案例我们可以看出,大数据融合意义重大,但也任重道远,它所面临的问题空前复杂化,表现如下。
1)割裂的多源异构数据:目前需要处理的数据可能来自领域数据库、知识库或者Web页面的开放信息,从来源角度看是多源异构的。而且,这些数据被物理地存放在不同的系统中。这些割裂的多源异构数据造成了各种“数据孤岛”,给大数据分析处理带来非常大的挑战,需要把这些割裂的数据整合到统一的系统中。
2)数据规模与数据价值的矛盾:当下,越来越丰富的数据提供了更多有价值的信息,同时数据的规模也越来越大,这对已有的数据存储和处理方法提出了挑战,需要对融合的规模进行控制。就像案例中所述,如果办案时相关数据越多就越有可能快速破案。但是,目前需要处理的数据规模已经让业界无法承受。
3)跨媒体、跨语言的关联:需要处理的数据有结构化数据、半结构化数据和非结构数据,这对数据关联的发现提出了挑战,尤其是图片、视频、音频数据与文本数据的关联。这种情况在公共安全领域极为常见,如何自动识别它们之间的关联是工程实际中亟待解决的问题。并且数据可能源于多语种,如学术领域提到的同一作者可以发表中文、英文论文。
4)实体和关系的动态演化:数据是动态变化的,实体和关系也是随时间不断演化的,这就增加了实体和关系的判别难度,容易造成数据不一致。比如,公共安全领域涉及的嫌犯在作案后更改姓名,学术领域中作者更换了所在单位等都属于此类情况。因此,需要合理建模演化行为,保证数据一致性。
5)跨领域、跨行业的知识传播:大数据是复杂的,各领域各行业的大数据也是有所不同的,但是所用的知识原理、处理方法是相通的,可以相互借鉴,比如可以用布朗运动的知识刻画鱼类中掠食者在食物富集时的运动轨迹。所以,大数据融合需要跨领域的知识学习和跨行业体系的知识复用。
6)知识的隐含性:从案例中我们也可以发现,隐式关系比显式知识更重要。例如两个嫌疑人在案发前同时出现在案发现场,那么他们很有可能是共犯;又如一个嫌疑人的突然消失和另一个嫌疑人的突然出现很可能暗含着嫌疑人是利用了身份洗白技术等。这种隐含的关系对知识的理解和数据的融合都有很大帮助,但是这些隐式知识的获取需要对相应数据作大量分析、深层次理解和抽象归纳。
2.2.2 大数据融合对象的独特性
当下数据驱动的电信、社交媒体、生物医疗、电子政务商务等各种各样的领域都在产生着大数据,人们也期望从这些数据中分析和抽取出价值。随着大规模数据关联、交叉和融合,将不同数据链接和融合会使数据的价值爆炸性地增大。但是大数据融合在多个维度上不同于传统数据集成,主要是因为大数据不再简单呈现为3V——海量性(Volume)、高速性(Velocity)、类型多样性(Variety)——特征[23],除了海量性和高速性,还呈现出了更复杂的特征[17,25]。
1)多元性:是指数据在内容、类型和语义上的不同维度和粒度大小,不同于传统数据的多样性。传统多样性强调的是类型多样[23],如数据源类型多样、数据类型(结构化、半结构化、非结构化)多样等。当下数据不仅是类型多样,更显著的是数据内容的“维度”多样和知识范畴的“粒度”多样,呈现出一种多元性。例如数据的全属性值、部分属性值以及数据附含语义后形成的长数据、精细化数据,或者考虑数据之间关联关系和背景知识后形成的话题、事件等。也就是说,多元性更加强调的是数据所包含的语义,即语义的维度和粒度。多元性与演化性成为当下大数据的精髓,是区别于大规模数据、海量数据或早期“大数据”(量大)的最显著特征。
2)演化性:是指数据的含义随时间或解释的变化而变化的一种特性,体现了数据的动态性和知识的演变性。例如实体的某些属性在不同时间点可能产生变化,以教师为例,他的职称可能在某个时间点从副教授升为教授;或者以话题、事件为例,它的故事情节随时间不断演变发展等。这就要求合理建模演化行为,保证数据一致性。但是演化一般都是一个渐进和相对平滑的过程,比如一些属性演化,但是其他属性不一定发生变化;或者实体属性值在短期内进行演化,这些属性值上的变化通常不会很奇怪。这些特征为演化建模提供了依据。另一方面,演化性与高速性共同构成了知识的动态演化性,更加贴切地体现出现实数据的本原性,而非单纯地强调速度,但是数据的演化不可避免地会增加大数据融合中多元性的处理难度。
3)真实性:是指由数据的不一致、数据表示和数据语义引起理解歧义的一种特性,主要由实体的同名异义表示和异名同义表示以及关系的变化引起。例如同一概念信息“Departure Time”在不同数据源中表示非常不同,在有的数据源中表示实际出发时间,而在有的数据源中表示计划出发时间;又如不同概念信息——动物“python”和编程语言“python”——却在动物数据源和图书数据源中采用相似的表示,即都用“python”表示。由于数据源具有自治性,所以这种现象普遍存在,它们增加了理解的不确定性。为了融合来自不同数据源的数据,我们需要解决这种数据语义和表示上的歧义性以及数据源自身之间的不一致性。可以说真实性由数据的不一致和演化性引起,反过来又为不一致和演化性提供了印证,只有知识得到印证才能使演化更新和融合更有意义。
4)隐含性:是指数据内部暗含的一些规律、知识,或者数据之间隐藏的一些关系,但从数据表面无法获知,需要从数据的语义层面理解、分析、归纳或抽象才能得到的一种特性。最简单的例子是语境词中暗含的语义,比如“Premiere Lincoln”中语境词“Premiere”表明“Lincoln”在这里指电影,而单个词“Lincoln”则无法判断它到底指什么,这种词语词之间的语义相关性对于发现浅层的隐含性是非常重要的。复杂一点的例子,例如鱼类中的掠食者在食物富集时运动轨迹呈布朗运动,或者“合作者”关系可能暗含“师生”关系等,这些只能通过对大量数据的分析、归纳、理解或抽象才能得到。从2.2.1节的案例中我们也可以发现,除了显式知识,还有更多的隐式知识,并且隐式知识比显式知识更重要。这种隐含性是当下大数据的显著特征,是普适性发现的基础。
5)普适性:是指在认知范围内可以达成共识关系的特征,这种特征有时候是通过大量显式知识的共现得到的,例如,“老师”和“蜡烛”频繁共现,所以它们在神经元连接上具有了普适性。但是,大部分是通过对隐式知识进行深层次语义理解、分析、归纳或抽象得到的。比如,鱼类中的掠食者在食物富集时运动轨迹呈布朗运动,或者“师生”关系可能暗含在学术论文的合作者“关系”中等。这种普适性发现源于知识之间隐性关联的发现,是将大数据定位到知识层面的一个独特特征,它比信息本身的增长更有价值,主要表现在数据的分布规律、结构规则,以及数据之间的关联模式上。看几个数据分布规律和结构规则方面的简单例子,例如众所周知的实体与实体之间普遍存在的二元关系,以它为原子单位可以将知识图谱表示为<实体,关系,实体>三元组的形式。数据之间的关联模式方面,利用词向量空间、词汇的语义关系和句法关系中平移不变现象这种普适知识,可以将知识图谱三元组中的实体、关系映射在一个语义空间上的隐性向量,然后用向量之间的转换关系(translation)来表示三元组,这个向量的每个维度所代表的含义人们无法解释,只能用于机器计算,但是它可以准确表述这种数据之间的关系。这种例子举不胜举,这里就不再赘述。
6)冗余性:是指数据的重叠。在很多情境下,单一的数据源可能包含大规模的数据,如社交媒体、电信网络以及金融等。并且,单个领域中很可能包含大量数据源,从不同数据源得到的数据通常存在着部分重叠,因而导致要被融合的大量数据之间存在巨大的数据冗余。这种冗余也是造成大数据海量性的一个原因,但是另一方面,它可以有效地处理大数据融合中数据真实性带来的挑战。直观地,如果仅有几个数据源提供有重叠的信息,而数据源对某数据项提供的值是有冲突的,则很难确信地判断出真值。但是如果存在大量重叠信息,则可以使用复杂的语义分析技术来发现真值。同时,它也可以解决多源异构数据源带来的挑战,比如借助它可以找到数据源模式之间的属性匹配,这在模式对齐中至关重要。直观地,如果一个领域存在很大程度的数据冗余,其实体和数据源的二分图具有良好的连通性,则可以从一组已知的种子实体出发,使用搜索引擎的技术发现该领域内的大部分实体[17]。当这些实体在不同的数据源有不同的对应模式时,我们就可以很自然地找到不同数据源所使用的模式之间的属性匹配。
所以,当下大数据融合的对象已经不单是数据,而是数据和知识的复合体。大数据的融合更应注重建立数据间、信息间和知识片段间多维度、多粒度的关联关系,实现更多层面的知识交互。

















 1238
1238

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









