



 本文详细介绍Hadoop集群的搭建过程,包括三台机器的角色分配、SSH免密登录配置、JDK安装与环境变量设置、Hadoop配置文件编辑、数据目录创建、环境变量配置分发、Hadoop格式化及启停、MapReduceJob运行测试等关键步骤。
本文详细介绍Hadoop集群的搭建过程,包括三台机器的角色分配、SSH免密登录配置、JDK安装与环境变量设置、Hadoop配置文件编辑、数据目录创建、环境变量配置分发、Hadoop格式化及启停、MapReduceJob运行测试等关键步骤。
基础配置
三台机器上编辑/etc/hosts配置文件,修改主机名。
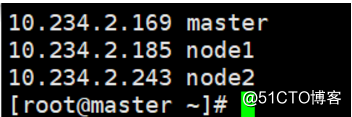
三台机器在集群中担任的角色:
- master:NameNode、DataNode、ResourceManager、NodeManager
- node1:DataNode、NodeManager
- node2:DataNode、NodeManager
配置ssh免密登录
# 三台机器上分别执行,互相免密登录
ssh-keygen -t rsa
ssh-copy-id -i ~/.ssh/id_rsa.pub node1
ssh-copy-id -i ~/.ssh/id_rsa.pub node2安装JDK
# 官网下载
https://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
http://anchnet-script.oss-cn-shanghai.aliyuncs.com/oracle/jdk-8u171-linux-x64.rpm
yum localinstall jdk-8u171-linux-x64.rpm -y配置java环境变量
# 三台均操作
vim /etc/profile
JAVA_HOME=/usr/java/jdk1.8.0_171-amd64
JAVA_BIN=/usr/java/jdk1.8.0_171-amd64/bin
JRE_HOME=/usr/java/jdk1.8.0_171-amd64/jre
export PATH=$JAVA_HOME/bin:$JRE_HOME/bin:$PATH
# source命令加载配置文件,让其生效
source /etc/profileHadpop配置分发
下载hadoop
https://www.apache.org/dist/hadoop/common/
wget https://www.apache.org/dist/hadoop/common/hadoop-2.6.5/hadoop-2.6.5.tar.gz解压
tar -zxvf hadoop-2.6.5.tar.gz -C /data/modules查看hadoop目录结构
cd /data/modules/hadoop-2.6.5/ 
- bin目录存放可执行文件
- etc目录存放配置文件
- sbin目录下存放服务的启动命令
- share目录下存放jar包与文档
配置hadoop环境变量
vim ~/.bash_profile
export HADOOP_HOME=/data/modules/hadoop-2.6.5/
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
source !$编辑hadoop配置文件
- 编辑etc/core-site.xml
<configuration> <property> <name>fs.default.name</name> <value>hdfs://10.234.2.169:8020</value> # 指定默认的访问地址以及端口号 </property> - 编辑etc/hdfs-site.xml
<configuration> <property> <name>dfs.namenode.name.dir</name> <value>/data/hadoop/app/tmp/dfs/name</value> # namenode临时文件所存放的目录 </property> <property> <name>dfs.datanode.data.dir</name> <value>/data/hadoop/app/tmp/dfs/data</value> # datanode临时文件所存放的目录 </property> - 创建数据目录
mkdir -p /data/hadoop/app/tmp/dfs/name mkdir -p /data/hadoop/app/tmp/dfs/data - 编辑etc/yarn-site.xml
<configuration> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.resourcemanager.hostname</name> <value>master</value> </property> </configuration> - 编辑etc/mapred-site.xml
cp mapred-site.xml.template mapred-site.xml vim !$ <configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> # 指定mapreduce运行在yarn框架上 </property> </configuration> - 配置从节点的主机名etc/slaves
node1 node22台node节点也需创建对应安装目录,环境变量配置等
scp ~/.bash_profile node1:~/.bash_profile
scp * node1:/data/modules/hadoop-2.6.5/etc/hadoop/
# 2台节点上如下操作
source ~/.bash_profile
mkdir -p /data/hadoop/app/tmp/dfs/name
mkdir -p /data/hadoop/app/tmp/dfs/dataHadoop格式化及启停
对NameNode做格式化,只需要在master上执行即可
[root@master hadoop]# hdfs namenode -format
# 格式化是对HDFS这个分布式文件系统中的DataNode进行分块,统计所有分块后的初始元数据的存储在NameNode中格式化之后就可以启动Hadoop集群
# sbin目录下,执行脚本,执行后要输入master服务器的密码
[root@master hadoop]# ./start-all.sh查看机器进程
- master
[root@master sbin]# jps 19237 SecondaryNameNode 22231 NodeManager 21978 ResourceManager 19019 NameNode 30941 Jps 21327 DataNode # 如果master上的某些服务进程未启动,需要再次手动执行脚本启动 # 启动NameNode sbin/hadoop-daemon.sh start namenode # 启动DataNode sbin/hadoop-daemon.sh start datanode # 启动SecondaryNameNode sbin/hadoop-daemon.sh start secondarynamenode # 启动Resourcemanager sbin/yarn-daemon.sh start resourcemanager # 启动nodemanager sbin/yarn-daemon.sh start nodemanager - node
[root@node1 ~]# jps 25827 Jps 18742 DataNode 20583 NodeManager访问测试
访问主节点 50070
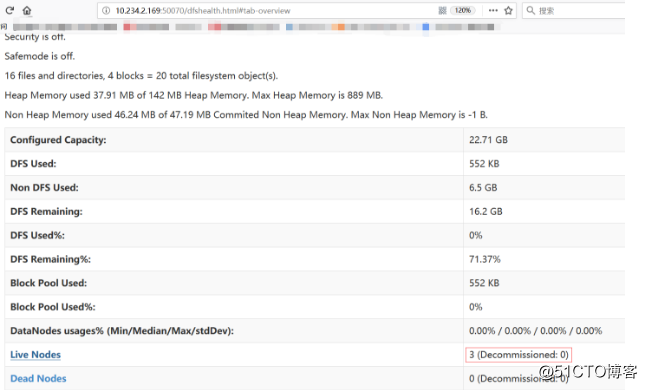
访问主节点 YARN的web页面
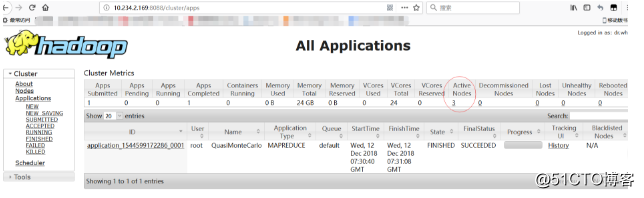
点击“Active Nodes”查看存活的节点
执行命令
hdfs dfs -ls / hdfs dfs -mkdir /test123 hdfs dfs -put ./test.sh /test123 # 然后去其他节点查看,不同的节点,访问的数据也是一样的 hdfs dfs -ls /运行MapReduce Job
在Hadoop的share目录里,自带了一些jar包,里面带有一些mapreduce实例小例子。位置在/data/modules/hadoop-2.6.5/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.5.jar
- 创建输入目录
bin/hdfs dfs -mkdir -p /test1/input # 原始文件 [root@master hadoop-2.6.5]# cat /data/hadoop/test1.input hadoop hadoop hive mapreduce hive storm sqoop hadoop hive spark hadoop hbase - 上传到HDFS的/test1/input目录中

- 运行WordCount MapReduce Job
[root@master hadoop-2.6.5]# bin/yarn jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.5.jar wordcount /test1/input /test1/output
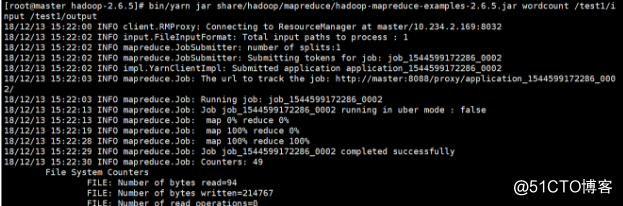
YARN web控制台查看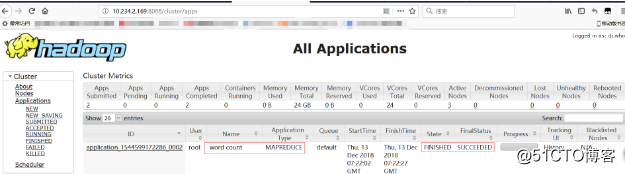
- 查看输出结果
[root@master hadoop-2.6.5]# hdfs dfs -ls /test1/output Found 2 items -rw-r--r-- 3 root supergroup 0 2018-12-13 15:22 /test1/output/_SUCCESS -rw-r--r-- 3 root supergroup 60 2018-12-13 15:22 /test1/output/part-r-00000 # output目录中有两个文件,_SUCCESS文件是空文件,有这个文件说明Job执行成功。part-r-00000文件是结果文件,其中-r-说明这个文件是Reduce阶段产生的结果。一个reduce会产生一个part-r-开头的文件。 # 查看执行结果 [root@master hadoop-2.6.5]# hdfs dfs -cat /test1/output/part-r-00000 hadoop 4 hbase 1 hive 3 mapreduce 1 spark 1 sqoop 1 storm 1 # 结果是按照键值排序好的 - 停止Hadoop
# 主节点上执行 stop-all.sh,如果进程未全部终止,就执行如下脚本对应停止。 [root@master hadoop-2.6.5]# sbin/hadoop-daemon.sh stop namenode stopping namenode [root@master hadoop-2.6.5]# sbin/hadoop-daemon.sh stop datanode stopping datanode [root@master hadoop-2.6.5]# sbin/yarn-daemon.sh stop resourcemanager stopping resourcemanager [root@master hadoop-2.6.5]# sbin/yarn-daemon.sh stop nodemanager stopping nodemanager
开启历史服务
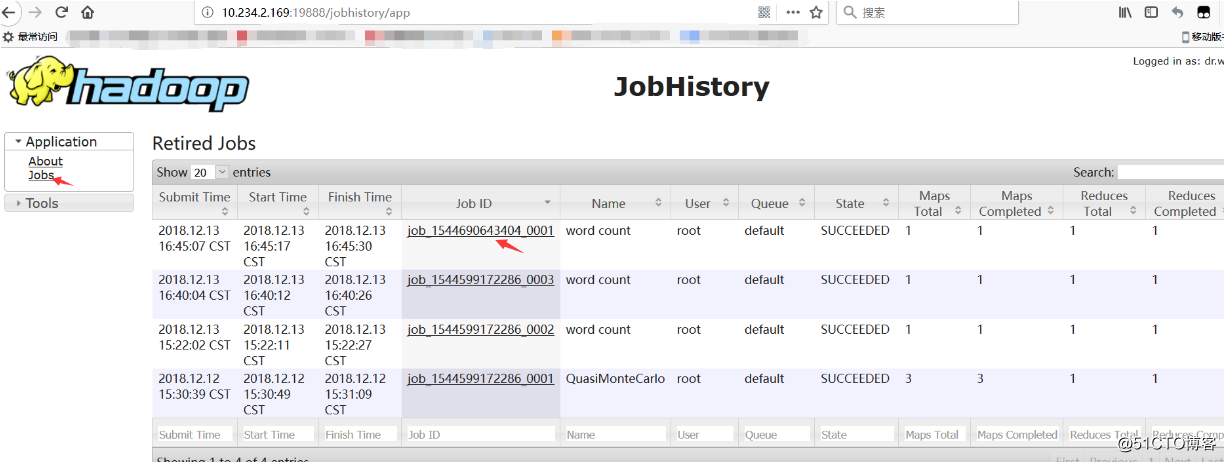
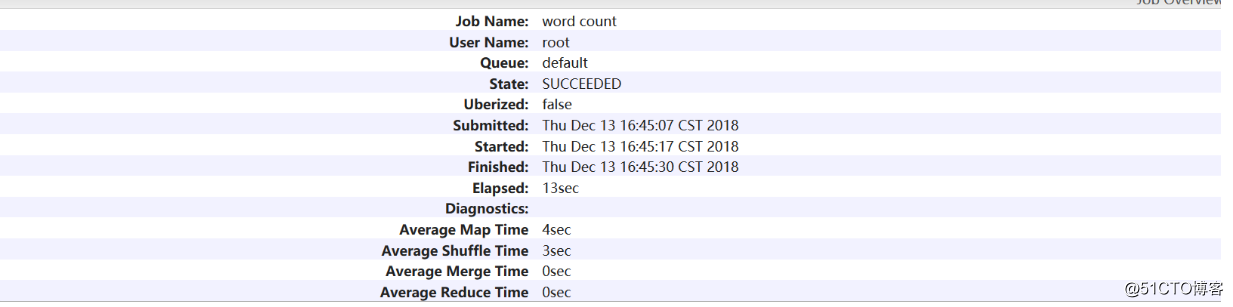
Hadoop开启历史服务可以在web页面上查看Yarn上执行job情况的详细信息。可以通过历史服务器查看已经运行完的Mapreduce作业记录,比如用了多少个Map、用了多少个Reduce、作业提交时间、作业启动时间、作业完成时间等信息。
- 开启日志聚集
# Hadoop默认是不启用日志聚集的。在yarn-site.xml文件里配置启用日志聚集。 <property> <name>yarn.log-aggregation-enable</name> <value>true</value> </property> <property> <name>yarn.log-aggregation.retain-seconds</name> <value>106800</value> </property> # yarn.log-aggregation-enable:是否启用日志聚集功能。 # yarn.log-aggregation.retain-seconds:设置日志保留时间,单位是秒。将配置文件发布到其他节点:
scp etc/hadoop/yarn-site.xml node1:/data/modules/hadoop-2.6.5/etc/hadoop/ scp etc/hadoop/yarn-site.xml node2:/data/modules/hadoop-2.6.5/etc/hadoop/重启Yarn进程和HistoryServer进程
sbin/stop-yarn.sh sbin/start-yarn.sh sbin/mr-jobhistory-daemon.sh stop historyserver sbin/mr-jobhistory-daemon.sh start historyserver - 测试日志聚集
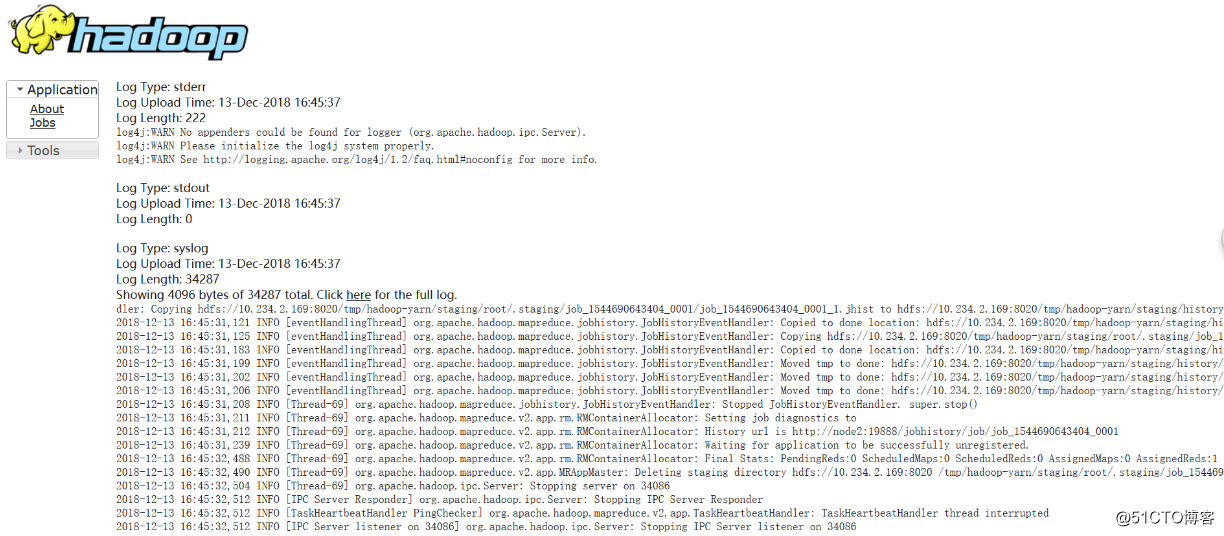
运行一个demo MapReduce,使之产生日志:[root@master hadoop-2.6.5]# bin/yarn jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.5.jar wordcount2 /test1/input /test1/output2 # 访问主节点的19888端口,运行job后就可以在web页面查看各个Map和Reduce的日志了。

转载于:https://blog.51cto.com/somethingshare/2381224

















 1414
1414

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









