






(一)buffer与cache的区别
buffer是缓冲区,数据被提前写入,以防止对系统产生冲击而设。
cache是缓存,为了缓和高速设备和低速设备之间而设。系统将一些中间结果置于此处,以加快访问速度。
(二)GNU和GPL
彼时Unix从免费转而收费,斯托曼同学非常生气,便创立了自由软件基金会,开展了GNU工程,试图建立一个新的操作系统,摆脱Unix。GPL协议是GNU的规则,规定了行为准则。
(三)Linux系统分区
常见分法:/boot(引导分区) 200M
swap(交换分区)当服务器内存<8G 服务器内存的1.5倍
当服务器内存>=8G 8G
/(根) 剩余容量
如果数据很重要:/boot(引导分区) 200M
swap(交换分区)当服务器内存<8G 服务器内存的1.5倍
当服务器内存>=8G 8G
/(根) 50-200G
/data 剩余容量
如果数据重要性未知:/boot(引导分区) 200M
swap(交换分区)当服务器内存<8G 服务器内存的1.5倍
当服务器内存>=8G 8G
/(根) 50-200G
/data 暂不分
交换分区:临时作为内存使用,类型于Windows的虚拟内存,防止因为内存不够导致系统故障。
(四)raid卡
就是磁盘阵列卡,统一管理磁盘,可以将多个磁盘拼接之后获得更高容量,速度更快,安全性更高。
raid0:至少需要1块磁盘,没有冗余,任何一块磁盘损坏都无法正常工作,安全性低,n块磁盘组成的阵列读写性能理论上是单块磁盘的n倍。适用于对性能要求高,安全性要求不高的场合。
raid1:至少需要两块磁盘,50%冗余,每两块磁盘为一组,任何一组磁盘损坏都无法正常工作,n组磁盘的读写性能理论上是单组的n倍。适用于对安全性要求较高,对性能要求不高的场合。
raid2/3/4:较少应用于实际工作场合,某些研究领域使用。
raid5:目前最常见的应用等级,原理与raid4相似,区别在于校验数据分布在阵列中的所有磁盘上,而没有采用专门的校验磁盘。对于数据和校验数据,他们的写操作可以同时发生在完全不同的磁盘上。所以raid5不存在校验盘的性能瓶颈问题。此外,raid5具备很好的扩展性,当阵列磁盘数量增加时,磁盘组的并发读写性能也随之增加。比raid4支持更多的磁盘,从而能获得更多的容量以及更高的性能。
raid5的磁盘上同时存储数据和校验数据,数据块和对应的校验数据存储在不同的磁盘上,当一个数据盘损坏时,系统可以根据同一条带的其他数据块和校验数据重建损坏数据。与其他raid等级一样,在重建数据的时候,raid5的性能会受到较大影响。
raid5兼顾性能、安全性和综合成本等多方考量,是目前综合性能最佳的数据保护方案。raid5可以满足大部分的存储应用需求,大部分的数据中心都采用它。
(五)虚拟机网络配置
centos6中,setup命令可调出网卡配置的图形界面。配置完后,可以通过ifdown eth0&&ifup eth0重启网卡。
ifconfig命令可以查看网卡的配置信息。
虚拟机的网络类型中,有NAT、桥接模式和仅主机模式。
在NAT模式中,可以实现最简单的连接互联网操作,只要宿主机能访问互联网即可。NAT模式下的IP地址是有系统的DHCP服务器来提供,因此IP和DNS一般设置成自动获取,也可手动配置。因此虚拟机无法同局域网中真实的主机进行通讯。
在桥接模式下,虚拟机相当于局域网中一台真实的机器,IP需要手动配置。虚拟机的地位和宿主机一样,所以它可以访问局域网当中的任何一台机器。只要配置好IP、网关、DNS等信息,虚拟机就可以通过局域网网关访问互联网。
在仅主机模式下,虚拟机的网络同外部网络是隔离的。虚拟机只能和宿主机互访,IP地址也是自动分配的。此时,虚拟机无法访问互联网。
(六)基础命令(1)mkdir 创建目录
-p:连父目录一起创建
(2)ls 显示目标列表
-l:以长格式显示详细信息
-a:显示所有文件,包括隐藏文件
-A:显示所有文件(除隐藏文件外)
-t:以文件和目录的更改时间排序
-r:逆序排序
-i:显示文件的inode号
-R:显示递归文件
-h:以人类可读方式显示
-d:仅显示目录名
-k:以kb为单位显示文件大小
-m:以‘,’分隔文件,按行显示
(3)cd 进入目录
cd ~ 回当前用户的家目录
cd - 回到上一次所在的目录
(4)pwd 显示当前位置,从根开始的就是绝对路径,否则是相对路径。
(5)touch 更新文件的时间戳,也可用于创建新文件。
(6)cat 查看文件内容
-n:在输出行前面加上行号
(7)echo 可将后面的内容显示在屏幕上
(8)向文件中追加多行的方式:
cat >>/data/oldboy.txt<<eof
i
love
littlefat
eof
eof是结束符
(9)> 等同于1>,标准输出流重定向正确的内容
等同于1>>,标准输出流追加重定向正确的内容
2>,标准错误输出流重定向错误的内容
2>>,标准错误输出流追加重定向错误的内容
2>&1,标准错误输出流追加重定向到前相同的文件
0:标准输入流
1:标准输出流
2:标准错误输出流
(10)cp 复制,(操作前备份,操作后检查。)
-r:复制目录及其下的文件,递归复制
-p:复制时保持属性不变
-d:当复制符号链接时,把目标文件或目录也建立为符号链接,并指向与源文件或目录相连接的原始文件或目录
-a:等同于-dpr
(11)mv 对文件或目录重新命名,或把文件从一个目录移到下一个目录。如果目标文件已经存在,则会被覆盖。如果目标是个目录,那么源文件会移过来。
(12)rm 删除
-d:删除目录
-r:递归删除,就是连子目录及其文件一起删除
-f:取消提示,强制删除
(13)find 在指定目录下查找文件
find /root/ -type f -name 'oldboy.txt'
位置 类型 名字
type:f 普通文件
d 目录
l 符合链接
-maxdepth 1:设置最大目录层级为1,即查找当前目录下的一级子目录
-mindepth 2:设置最小目录深度为2
-perm 644:查找符合644权限数值的文件或目录
-user root:查找属于root用户的文件或目录
-group root:查找属于root用户组的文件或目录
-size:查找符合指定文件大小的文件
实例1:否定参数 find /oldboy ! -name '.txt' 查找不是以txt结尾的文件
实例2:find . -maxdepth 1 -type f 查找当前目录下的一级目录
实例3:根据文件时间戳进行查找
Linux中每个文件有三种时间戳:
-atime:最近一次访问时间
-mtime:最近一次修改文件内容时间
-ctime:最近一次修改文件属性时间
单位是天,如要改成分钟请用-amin -mmin -cmin
find . -type f -mtime -7 查找7天内被访问的文件
find . -type f -mtime 7 查找恰好在7天前被访问的文件
find . -type f -mtime +7 查找超过7天被访问的文件
实例4:根据文件的大小进行查找
find . -type f -size -100k 查找小于100k的文件
find . -type f -size 100k 查找等于100k的文件
find . -type f -size +100k 查找大于100k的文件
实例5:删除找到的匹配文件
find . -type f '*.txt' -delete
选项的联合使用采用-a 并且需要用小括号框起来,括号需要转义
实例6:find (-size +1k -a -size -10m -a -mtime -7 -a -type f)
还可以在find命令后跟上-exec选项,可以对find命令找到文件进行处理。
实例7:find (-size +1k -a -size -10m -a -mtime -7 -a -type f) -exec rm -rf {} \;
{}用于匹配find找到的所有文件,\;是结束符
(14)head 取文件内容的前几行,默认10行
-n3:取文件内容的前3行
-c 10:显示文件头部10个字符
(15)tail 取文件内容的后几行,默认10行
-n3:取文件内容的后3行
-f:显示文件最近新追加的内容
-c 10:显示文件尾部10个字符
实例1:tail +20 /oldboy.txt 从第20行开始显示到行尾
(16)alias 查看系统的别名
自定义别名:rm='rm -i'
(17)将一个目录中的文件复制到另一个目录中时,发现有同名文件时,会提示是否需要覆盖。若想不出现提示,
方法一:在命令之前添加\
方法二:命令采用绝对路径,通过which可查询绝对路径
方法三:修改/etc/profile文件,将自定义的别名写入其中,再用source命令编译/etc/profile即可永久生效。同时/root/.bashrc中把相关的别名注释掉即可。
(18)sed 一种流编辑器,用于处理文件内容
sed命令的执行过程:读取文件的第一行,看是否满足判断条件,满足就执行。默认输出,会把内存中的结果输出到屏幕上,然后继续读取下一行。
常用功能:sed -n '/oldboy/p,/104/p' test.txt
/ /用于查找,p用于显示。
sed option 'command' file(s)
-n:取消默认输出
-i:直接编辑文件内容
-r:支持扩展正则
command中:
s:替换,如果不加g,则只替换第一个匹配的范本
g:全面替换
p:只打印替换的行
$:最后一行
实例1:查询指定的行:sed -n '20,30p' oldboy.txt 显示20行到30行的内容
实例2:sed -i 's#oldboy#oldgirl#g' oldboy.txt
将文本内容中所有的oldboy替换为oldgirl定界符可以使用任意符号,例如/ #
删除操作:d命令
实例3:sed '^$d' oldboy.txt 删除空行
sed '2,$d' file 删除第二行到末尾所有行
sed '/^test/'d file 删除文件中以test开头的行
已匹配字符串标记&
实例4:echo this is a test line | sed 's/\w+/[&]/g'
[this] [is] [a] [test] [line] 正则表达式 \w+ 匹配每一个单词,使用 [&] 替换它,& 对应于之前所匹配到的单词
子串匹配标记\1
实例5:echo aaa BBB | sed 's/([a-z]+) ([A-Z]+)/\2 \1/'
BBB aaa \1表示第一个被匹配到的,\2表示第二个被匹配到的
组合多个表达式
实例6:sed '表达式' | sed '表达式' 等价于:sed '表达式; 表达式'
选定行的范围:,逗号
实例7:sed -n '5,/^test/p' file 打印从第5行开始,到以test开始的行结束
实例8:追加行:sed '3a oldboy,ufo' test.txt 在第三行的下面追加一行
实例9:采用变量的方式替换,不能用单引号,只能用双引号
x=oldboy y=oldgirl
sed "s#$x#$y#g" test.txt
(19)管道| 将前面命令的标准输出流传送给后面的命令的标准输入流
| 与|xargs的区别:
前者将命令的执行结果当做标准输入流传给后面的命令
后者将命令的执行结果当做参数传给后面的命令
(20)df 查看磁盘分区使用情况
-h:以人类可读的方式展现
-i:查看inode使用情况
(21)free 显示当前内存使用和未使用的数目
-m:以mb为单位
(22)lscpu 显示CPU的详细情况
(23)w 显示已登录系统的用户列表,以及他们现在在干嘛
(24)rpm 包管理命令,曾是Redhat发行版用于管理其软件套件用的,后来陆续被其他发行版所采用
-a:查询所有软件
-q:使用询问模式,当出现任何问题时先询问用户
-i:安装指定的软件
-e:删除指定的软件
-v:显示指令执行过程
-h:软件安装时列出标记
-l:显示软件的文件列表
实例1:安装rpm软件包 rpm -ivh your-package.rpm
(25)tree 树状图显示目录
-d:只显示目录
-L 1:目录树的最大深度为1级目录
(26)grep 强大的文本搜索工具,支持正则表达式,并把匹配的行打印出来
-E:支持扩展正则表达式等同于egrep
-n:在匹配的行之前显示该行的编号
-o:只输出文件中匹配到的部分
-v:输出除之外的所有行
-c:计算符合范本的列数
--color==auto:标记颜色
-r:在目录中进行递归搜索
-q:静默输出,即不会输出任何信息
-e 'hello':指定字符串为查找的范本样式,可指定多个字符串
-A 3:除显示匹配的当前行之外,还显示其后的3行
-B 3:除显示匹配的当前行之外,还显示其前的3行
-C 3:除显示匹配的当前行之外,还显示其前的3行和其后的3行
实例1:在搜索结果中包含或排除指定文件
grep -r 'main' --include *.{php,html} 只在目录中所有PHP和HTML文件中搜索
grep -r 'main' --exclude 'readme' 在搜索时排除所有readme文件
实例2:-e匹配多个范本样式
echo this is a text line | grep -e "is" -e "line" -o
(27)awk 是一种强大的编程语言,能够处理数据以及文件的内容,可在命令行中使用,更多的是作为脚本使用。
执行过程:BEGIN初始化模块,读入第一行,判断条件,满足条件处理,读入第二行,继续判断...,END统计模块。
awk 参数 '模式{动作}' 文件
awk [options] 'script' var=value file(s)
-F:指定输入分隔符,分隔符可以是字符串或正则表达式
-v:赋值一个用户自定义变量,把外部变量传递给awk
$0:当前行的文本内容
awk是由模式和操作组成的,其中模式可以是下面任意一个:
正则表达式
关系表达式
模式匹配表达式
BEGIN语句块,PATTERN语句块,END语句块
模式中查找功能:使用/ /查找
awk '$2~/xiaoyu/{print $1,$2}' test.txt
~:表包含
awk '{gsub(/:/,"$",$4);print}' test.txt
gsub:替换函数 将:替换为$,而且只替换第四列,g的含义同sed表全面替换。
awk脚本基本结构:
awk 'BEGIN{commands} pattern{commands} END{commands}' file
BEGIN语句块、pattern通用模式语句块、END语句块三个是可选的。
工作流程:
先执行BEGIN语句块里的内容,然后对文件进行逐行扫描并执行pattern语句块内容,扫描完之后执行END语句块内容。如果pattern语句块没提供,则默认执行打印即{print}。
实例1:echo -e "A line 1nA line 2" | awk 'BEGIN{ print "Start" } { print } END{ print "End" }'
Start
A line 1
A line 2
当print参数以逗号为分隔符时,打印时以空格为定界符。在print语句中双引号被当做拼接符使用。
实例2:echo | awk '{ var1="v1"; var2="v2"; var3="v3"; print var1,var2,var3; }'
v1 v2 v3
实例3:echo | awk '{ var1="v1"; var2="v2"; var3="v3"; print var1"="var2"="var3; }'
v1=v2=v3
awk的内置变量:
FILENAME:当前输入的文件名
FS:字段分隔符,默认是任何空格
NR:执行过程中的当前行号
NF:执行过程中的当前字段数
实例4:awk '{print $2,$NF}' filename 打印每一行的第二和最后一个字段
实例5:seq 5|awk 'BEGIN{sum=0} {print $1"+";sum+=$1} END{print "等于",sum}'
1+
2+
3+
4+
5+
等于 15
将外部变量值传递给awk
实例6:var=1000
echo|awk -v VARIABLE=$VAR '{ print VARIABLE }'
实例7:var1="aaa"
echo | awk '{ print v1}' v1=$var1
设置字段定界符:默认的字段定界符是空格,可以使用-F ";"来指定新的定界符
实例8:调用外部应用程序system方法
awk 'BEGIN{a=system("ls -l /");print a}'
实例9:统计文件中空行的数量
awk '/^$/{i++;print i;}' test.txt
awk '/^$/{i++}END{print i}' test.txt
awk的运算和判断:
算术运算符:+ - / ++ -- !...
赋值运算符:+= -= = /= %= ...
逻辑运算符:&&与 ||或
关系运算符:< <= > >= != ==
其他运算符:$ 字段引用 ...
awk的数组、统计与运算 END一般用于统计
arr[10]="张三"
(28)chkconfig 查看、设置系统的服务
--level 3:指定服务要在哪一个运行级别里开启或关闭
--add:添加指定的服务
--del:删除指定的服务
--list:列出所有系统服务
实例1:如何增加一个服务
服务脚本必须存放在/etc/init.d下
chkconfig --add servicename 添加该服务
chkconfig --level 35 servicename on 在运行级别3和5下启动该服务
(29)echo 打印变量的值或输出指定字符串
-e:激活转义字符
使用-e之后,当字符串中出现以下字符时,会做特殊处理。
-n:取消结尾的回车换行
\a 发出警告声;
\b 删除前一个字符;
\c 最后不加上换行符号;
\f 换行但光标仍旧停留在原来的位置;
\n 换行且光标移至行首;
\r 光标移至行首,但不换行;
\t 插入tab;
\v 与\f相同;
\ 插入\字符;
\nnn 插入nnn(八进制)所代表的ASCII字符
(30)tar 打包文件或目录。打包和压缩是两个不同的概念,打包就是把一堆文件放在一个总文件里,而压缩则是把一堆文件经过压缩算法变成一个小文件。
-c:创建新的备份文件
-x:从备份文件中还原文件
-v:显示指令执行过程
-z:通过gzip指令处理备份文件
-t:查看备份文件的内容
-r:添加文件到已压缩的文件里
-f filename:指定备份文件
-C:用于解压缩,如果要解压至特定的目录使用这个选项
--exclude==<范本>:排除符合范本的文件
-N:只将比指定日期更新的文件打包
实例1:tar -cvf log.tar.gz /var/log 仅打包不压缩
tar -zcvf log.tar.gz /var/log 以gzip压缩
tar -ztvf log.tar.gz 查看压缩包的内容
tar -zxvf log.tar.gz 解压压缩包
tar -zxvf log.tar.gz -C /tmp/ 解压到指定目录
tar -N "2018/10/01" -zcvf log10.tar.gz /var/log
(31)wc 统计文件的字数、行数,如不给定文件,就从标准输入当中读取。
-l:只显示行数
-c:只显示字符数
-w:只显示字节数
(32)ps 查看当前系统的进程状态。
-A:显示所有程序
-e:同上
-f:显示UID、PPIP、C与STIME
-G<群组名称或群组识别码>:显示该群组下的所有程序
-U<用户名称或用户识别码>:显示该用户下的所有程序
-l:详细方式显示
(33)file 显示文件的类型
-b:不显示文件名称
-L:直接显示软链接所指向的文件或目录
(34)id 查看用户id和组id
-g:显示用户所属的组id
-G:显示用户所属的附加的组id
-u:显示用户id
(35)lsof 可以查看进程打开的文件,端口等信息
-g:列出GID号
-p:列出指定进程号所打开的文件
-u:列出UID号进程详情
-i 22:查看指定端口的进程占用情况
(36)stat 显示文件的状态信息
-t:以简洁方式输出
-L:支持符合链接
-f:显示文件系统状态而非文件状态
(37)history 显示历史命令,在命令行中,可以使用符号!2执行第二条历史命令
历史命令被保持在内存中,当退出或登录shell时,会被保持或读取。在内存中,最多保存1000条历史命令,这个数量是由环境变量HISTSIZE控制。
-c:清空当前的历史命令
n:打印最近的n条历史命令
(38)cat 显示文件的内容
-A:显示所有字符
-n:前面加上行号
-b:与上类似,但空白行不编号
(39)date (选项)(参数) 显示或设置系统时间或日期
-d:显示字符串所指的日期和时间
-s:根据字符串所指设置系统日期和时间
参数:+时间日期格式
%F:年-月-日
%T:时:分:秒
%w:一个星期的第几天
%A:星期的全称
%a:星期的简称
%d:一个月的第几天
%j:一年的第几天
%W:一年的第几个星期
实例1:date -d "1day" +%F 显示一天后的时间
date -d "-1day" +%F 显示一天前的时间
year month day hour min sec 年月日时分秒
实例2:date -s "1hour" 修改系统时间,往后延1小时
常用的时间服务器有:pool.ntp.org ntpl.aliyun.com
系统自动校时:ntpdate pool.ntp.org 如果遇到the ntp socket is in use
需要把ntpd服务先停掉。service ntpd stop
(40)service 控制系统服务的实用工具,可以启动、停止、重启、关闭系统服务。系统服务存放在/etc/init.d下
--status--all:显示所有服务的状态
(41)which 查找给定命令的绝对路径
(42)last 显示用户的最近登录信息
-n 3:显示最近3条登录信息
-d:将IP地址转换成主机名称
(43)lastlog 显示所有用户的最近一次登录信息
(44)shutdown (选项)(参数) 系统关机命令
-h:关机
-r:重启
-c:中断关机命令
-k:送出消息给所有用户,但不会实际关机
参数有时间和警告信息
实例1:shutdown -h now 立即关机
实例2:shutdown -h +5 "system will shutdown after 5 minutes" 系统5分钟后关机并广播
(45)halt 关闭正在运行的Linux系统
-p:关闭之后断电
-d:关闭系统但不留下记录
(46)poweroff 关闭系统并断电
(47)whoami 查看当前用户
(48)chmod 更改文件或目录的权限
-R:递归处理,将目录下的子目录和文件一并处理
-v:显示指令的执行过程
u:user所有者
g:group所有者属的组
o:other其他人
a:all所有人
实例1:chmod u+x,g+w f01 //为文件f01设置自己可以执行,组员可以写入的权限
chmod u=rwx,g=rw,o=r f01
chmod 764 f01
chmod a+x f01 //对文件f01的u,g,o都设置可执行属性
(49)chown 更改文件或目录的所有者和所属群组
-R:递归处理,将目录下的子目录和文件一并处理
-v:显示指令执行过程
参数:用户:组:指定所有者和用户组,当省略“:组”,仅改变文件所有者
(50)ln 创建链接文件,默认创建硬链接,如果要创建软链接需-s
-s:创建软链接
-v:显示指令执行过程
(51)less 用于查看文件内容,功能比cat强大,支持翻页和查找功能。pageup向上翻页,pagedown向下翻页,q退出。/root查找特定字符串,n是下一个,N是上一个。如果文件较大,cat命令可能显示不全,less命令不会出现这种情况。
(52)seq 用于生成从某个数到另外一个数之间的所有整数
-w:列前添加0,使宽度相同
-s:使用指定字符串分隔数字,默认使用\n
(53)sort 将文件进行排序,并将排序结果标准输出
-b:忽略每行前面的空格
-o filename:指定输出文件
-r:逆序
-n:按数值的大小排序
-f:将小写字母视为大写字母
-u:忽略相同的行
-t:指定栏位分隔符
-k:指定要排序的栏位
(54)uniq:报告或删除文件中的重复行,一般与sort同时使用(54)
seq [选项]... 尾数
seq [选项]... 首数 尾数
seq [选项]... 首数 增量 尾数
(七)用户分类
root用户
普通用户
1.添加新用户:useradd oldboy
2.设置密码: passwd oldboy
3.切换用户: su - oldboy
4.退出当前用户:ctrl + d
(八)关闭selinux
查看selinux运行状态:getenforce
enforcing:正在运行
permissive:临时关闭
disabled:彻底关闭
如果selinux正在运行,临时关闭命令:setenforce Permissive
永久关闭selinux:修改/etc/selinux/config,将selinux设成disabled,重启服务器之后生效。
(九)关闭iptables防火墙
当服务器仅在内网使用时,可关闭
查询iptables状态:/etc/init.d/iptables status
临时关闭:/etc/init.d/iptables stop
永久关闭:chkconfig iptables off 让防火墙不自启动
(十)关于中文乱码如何解决的问题
远程连接工具的字符集与服务器的字符集不一致导致。
查看当前系统字符集:echo $LANG
临时修改服务器字符集:export LANG=en_US.UTF-8
永久修改服务器字符集:修改/etc/sysconfig/i18n,再用source编译该文件即可。
(十一)Linux目录结构
一切从根开始,一切皆文件
磁盘/分区/设备在没有挂载的情况下,是无法使用的,挂载相当于给设备开了一个入口。
mount /dev/cdrom /mnt
挂载点 目录
/bin:二进制命令文件的存放目录
/dev:设备、光盘、硬盘的挂载点
/etc:系统的配置文件
/home:普通用户的家目录
/lib:库文件
/lib64:64位库文件
/lost+found:磁盘或文件系统损坏,断电的临时文件位置
/mnt:临时挂载点
/opt:第三方软件安装位置
/proc:内存中的信息
/root:root的家目录
/tmp:临时目录
/sbin:超级二进制文件,仅root用户可用
/usr:存放用户的程序
/var:经常变化的文件,系统日志
/etc/resolv.conf:DNS配置文件,优先级低于/etc/sysconfig/network-scripts/ifcfg-eth0
/etc/sysconfig/network:主机名配置文件
临时修改主机名:hostname oldboy02
永久修改:修改配置文件,重启生效
/etc/hosts:主机名与IP地址解析关系文件
/etc/fstab:开机自动挂载文件
第一列:设备名称
第二列:设备挂载点
/etc/rc.local:开机自启动程序,想要让一个程序自启动,加入此处即可。
/etc/inittab:开机运行级别配置文件
0 关机状态,don't set in this mode
1 单用户模式
2 多用户模式
3 完全的多用户模式,命令模式
4 未使用
5 X11,桌面模式
6 重启状态,don't set in this mode
查看当前运行级别:runlevel
临时切换运行级别:init 3
永久切换运行级别:修改配置文件,重启生效
/etc/init.d:服务管理目录,管理开机自启动的程序
/etc/profile:系统环境变量和别名
/etc/bashrc:别名文件
~:当前用户的家目录
/usr/local:编译安装软件的默认目录
/var/log/messages:系统默认日志信息
/var/log/secure:系统用户的登录信息
/proc/meminfo:内存信息
/proc/cpuinfo:CPU信息
/proc/loadavg:系统负载信息
/proc/mounts:显示系统挂载信息
(十二)网卡配置
配置文件:/etc/sysconfig/network-scripts/ifcfg-eth0
其中BooTPROTO=None:网卡获取IP是自动分配
USERCTL=no:不允许普通用户管理网卡
DNS:域名解析服务
DNS1:114.114.114.114
DNS2:114.114.115.115
配置文件修改之后想要生效都必须重启。
重启网卡
方法一:ifdown eth0 &&ifup eth0 重启单一网卡
方法二:/etc/init.d/network restart 重启所有网卡
(十三)Linux开机启动过程
1.BIOS自检
2.磁盘MBR引导
3.GRUB菜单选择要加载的内核
4.加载内核
5.运行init进程
6.运行初始化脚本,设置主机名和IP地址
7.根据开机级别,启动不同的程序
8.加载mingetty进程,出现登录框
(十四)文件属性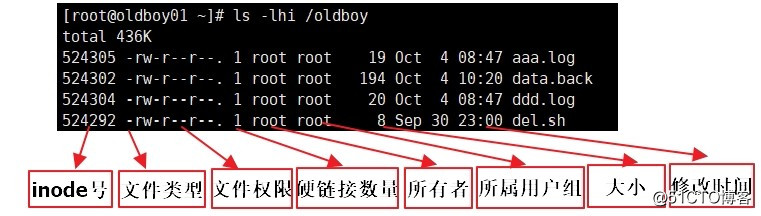
特别说明:文件名不是文件属性
1.inode
用来存放文件属性的空间,通过格式化文件系统而来,它在某一个分区是唯一的。
每创建一个文件就要消耗一个inode。inode中存放了数据block的指针,如果两个文件inode号相同,他们其实是一个文件,只是文件名不同而已,则互为硬链接。
df -i 可查看inode使用情况
2.block
实际存放数据的数据块,也是格式化创建文件系统而来。
一般一个block是4k,创建一个大文件会占用很多的block,如果一个文件很小则不足4k空间会被浪费。
每读取一个block就算一次磁盘I/O
df -h 可查看block使用情况
3.文件类型
-:file文件
d:目录
l:软链接
4.用户和用户组
id 可查询用户id
用户的分类:
root 皇帝 UID=0
虚拟用户 傀儡 UID=1-499
普通用户 UID=500+
/etc/passwd 存放用户的信息
/etc/shadow 存放密码的信息
/etc/group 存放用户组的信息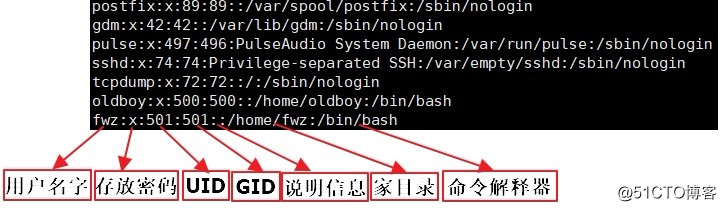
nologin就是傀儡用户
5.Linux基础文件权限
r:读
w:写
x:可执行
-:nothing
rw-r--r--:以8进制表示是644,把每一位看成二进制位
从前往后是所有者的权限,所属群组的权限,其他人的权限
6.软链接与硬链接
软链接相当于快捷方式
创建软链接:ln -s oldboy.txt oldboy.txt-soft
硬链接相当于一个房间的门,一个房间可以有很多门,如果两个文件的inode相同,则互为硬链接。
创建硬链接:ln oldboy.txt oldboy.txt-hard
软链接与硬链接的区别:除了以上之外,目录是不能创建硬链接的,因为目录不是一个实际的房间,没房间哪来门,目录只能创建软链接。软链接虽然指向了源文件,如果源文件被删除了,软链接就变成了死链接。源文件被删除指的是硬链接数为0。只要还有一个硬链接在,文件总是能被访问的。
7.文件删除原理
删除文件所有的硬链接
文件的进程调用数为0
如果一个文件的硬链接数为0,但是依然被进程所占用,说明这个文件未被彻底删除。
通过 lsof|grep delete 可查看硬链接数为0的文件
进程都存放在/etc/init.d/下,restart即可,文件即被释放。
8.文件的三个时间状态
mtime modified time 修改时间
atime access time 访问时间
ctime change time 文件属性改变时间
可通过stat命令查看
(十五)通配符
{ } 匹配括号中任意的字符串{scripts,jiaoben}
[ ] 可用于生成序列,[0-9]0-9的序列;匹配括号中任意的单一字符[a,b,c] 等同于$() 小括号内命令的执行结果
- 匹配任何长度字符
!取反
?匹配任意单个字符
\ 转义符
&& 前一个命令执行成功后再执行后一个命令
|| 前一个命令执行失败后再执行后一个命令
(十六)正则表达式
1.正则与通配符的区别
通配符用于查找文件名,大部分命令都支持
正则用于查找文件内容,只有少数命令支持,如awk、grep、sed
2.正则分类
基础正则:^ $ . [] [^]
扩展正则:| { } () ? +
支持扩展正则的命令:egrep或grep -e、awk、sed -r
基础正则:
. 匹配任意一个字符,不含空行
\ 转义字符
\d 匹配数字
\w 匹配字母或数字或下划线
\s 匹配任意的空白符
(星号) 前一个字符连续出现0次以上
.* 匹配所有字符,不含空行
[ ] [abc]找出包含a或b或c的行
^ 排除 [^abc]排除a或b或c,第二种匹配字符串的开头
扩展正则:
+(加号) 前一个字符连续出现1次以上
| 表或者
( ) 表反向引用或后向引用
u{n,m} 前一个字符连续出现至少n次,至多出现m次
{n,} 前一个字符连续出现至少n次
{,m} 前一个字符连续出现至多m次
? 前一个字符出现0次或1次
$ 以前一个字符结尾
(十七)Linux常用快捷键
Ctrl+a:光标移到行首
Ctrl+e:光标移到行尾
Ctrl+c:取消当前操作
Ctrl+d:登出
Ctrl+l:清屏
Ctrl+u:剪切光标到行首的内容
Ctrl+k:剪切光标到行尾的内容
Ctrl+y:粘贴
Ctrl+r:搜索历史命令
(十八)vim快捷键
有三种模式:一般模式、输入模式、命令模式
一般模式下可以移动光标,删除行,复制粘贴这些操作
输入模式下可以插入编辑
光标移到文件的第一行:gg
光标移到文件的最后一行:G
光标移到文件的第10行:10gg
光标移到行首:0
光标移到行尾:$
在当前行插入并编辑:i
在当前行的下一行插入并编辑:o
撤销上一次操作:u
恢复上一次操作:Ctrl+r
删除关闭到行尾:D
删除当前字符:x
复制当前行:yy
剪切当前行:dd
粘贴:p
esc:退出编辑模式
:会进入命令模式
:wq:保存退出
:q:退出
:q!:强制退出不保存
:wq!:强制退出并保存
:set no 设置行号
(十九)文件权限知识
对文件而言:
r:可以读
w:可以修改,但需要r的配合,否则会清空文件
x:可以执行,但需要r的配合,否则无法执行
对目录而言:
r:可以查看目录,需要x的配合
w:可以创建文件,删除文件,重命名文件,需要x的配合
x:可以cd
当要删除一个文件的时候,首先看对所在的目录是否有wx的权限
对于文件而言644比较安全
对于目录而言755比较安全
Linux控制系统默认权限的是umask
文件支持的最大权限是666
目录支持的最大权限是777
对于目录,默认权限=777-umask
对于文件,默认权限=666-umask,但如果某一位是奇数,则这一位还要加1。
转载于:https://blog.51cto.com/13983618/2296159

















 1579
1579

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









