



 本文介绍了一种使用ORM框架实现图书与作者间多对多关系的方法,通过创建中间表解决了一本书可以由多个作者共同完成及一位作者可以撰写多本书的问题,并提供了具体的SQLAlchemy实现代码。
本文介绍了一种使用ORM框架实现图书与作者间多对多关系的方法,通过创建中间表解决了一本书可以由多个作者共同完成及一位作者可以撰写多本书的问题,并提供了具体的SQLAlchemy实现代码。
一、前言
现在来设计一个能描述“图书”与“作者”的关系的表结构,需求是:
- 一本书可以有好几个作者一起出版
- 一个作者可以写好几本书
此时你会发现,用之前学的外键好像没办法实现上面的需求了,因为:

当然你更不可以像下面这样干,因为这样就你就相当于有多条书的记录了,太low b了,改书名还得都改。。。
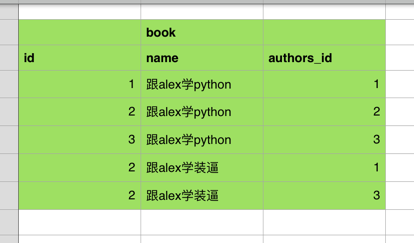
这两种情况,都发现数据时冗余的,出现了很多重复的信息,这样可不行
二、多对多的表结构
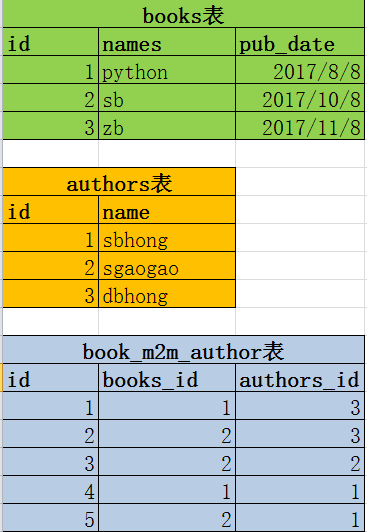
2.1、表结构
说明:如果遇到这种情况的话,我们可以搞出一张中间表出来

2.2、表数据
说明:这样就相当于通过book_m2m_author表完成了book表和author表之前的多对多关联
2.3、orm代码
from sqlalchemy import Table,Column,Integer,String,DATE,ForeignKey
from sqlalchemy.orm import relationship
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import create_engine
Base = declarative_base() #创建orm基类
book_m2m_author = Table("book_m2m_author",Base.metadata,
Column("id",Integer,primary_key=True),
Column('books_id',Integer,ForeignKey("books.id")),
Column('authors_id',Integer,ForeignKey("authors.id")))
class Book(Base):
__tablename__ = "books"
id = Column(Integer,primary_key=True)
name = Column(String(64))
pub_date = Column(DATE)
authors = relationship("Author",secondary=book_m2m_author,backref="books")
def __repr__(self):
return self.name
class Author(Base):
__tablename__ = "authors"
id = Column(Integer,primary_key=True)
name = Column(String(32))
def __repr__(self):
return self.name
engine = create_engine("mysql+pymysql://root:111111@120.26.225.159:3306/qigaodb",
encoding="utf-8")
Base.metadata.create_all(engine)
注意了,这里面有这种创建表结构方式,跟我们之前的不太一样:
book_m2m_author = Table("book_m2m_author",Base.metadata,
Column("id",Integer,primary_key=True),
Column('books_id',Integer,ForeignKey("books.id")),
Column('authors_id',Integer,ForeignKey("authors.id")))
这张表对用户来讲的是不需要关心的,是orm自动帮你维护的,在自动帮你维护的情况下,不需要操作它了,不需要搞映射关系了,通过这个命令Table 去创建一个表,这张表通过外键已经帮我们关联了,但是通过orm的查询的时候,我们还是需要建立下面的关系的:
authors = relationship("Author",secondary=book_m2m_author,backref="books")
这一句话表名,在orm查询的时候,还需要orm内存对象的一个级别的映射,如果没有具体制定,没有人知道第三张表book_m2m_author的存在,因为第3张表主动关联其他两张表。
2.4、插入数据
from day12.orm_m2m import m2m_table
from sqlalchemy.orm import sessionmaker
session_class = sessionmaker(bind=m2m_table.engine)
session = session_class()
b1 = m2m_table.Book(name="python",pub_date="2017-08-08")
b2 = m2m_table.Book(name="sb",pub_date="2017-10-08")
b3 = m2m_table.Book(name="zb",pub_date="2017-11-08")
a1 = m2m_table.Author(name="sbhong")
a2 = m2m_table.Author(name="sgaogao")
a3 = m2m_table.Author(name="dbhong")
b1.authors = [a1,a3]
b2.authors = [a1,a2,a3]
session.add_all([b1,b2,b3,a1,a2,a3])
session.commit()
2.5、查询数据
from day12.orm_m2m import m2m_table
from sqlalchemy.orm import sessionmaker
session_class = sessionmaker(bind=m2m_table.engine)
session = session_class()
authors_obj = session.query(m2m_table.Author).filter_by(name="sbhong").first()
print(authors_obj.books) #通过books反查出books表中的数据
book_obj = session.query(m2m_table.Book).filter(m2m_table.Book.id==2).first()
print(book_obj.authors) #通过authors反查出authors表中的数据
session.commit()
#输出
[python, sb]
[dbhong, sgaogao, sbhong]


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









