






 本文探讨了在面对日益增长的数据量时,如何通过分表、拆表等技术手段优化公司短信平台和日志系统。文章强调了合理使用ID作为数据标识的重要性,并提出了一套关于参数传递的规范,旨在提升系统效率与稳定性。
本文探讨了在面对日益增长的数据量时,如何通过分表、拆表等技术手段优化公司短信平台和日志系统。文章强调了合理使用ID作为数据标识的重要性,并提出了一套关于参数传递的规范,旨在提升系统效率与稳定性。
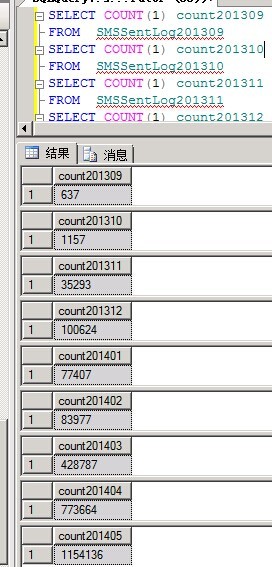
公司的短信平台,数据量越来越大了,需要对数据进行一些优化,下面是拆分后的数据库量参考。

新开发的软件模块,必须支持分表,拆表的功能
一个数据表里,不适合保存1000万以上的记录
新开发的业务模块,能分表的全分表,否则,将来我们无法用其他小型数据库,例如mysql
现在系统的短信已经进行了拆表
接着打算把日志也进行拆表
确保数据库里,没有庞大的表,随时可以切换数据库
每个人把自己负责的事情,做到自己能力的及至,做到部门能力的及至,公司能力的及至,就很有希望了
有时候我说话很随意,但是一般会注意,我说出去的话,会不会打击人家的工作积极性,大家人家的兴趣爱好,不要给热情工作的小活子泼冷水什么的,尽量是鼓励
我们传递参数时:
1: 不要传递网点的编号,尽量传递id, 因为编号是可以修改的, 修改了编号,数据都对不上了。要传递Id.
2: 用户的编号也是可修改的,也是要传递Id,科学。
UserId, SiteId


















 1522
1522

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









