







索引,即Index,在MySQL中也称为key。索引如书本的目录,可以帮我们精确定位到目的数据。
- B+树索引
在MySQL中,索引是存储引擎层实现的。索引大多使用B树实现,通常是B+树。B+树的特点是,非叶节点只存索引信息,所有的数据信息存在叶子节点。算法上,可以充分利用非叶子节点的信息,降低整棵树的高度,从而减少时间复杂度;实现上,可以让整个查找的数据结构更轻量化,更易整体存进内存,提高查找速度。
关于B+树,目前百度上有两个版本,即节点含有N个关键字时,有N个/N+1个子节点。有N个子节点时,包含N个子树的定义可以追溯到严蔚敏版《数据结构》;另一种说法来自《算法导论》,贴一段原话:
| B-trees are balanced search trees designed to work well on magnetic disks or other direct-access secondary storage devices. B-trees are similar to red-black trees (Chapter 13), but they are better at minimizing disk I/O operations. Many database systems use B-trees, to store information.
Section 18.1. A common variant on a B-tree, known as a B+tree, stores all the satellite information in the leaves and stores only keys and child pointers in the internal nodes, thus maximizing the branching factor of the internal nodes. |
以算法导论为准,示意图如下:
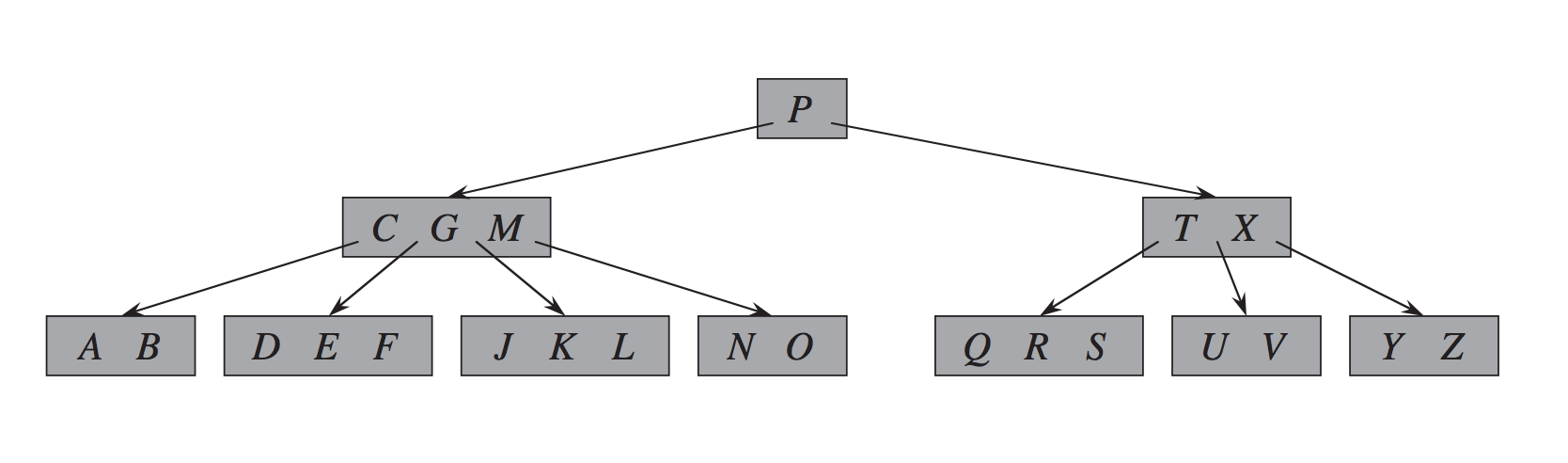
下面用一个具体的例子说明B+树在InnoDB中的实现。有数据表:
CREATE TABLE People (
last_name varchar(50) not null,
first_name varchar(50) not null,
dob date not null,
gender enum('m', 'f')not null,
key(last_name, first_name, dob)
);该表建立了last_name, first_name, dob的三列联合索引,则其数据存储方式为:
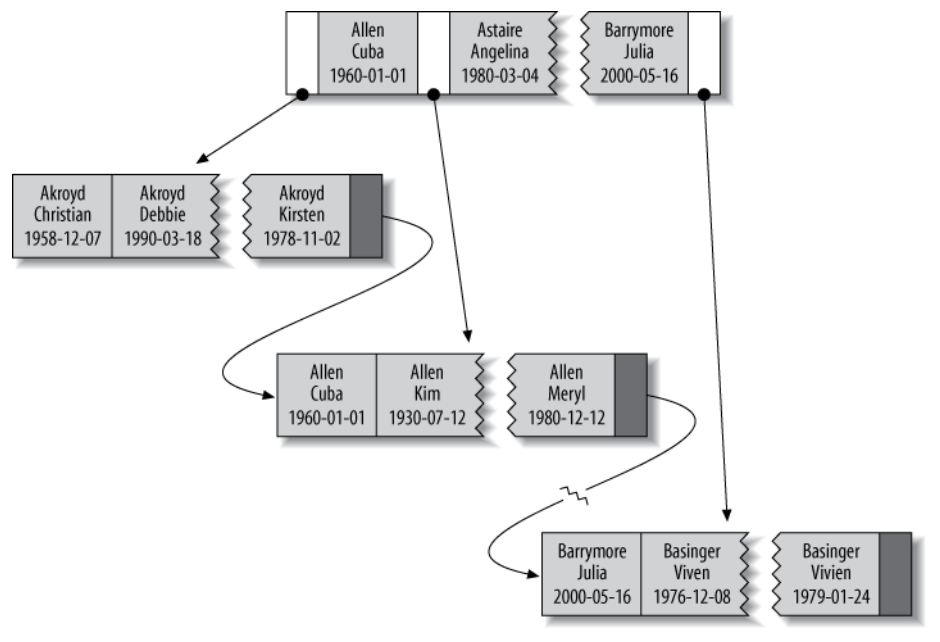
从前两个和最后两个例子对比可得出: 索引是按照定义顺序对值进行排序的。形象地,想象你在有三个属性的class中重写compareTo方法。
上述方式决定了,B+树索引适用于全键值、键值范围、键前缀查询。具体地,支持以下类型的查询:
- 全值匹配。查找where last_name=a and first_name=b and dob=c的记录。
- 匹配最左前缀。查找where last_name=a (and first_name=b)的记录,即必须是定义中最左列开始的连续列。
- 匹配列前缀。查找where last_name like 'J%'。
- 匹配范围值。查找where last_name>=Allen and last_name<=Bruce。
此外,“覆盖索引”可以在不访问字段的情况下,取出要查询的值;ORDER BY也可以借助索引实现。规则1和2限定了联合索引的列使用范围,规则3和4限定了每个列可以使用索引的方式。在理解了联合索引的存储结构后,并不难总结出上述规则,或者其他(禁止)规则。基于上述实现,B+树的索引存在以下限制:
- 如果没有按最左列或者列的最左开始,则索引无效。查询where first_name=Bill,或者where dob='2017-11-20',或者where last_name like '%reen'。
- 不能跳过联合索引的列。比如,查询where last_name='Green' and dob='2017-11-20'。
- 范围查询(或者函数/表达式,使索引失效的操作)以右的列,索引失效。查询where last_name='Green' and first_name like 'J%' and dob='2017-11-20'。
总结起来,索引列的顺序对性能影响很大。限制3中,范围查询属于匹配列前缀的情况,实际上并不会导致索引失效,属于 MySQL优化器调用存储引擎方式的限制。
- 哈希索引
这是一种基于哈希表的索引,对每行数据的索引计算出一个哈希码;只有精确匹配索引所有列的查询才有效。索引哈希表的key是哈希值,value是指向对应数据的指针;采用链地址法解决哈希冲突。
基于哈希表实现的索引,结构紧凑,数据量小,查找速度很快,可以用于join操作;同时,有以下局限:
- 不能避免读取行。索引只存哈希值和地址指针,每次查询都须访问数据行;B+树索引的覆盖索引在这一点就很有优势。
- 无法用于排序。因为索引是按哈希顺序排序的,哈希值不能保持与被索引值一直的相对大小关系。
- 不支持部分索引。哈希值计算的函数是以所有索引列的值为变量。
- 不支持范围查询。原因同2,只支持等值比较,= ,in, <=>(NULL值比较)
- 哈希冲突过多问题。可以参考:哈希表负载因子。在查找和删除、修改方面都有不小开销。
InnoDB可以自适应哈希索引。某些索引或者某索引被频繁使用时,在内存中基于B+树索引为这些列(或前缀)创建一个哈希索引。
InnoDB的做法,给我们提供了一种快速查询的思路:手动创建hash列作为索引列。
例如,在一个存储url的表中,经常需要做:select id from urlTable where url="http://www.baidu.com"。可以在urlTable中新增url_crc列,使用CRC32做哈希,并对url_crc建立索引,这样查询可写为:select id from urlTable where url="http://www.baidu.com" and url_crc=CRC32("http://www.baidu.com")。注意,url=的条件不能省,需要以此解决哈希冲突。(PS.早年百度经典的URL去重面试题就是用这个思想做的)。
触发器可以实现上述方案:
CREATE TABLE pseudohash (
id int unsigned NOT NULL auto_increment,
url varchar(255) NOT NULL,
url_crc int unsigned NOT NULL DEFAULT 0,
PRIMARY KEY(id)
);
DELIMITER //
CREATE TRIGGER pseudohash_crc_ins BEFORE INSERT ON pseudohash FOR EACH ROW BEGIN
SET NEW.url_crc=crc32(NEW.url);
END;
//
CREATE TRIGGER pseudohash_crc_upd BEFORE UPDATE ON pseudohash FOR EACH ROW BEGIN
SET NEW.url_crc=crc32(NEW.url);
END;
//
DELIMITER ;哈希函数要考虑两个点:哈希值短、冲突少。对于大量冲突的情况,可以使用二次哈希;同样的,原始字段的查询条件不能省略。
- 其他索引
空间数据索引:MyISAM支持,无须前缀查询,从所有维度进行索引,支持任意组合。
全文索引:基于关键词的索引,不适用where操作,用于MATCH AGAINSST。
聚簇索引、覆盖索引等。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









