



 在CentOS7上安装CDH集群时遇到命令超时错误,涉及mkdir操作和HDFS目录创建。通过su切换到hdfs用户并使用hdfs dfsadmin -safemode leave命令成功解决问题。
在CentOS7上安装CDH集群时遇到命令超时错误,涉及mkdir操作和HDFS目录创建。通过su切换到hdfs用户并使用hdfs dfsadmin -safemode leave命令成功解决问题。

Command aborted because of exception: Command timed-out after 90 seconds
问题:
centos7 安装cdh,群集设置时出现以下错误:
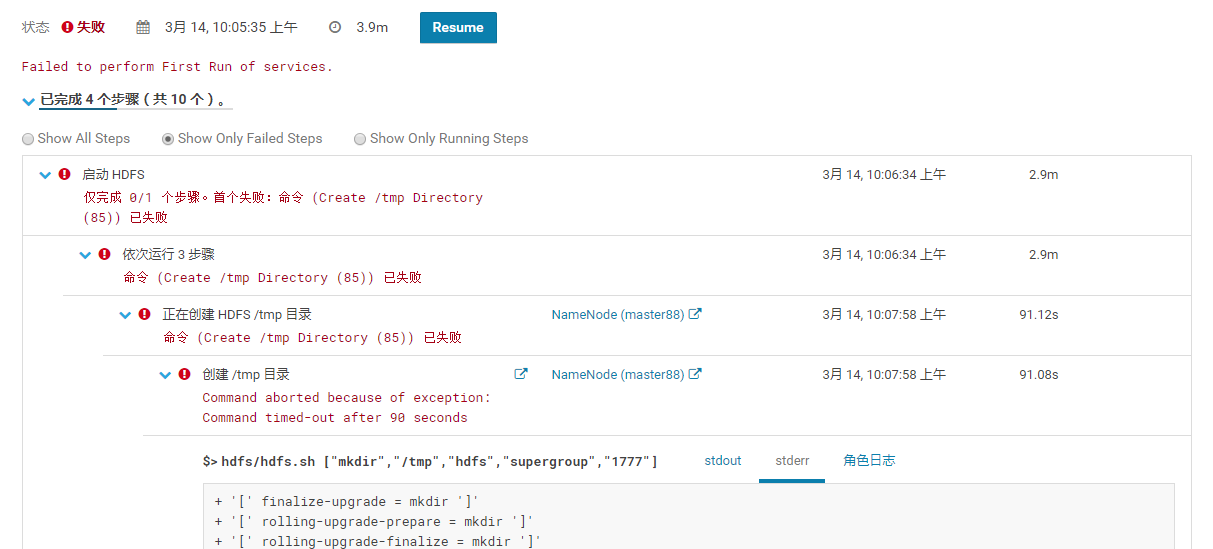
+ '[' finalize-upgrade = mkdir ']'
+ '[' rolling-upgrade-prepare = mkdir ']'
+ '[' rolling-upgrade-finalize = mkdir ']'
+ '[' nnDnLiveWait = mkdir ']'
+ '[' monitor-offline = mkdir ']'
+ '[' refresh-datanode = mkdir ']'
+ '[' mkdir = mkdir ']'
+ '[' 5 -ne 5 ']'
+ DIR=/tmp
+ USER=hdfs
+ GROUP=supergroup
+ PERMS=1777
+ '[' -z true ']'
+ MGMT_CLASSPATH='/opt/cloudera-manager/cm-5.14.1/share/cmf/lib/*'
+ MKDIR_LOG4J_FILE=/opt/cloudera-manager/cm-5.14.1/run/cloudera-scm-agent/process/46-hdfs-NAMENODE-createtmp/log4j_mkdir_1642.properties
+ rm -f /opt/cloudera-manager/cm-5.14.1/run/cloudera-scm-agent/process/46-hdfs-NAMENODE-createtmp/log4j_mkdir_1642.properties
+ cat
+ MKDIR_JAVA_OPTS=' -Dlog4j.configuration=file:///opt/cloudera-manager/cm-5.14.1/run/cloudera-scm-agent/process/46-hdfs-NAMENODE-createtmp/log4j_mkdir_1642.properties'
+ '[' /usr/java/jdk1.8.0_201-amd64 '!=' '' ']'
+ JAVA=/usr/java/jdk1.8.0_201-amd64/bin/java
+ MKDIR_CLASSPATH='/opt/cloudera-manager/cm-5.14.1/run/cloudera-scm-agent/process/46-hdfs-NAMENODE-createtmp:/opt/cloudera-manager/cm-5.14.1/share/cmf/lib/*'
+ MKDIR_FLAGS='--mgmt_home /opt/cloudera-manager/cm-5.14.1/share/cmf'
+ MKDIR_FLAGS='--mgmt_home /opt/cloudera-manager/cm-5.14.1/share/cmf --cdh_version 5'
+ MKDIR_FLAGS='--mgmt_home /opt/cloudera-manager/cm-5.14.1/share/cmf --cdh_version 5 --conf_dir /opt/cloudera-manager/cm-5.14.1/run/cloudera-scm-agent/process/46-hdfs-NAMENODE-createtmp'
+ '[' -n '' ']'
+ exec /usr/java/jdk1.8.0_201-amd64/bin/java -Dlog4j.configuration=file:///opt/cloudera-manager/cm-5.14.1/run/cloudera-scm-agent/process/46-hdfs-NAMENODE-createtmp/log4j_mkdir_1642.properties -cp '/opt/cloudera-manager/cm-5.14.1/run/cloudera-scm-agent/process/46-hdfs-NAMENODE-createtmp:/opt/cloudera-manager/cm-5.14.1/share/cmf/lib/*' com.cloudera.cmf.cdhclient.common.hdfs.CreateHdfsDirUtil /tmp hdfs supergroup 1777 --mgmt_home /opt/cloudera-manager/cm-5.14.1/share/cmf --cdh_version 5 --conf_dir /opt/cloudera-manager/cm-5.14.1/run/cloudera-scm-agent/process/46-hdfs-NAMENODE-createtmp
解决方法:
su - hdfs
hdfs dfsadmin -safemode leave

















 8429
8429

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









