 SQL查询与删除重复记录技术
SQL查询与删除重复记录技术







 本文详细介绍了SQL中查询及删除重复记录的方法,包括名相同ID不同情况下的选择性保留,以及没有大小关系时的处理策略。同时,提供了删除重复记录时的多种SQL语句实现,帮助开发者有效管理数据库中的冗余数据。
本文详细介绍了SQL中查询及删除重复记录的方法,包括名相同ID不同情况下的选择性保留,以及没有大小关系时的处理策略。同时,提供了删除重复记录时的多种SQL语句实现,帮助开发者有效管理数据库中的冗余数据。
处理表重复记录(查询和删除)
查询
1、Name相同的重复值记录,没有大小关系只保留一条
2、Name相同,ID有大小关系时,保留大或小其中一个记录
一、用于查询重复处理记录(如果列没有大小关系时SQL2000用生成自增列和临时表处理,SQL2005用row_number函数处理)
生成测试数据
1 IF NOT OBJECT_ID('Tempdb..#T') IS NULL 2 DROP TABLE #T 3 Go 4 CREATE TABLE #T 5 ( 6 [ID] INT , 7 [Name] NVARCHAR(1) , 8 [Memo] NVARCHAR(2) 9 ) 10 INSERT #T 11 SELECT 1, N'A', N'A1' 12 UNION ALL 13 SELECT 2, N'A', N'A2' 14 UNION ALL 15 SELECT 3, N'A', N'A3' 16 UNION ALL 17 SELECT 4, N'B', N'B1' 18 UNION ALL 19 SELECT 5, N'B', N'B2' 20 Go
1、Name相同ID最小的记录(推荐用1,2,3),方法3在SQl2005时,效率高于1、2
1 --方法1: 2 Select * from #T a where not exists(select 1 from #T where Name=a.Name and ID<a.ID) 3 4 --方法2: 5 select a.* from #T a join (select min(ID)ID,Name from #T group by Name) b on a.Name=b.Name and a.ID=b.ID 6 7 --方法3: 8 select * from #T a where ID=(select min(ID) from #T where Name=a.Name) 9 10 --方法4: 11 select a.* from #T a join #T b on a.Name=b.Name and a.ID>=b.ID group by a.ID,a.Name,a.Memo having count(1)=1 12 13 --方法5: 14 select * from #T a group by ID,Name,Memo having ID=(select min(ID)from #T where Name=a.Name) 15 16 --方法6: 17 select * from #T a where (select count(1) from #T where Name=a.Name and ID<a.ID)=0 18 19 --方法7: 20 select * from #T a where ID=(select top 1 ID from #T where Name=a.name order by ID) 21 22 --方法8: 23 select * from #T a where ID!>all(select ID from #T where Name=a.Name) 24 25 --方法9(注:ID为唯一时可用): 26 select * from #T a where ID in(select min(ID) from #T group by Name) 27 28 --SQL2005: 29 30 --方法10: 31 select ID,Name,Memo from (select *,min(ID)over(partition by Name) as MinID from #T a)T where ID=MinID 32 33 --方法11: 34 select ID,Name,Memo from (select *,row_number()over(partition by Name order by ID) as MinID from #T a)T where MinID=1
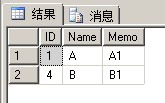
2、Name相同ID最大的记录,与min相反
1 --方法1: 2 Select * from #T a where not exists(select 1 from #T where Name=a.Name and ID>a.ID) 3 4 --方法2: 5 select a.* from #T a join (select max(ID)ID,Name from #T group by Name) b on a.Name=b.Name and a.ID=b.ID order by ID 6 7 --方法3: 8 select * from #T a where ID=(select max(ID) from #T where Name=a.Name) order by ID 9 10 --方法4: 11 select a.* from #T a join #T b on a.Name=b.Name and a.ID<=b.ID group by a.ID,a.Name,a.Memo having count(1)=1 12 13 --方法5: 14 select * from #T a group by ID,Name,Memo having ID=(select max(ID)from #T where Name=a.Name) 15 16 --方法6: 17 select * from #T a where (select count(1) from #T where Name=a.Name and ID>a.ID)=0 18 19 --方法7: 20 select * from #T a where ID=(select top 1 ID from #T where Name=a.name order by ID desc) 21 22 --方法8: 23 select * from #T a where ID!<all(select ID from #T where Name=a.Name) 24 25 --方法9(注:ID为唯一时可用): 26 select * from #T a where ID in(select max(ID) from #T group by Name) 27 28 --SQL2005: 29 30 --方法10: 31 select ID,Name,Memo from (select *,max(ID)over(partition by Name) as MinID from #T a)T where ID=MinID 32 33 --方法11: 34 select ID,Name,Memo from (select *,row_number()over(partition by Name order by ID desc) as MinID from #T a)T where MinID=1
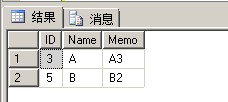
删除
二、删除重复记录有大小关系时,保留大或小其中一个记录
生成测试数据
1 USE [tempdb] 2 GO 3 IF NOT OBJECT_ID('Tempdb..#T') IS NULL 4 DROP TABLE #T 5 Go 6 CREATE TABLE #T 7 ( 8 [ID] INT , 9 [Name] NVARCHAR(1) , 10 [Memo] NVARCHAR(2) 11 ) 12 INSERT #T 13 SELECT 1, N'A', N'A1' 14 UNION ALL 15 SELECT 2, N'A', N'A2' 16 UNION ALL 17 SELECT 3, N'A', N'A3' 18 UNION ALL 19 SELECT 4, N'B', N'B1' 20 UNION ALL 21 SELECT 5, N'B', N'B2' 22 Go
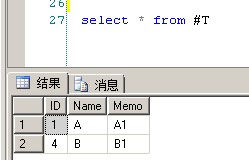
1、Name相同ID最小的记录(推荐用1,2,3),保留最小一条
1 --方法1: 2 delete a from #T a where exists(select 1 from #T where Name=a.Name and ID<a.ID) 3 4 --方法2: 5 delete a from #T a left join (select min(ID)ID,Name from #T group by Name) b on a.Name=b.Name and a.ID=b.ID where b.Id is null 6 7 --方法3: 8 delete a from #T a where ID not in (select min(ID) from #T where Name=a.Name) 9 10 --方法4(注:ID为唯一时可用): 11 delete a from #T a where ID not in(select min(ID)from #T group by Name) 12 13 --方法5: 14 delete a from #T a where (select count(1) from #T where Name=a.Name and ID<a.ID)>0 15 16 --方法6: 17 delete a from #T a where ID<>(select top 1 ID from #T where Name=a.name order by ID) 18 19 --方法7: 20 delete a from #T a where ID>any(select ID from #T where Name=a.Name) 21 22 23 select * from #T
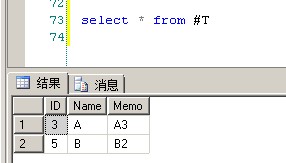
2、Name相同ID保留最大的一条记录
1 --方法1: 2 delete a from #T a where exists(select 1 from #T where Name=a.Name and ID>a.ID) 3 4 --方法2: 5 delete a from #T a left join (select max(ID)ID,Name from #T group by Name) b on a.Name=b.Name and a.ID=b.ID where b.Id is null 6 7 --方法3: 8 delete a from #T a where ID not in (select max(ID) from #T where Name=a.Name) 9 10 --方法4(注:ID为唯一时可用): 11 delete a from #T a where ID not in(select max(ID)from #T group by Name) 12 13 --方法5: 14 delete a from #T a where (select count(1) from #T where Name=a.Name and ID>a.ID)>0 15 16 --方法6: 17 delete a from #T a where ID<>(select top 1 ID from #T where Name=a.name order by ID desc) 18 19 --方法7: 20 delete a from #T a where ID<any(select ID from #T where Name=a.Name) 21 22 23 select * from #T
删除重复记录没有大小关系时,处理重复值
生成测试数据
1 USE [tempdb] 2 GO 3 IF NOT OBJECT_ID('Tempdb..#T') IS NULL 4 DROP TABLE #T 5 Go 6 CREATE TABLE #T 7 ( 8 [Num] INT , 9 [Name] NVARCHAR(1) 10 ) 11 INSERT #T 12 SELECT 1, N'A' 13 UNION ALL 14 SELECT 1, N'A' 15 UNION ALL 16 SELECT 1, N'A' 17 UNION ALL 18 SELECT 2, N'B' 19 UNION ALL 20 SELECT 2, N'B' 21 Go
方法1:
1 if object_id('Tempdb..#') is not null 2 drop table # 3 Select distinct * into # from #T--排除重复记录结果集生成临时表# 4 5 truncate table #T--清空表 6 7 insert #T select * from # --把临时表#插入到表#T中 8 9 --查看结果 10 select * from #T
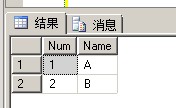
方法2:
1 alter table #T add ID int identity--新增标识列 2 go 3 delete a from #T a where exists(select 1 from #T where Num=a.Num and Name=a.Name and ID>a.ID)--只保留一条记录 4 go 5 alter table #T drop column ID--删除标识列 6 7 --查看结果 8 select * from #T
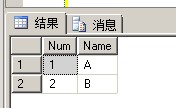
方法3:
1 declare Roy_Cursor cursor local for 2 select count(1)-1,Num,Name from #T group by Num,Name having count(1)>1 3 declare @con int,@Num int,@Name nvarchar(1) 4 open Roy_Cursor 5 fetch next from Roy_Cursor into @con,@Num,@Name 6 while @@Fetch_status=0 7 begin 8 set rowcount @con; 9 delete #T where Num=@Num and Name=@Name 10 set rowcount 0; 11 fetch next from Roy_Cursor into @con,@Num,@Name 12 end 13 close Roy_Cursor 14 deallocate Roy_Cursor 15 16 --查看结果 17 select * from #T

转载自:http://bbs.youkuaiyun.com/topics/240034273
如有不对的地方,欢迎大家拍砖o(∩_∩)o


















 2221
2221

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









