






 本文详细介绍了Redis中各种数据对象的底层实现,包括字符串、列表、哈希、集合和有序集合,以及支持这些数据对象的底层数据结构如简单动态字符串(SDS)、链表、字典、跳跃表和整数集合等。
本文详细介绍了Redis中各种数据对象的底层实现,包括字符串、列表、哈希、集合和有序集合,以及支持这些数据对象的底层数据结构如简单动态字符串(SDS)、链表、字典、跳跃表和整数集合等。

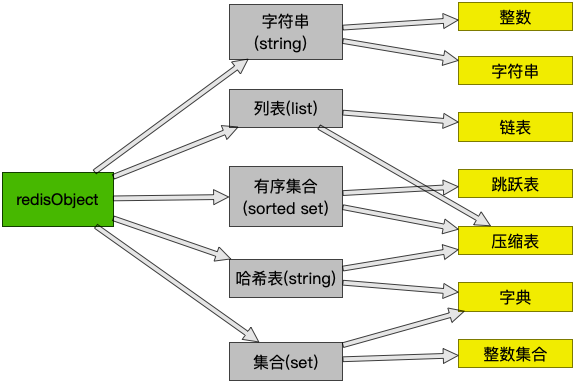
redis的数据库对象有五种,分别是字符串对象(key-value),列表对象(list),哈希对象(hash),集合对象(set),有序集合(sort set)。
这些数据对象来自于底层数据类型的实现,这些数据类型分别为简单动态字符串,链表,字典,跳跃表,整数集合,压缩列表,对象。
以下是redisObject和底层数据结构的关系
简单动态字符串(SDS)
redis的键(KEY)由简单动态字符串实现,字符串对象(key-value)也是由简单动态字符串实现的。而简单动态字符串是由C实现的,它的结构如下
struct sdshr{
//记录buf中已经使用的字节数量
unsigned int len;
//记录buf中未使用的字节数量
unsigned int free;
//字节数组,存储字符串
char buf[];
}在redis3.2版本后,SDS的结构发生了变化,有多种数据结构,根据情况使用
//字符串长度小于32 Byte
struct __attribute__ ((__packed__)) sdshdr5 {
unsigned char flags; /* 记录当前字节数组的属性,到底是哪个SDS结构 */
char buf[];/* 保存字符串真正的值 */
};
//字符串长度小于256 Byte,大于32 Byte
struct __attribute__ ((__packed__)) sdshdr8 {
uint8_t len; /* 记录当前数组的长度 */
uint8_t alloc; /* 记录了当前字节数组总共分配的内存大小 */
unsigned char flags; /* 记录当前字节数组的属性,到底是哪个SDS结构 */
char buf[];/* 保存字符串真正的值 */
};
//字符串长度小于65536 Byte (64KB),大于256 Byte
struct __attribute__ ((__packed__)) sdshdr16 {
uint16_t len; /* 记录当前数组的长度 */
uint16_t alloc; /* 记录了当前字节数组总共分配的内存大小 */
unsigned char flags; /* 记录当前字节数组的属性,到底是哪个SDS结构 */
char buf[];/* 保存字符串真正的值 */
};
//字符串长度小于4294967296 Byte (4GB),大于65536 Byte
struct __attribute__ ((__packed__)) sdshdr32 {
uint32_t len; /* 记录当前数组的长度 */
uint32_t alloc; /* 记录了当前字节数组总共分配的内存大小 */
unsigned char flags; /* 记录当前字节数组的属性,到底是哪个SDS结构 */
char buf[];/* 保存字符串真正的值 */
};
//字符串长度大于4294967296 Byte (4GB)
struct __attribute__ ((__packed__)) sdshdr64 {
uint64_t len; /* 记录当前数组的长度 */
uint64_t alloc; /* 记录了当前字节数组总共分配的内存大小 */
unsigned char flags; /* 记录当前字节数组的属性,到底是哪个SDS结构 */
char buf[];/* 保存字符串真正的值 */
};链表
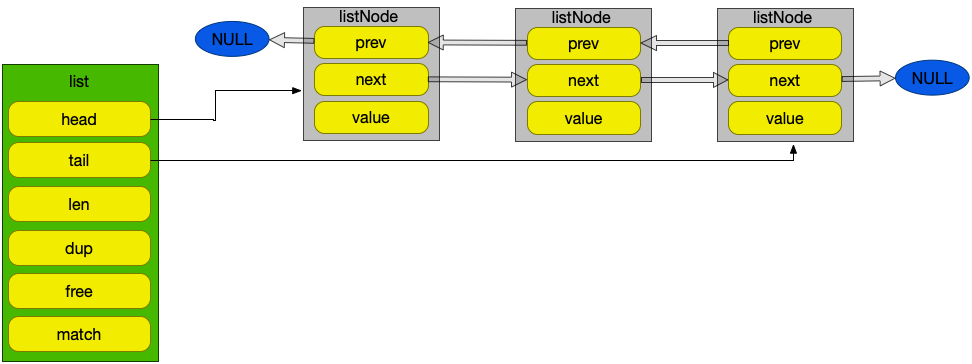
链表是redis对象列表(list)的一种实现。当列表中元素数量比较多,或元素中字符串数量比较大时,就会使用链表结构。链表方便顺序查询,同时也方便插入和删除。
链表由listNode和list组成,其结构如下
typedef struct listNode{
struct listNode *prev;//前一个节点
struct listNode * next;//后一个节点
void * value;//节点值
}typedef struct list{
//头节点
listNode * head;
//尾节点
listNode * tail;
//长度
unsigned long len;
//复制函数
void *(*dup) (void *ptr);
//释放函数
void (*free) (void *ptr);
//对比函数
int (*match)(void *ptr, void *key);
}结构图如下:
字典
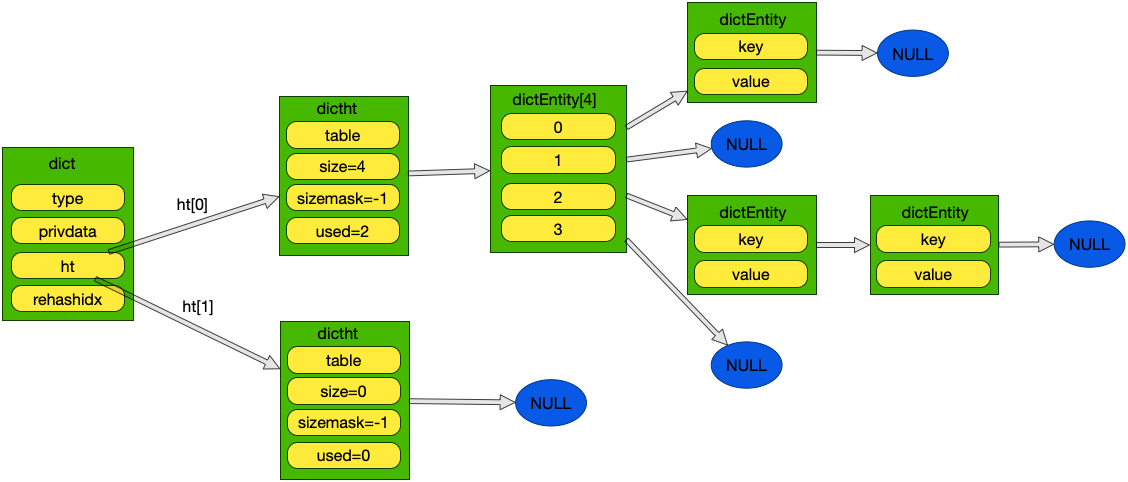
字典可以用来保存键值对,字典的结构和java的hashMap结构相似,采用hash算法保存key。字典由字典,哈希表,哈希表节点实现。其结构如下:
/*
* 哈希表节点
*/
typedef struct dictEntry {
// 键
void *key;
// 值,可以是三种形式:指针,8字节字符,8字节整数
union {
void *val;
uint64_t u64;
int64_t s64;
} v;
//指向下个哈希表节点,形成链表(如下hash冲突,会形成链表)
struct dictEntry *next;
} /*
* 哈希表
*/
typedef struct dictht {
// 哈希表数组
// 里面存储dictEntry
dictEntry **table;
// 哈希表大小
unsigned long size;
// 哈希表大小掩码,用于计算索引值
// 总是等于 size - 1,index = hash & sizemask
// 这样所有计算得出的hash值都可以对应于table的索引
unsigned long sizemask;
// 该哈希表已有节点的数量
unsigned long used;
}/*
* 字典
*/
typedef struct dict {
// 类型特定函数,type和privdata是为了多态字典所设置的
dictType *type;
// 私有数据
void *privdata;
// 哈希表,每个字典包含两个table
// ht[0]是平时使用的哈希表,ht[1]是rehash时使用的哈希表
dictht ht[2];
// rehash 索引标识
// 当 rehash 不在进行时,值为 -1
int rehashidx;
}字典结构图如下:
跳跃表
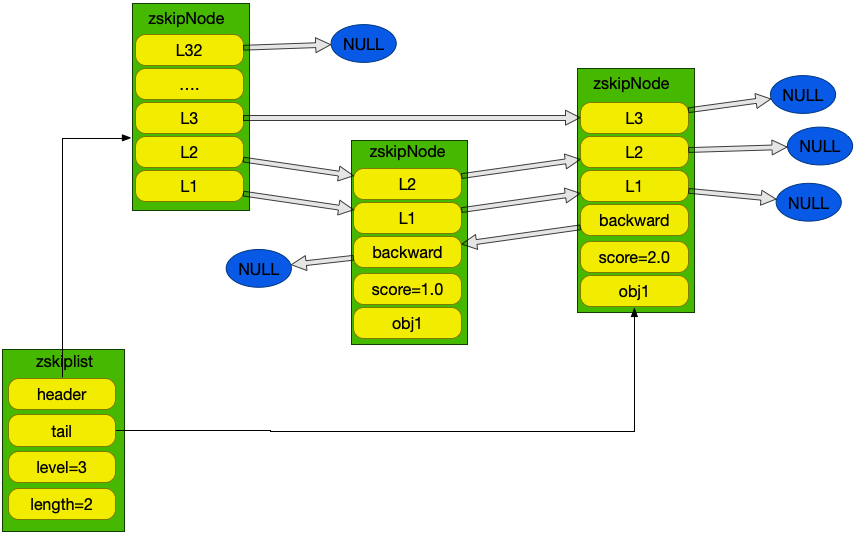
跳跃表是一种有序的数据结构,它通过score进行排序。跳跃表有层级的概念,每个跳跃表节点有多层,每个层级会按顺序指向之后若干节点的对应层级。这是为了便于查询,通过层级查询节点,会比按score顺序依次查询要快很多。节点和链表的结构如下:
typedef struct zskiplistNode{
//层
struct zskiplistLevel{
//前进指针
struct zskiplistNode *forward;
//跨度
unsigned int span;
} level[];
//后退指针
struct zskiplistNode *backward;
//分值
double score;
//成员对象
robj *obj;
}typedef struct zskiplist {
//表头节点和表尾节点
struct zskiplistNode *header,*tail;
//表中节点数量
unsigned long length;
//表中层数最大的节点的层数
int level;
}结构图如下:
整数集合
当一个集合的元素数量不大,且类型都为整数时,redis就会使用整数集合进行存储。它的结构如下:
typedef struct intset{
//编码方式
uint32_t enconding;
// 集合包含的元素数量
uint32_t length;
//保存元素的数组
int8_t contents[];
} 压缩列表
压缩列表是列表对象和哈希对象的实现方式之一。当一个列表的元素数量不多,且值为整数和不长的字符串,这时redis会使用压缩列表。同样如果一个哈希对象的key和value的值数量不多,且为整数和不长的字符串时,redis也会使用压缩列表
参考资料:
https://www.cnblogs.com/jaycekon/p/6227442.html
https://www.cnblogs.com/jaycekon/p/6277653.html

















 1656
1656

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









