



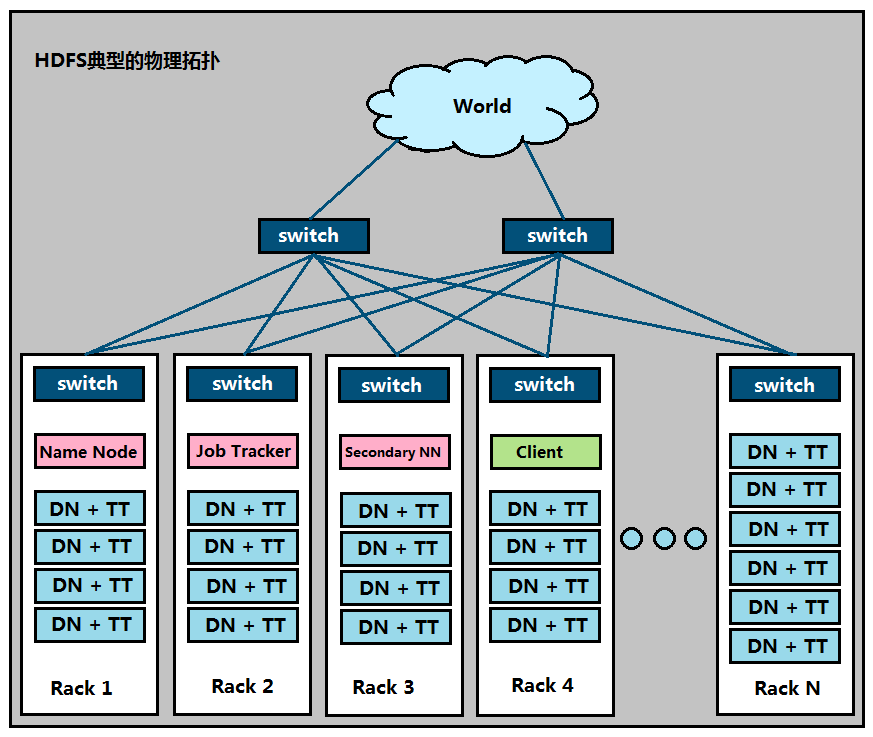
===================HDFS副本放置策略===================
一个文件划分成多个block,每个 block存多份,如何为每个block选 择节点存储这几份数据?
Block副本放置策略:
√副本1:同Client节点上
√副本2:不同机架的节点上
√副本3:与第二个副本同一机架的另一个节点上
√其他副本:随机挑选
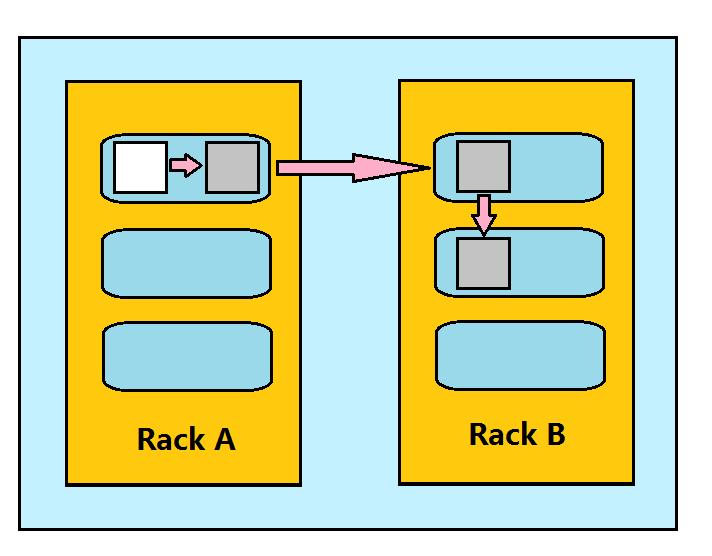
===================HDFS不适合存储小文件===================
元信息存储在NameNode内存中 ------------->
√一个节点的内存是有限的
存储大量小文件消耗大量的寻到时间 ------------->
√类比拷贝大量小文件与拷贝同等大小的一个大文件
NameNode存储block数目有限 ------------->
√一个block元信息消耗大约150byte内存
√存储1亿个block,大约需要20GB内存
√如果一个文件大小为10K,则1亿个文件大小仅为1TB(但要消耗掉 NameNode 20GB内存)

















 301
301

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









