



 本文详细介绍了Solr中Schema的概念及作用,包括字段定义、字段类型、分析器配置等内容,探讨了Schema的两种配置方式及其切换方法,适合Solr初学者及进阶者阅读。
本文详细介绍了Solr中Schema的概念及作用,包括字段定义、字段类型、分析器配置等内容,探讨了Schema的两种配置方式及其切换方法,适合Solr初学者及进阶者阅读。

Schema介绍
Schema 是什么?
问题1:在lucene中我们要对文档字段进行索引存储,需要如何做?
问题2:现在我们使用Solr搜索服务平台了,不需要编码了,还需要定义如何索引存储字段吗?
需要一种机制来定义、存储这些字段的索引信息,让solr运行时知道各个内核/集合的字段定义信息,这就是schema。
Schema:模式,是集合/内核中字段的定义,让solr知道集合/内核包含哪些字段、字段的数据类型、字段该索引存储。
Schema 的定义方式
Solr中提供了两种方式来配置schema,两者只能选其一
1.默认方式,通过Schema API 来实时配置,模式信息存储在 内核目录的conf/managed-schema文件中。
2.传统的手工编辑conf/schema.xml的方式,编辑完后需重载集合/内核才会生效。
Schema两种配置方式切换

schema.xml 到 managed schema
只需将 solrconfig.xml中的<schemaFactory class =“ClassicIndexSchemaFactory”/> 去掉,或改为ManagedIndexSchemaFactory Solr重启时,它发现存储schema.xml 但不存储在 managed-schema,它会备份schema.xml,然后改写schema.xml 为 managed-schema。此后就可以通过Schema API 管理schema了。
managed schema 到 schema.xml
将managed-schema 重命名为 schema.xml
将solrconfig.xml 中schemaFactory 的ManagedIndexSchemaFactory去掉(如果存在)
增加<schemaFactory class =“ClassicIndexSchemaFactory”/>
Schemaless mode
Solr还支持无模式方式,solr会猜测该如何索引字段,不可用在生成环境下。
查看 managed-schema文件,了解它的构成
<?xml version="1.0" encoding="UTF-8" ?>
<schema version="1.6">
<field .../>
<dynamicField .../>
<uniqueKey>id</uniqueKey>
<copyField .../>
<fieldType ...>
<analyzer type="index">
<tokenizer .../>
<filter ... />
</analyzer>
<analyzer type="query">
<tokenizer.../>
<filter ... />
</analyzer>
</fieldType>
</schema>
字段定义详解
字段定义示例
<field name="name" type="text_general" indexed="true" stored="true"/>
<field name="includes" type="text_general" indexed="true" stored="true" termVectors="true" termPositions="true" termOffsets="true" />好熟悉的感觉!
问1:lucene中字段包含哪几个属性?
疑惑:这里的type和lucene中字段的type是一回事吗?
字段属性说明
name:字段名,必需。字段名可以由字母、数字、下划线构成,不能以数字开头。以下划线开头和结尾的名字为保留字段名,如 _version_
type:字段的fieldType名,必需。为 FieldType定义的name 属性值。
default:默认值,如果提交的文档中没有该字段的值,则自动会为文档添加这个默认值。非必需。
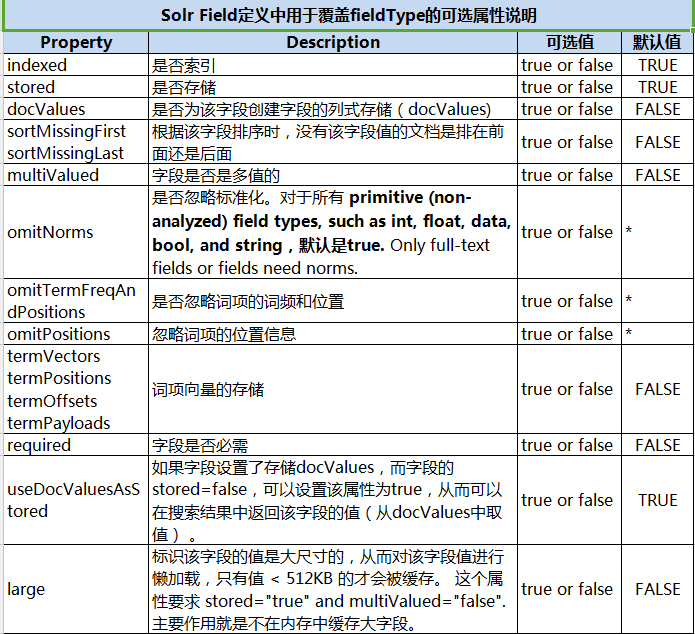
字段中用于覆盖fieldType的可选属性说明
FieldType字段类型
定义在索引时该如何分词、索引、存储字段,在查询时该如何对查询串分词
<fieldType name="managed_en" class="solr.TextField" positionIncrementGap="100">
<analyzer type="index">
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.ManagedStopFilterFactory" managed="english" />
<filter class="solr.ManagedSynonymGraphFilterFactory" managed="english" />
<filter class="solr.FlattenGraphFilterFactory"/>
</analyzer>
<analyzer type="query">
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.ManagedStopFilterFactory" managed="english" />
<filter class="solr.ManagedSynonymGraphFilterFactory" managed="english" />
</analyzer>
</fieldType>FieldType 的属性
Solr中提供的 FieldType 类,在 org.apache.solr.schema 包下
http://lucene.apache.org/solr/guide/7_3/field-types-included-with-solr.html
FieldType 的 Analyzer
对于 solr.TextField or solr.SortableTextField 字段类型,需要为其定义分析器。
<fieldType name="nametext" class="solr.TextField">
<analyzer class="org.apache.lucene.analysis.core.WhitespaceAnalyzer"/>
</fieldType>可以直接通过class属性指定分析器类,必须继承
org.apache.lucene.analysis.Analyzer 。
也可灵活地组合分词器、过滤器:
<fieldType name="nametext" class="solr.TextField">
<analyzer>
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.StandardFilterFactory"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.StopFilterFactory"/>
</analyzer>
</fieldType>org.apache.solr.analysis 包下的类可以简写为 solr.xxx
如果该类型字段索引、查询时需要使用不同的分析器,则需区分配置analyzer
<fieldType name="nametext" class="solr.TextField">
<analyzer type="index">
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.KeepWordFilterFactory" words="keepwords.txt"/>
<filter class="solr.SynonymFilterFactory" synonyms="syns.txt"/>
</analyzer>
<analyzer type="query">
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
</fieldType>Solr中提供的tokenizer: http://lucene.apache.org/solr/guide/7_3/tokenizers.html
Solr中提供的 fiter: http://lucene.apache.org/solr/guide/7_3/filter-descriptions.html
常用的Filter
Stop Filter 停用词过滤器
<analyzer>
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.StopFilterFactory" words="stopwords.txt"/>
</analyzer>
words属性指定停用词文件的绝对路径或相对 conf/目录的相对路径
停用词定义语法:一行一个
Synonym Graph Filter 同义词过滤器
<analyzer type="index">
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.SynonymGraphFilterFactory" synonyms="mysynonyms.txt"/>
<filter class="solr.FlattenGraphFilterFactory"/> <!-- required on index analyzers after graph filters -->
</analyzer>
<analyzer type="query">
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.SynonymGraphFilterFactory" synonyms="mysynonyms.txt"/>
</analyzer>
同义词定义语法
couch,sofa,divan
teh => the
huge,ginormous,humungous => large
small => tiny,teeny,weeny一类一行, =>表示标准化为后面的
Filter 练习1
1、往停用词文件中添加
hello
like
2、往同义词文件中添加
couch,sofa,divan
teh => the
huge,ginormous,humungous => large
small => tiny,teeny,weeny
3、用下面的短语在web管理控制台进行测试
停用词测试: Hello world, do you like apple
同义词测试: teh small couch
集成IKAnalyzer 中文分词器
1、在原来学习lucene集成IKAnalyzer的基础上,为IkAnalyzer实现一个TokenizerFactory(继承它),接收useSmart参数。
2、将这三个类打成jar,如 IKAnalyzer-lucene7.3.jar
3、将这个jar和 IKAnalyzer的jar 拷贝到web应用的lib目录下
4、将三个配置文件拷贝到应用的classes目录下
5、在schema中定义一个FieldType,使用IKAnalyzer适配类
<fieldType name=“zh_CN _text" class="solr.TextField">
<analyzer>
<tokenizer class="com.dongnao.lucene.demo.analizer.ik.IKTokenizer4Lucene7Factory" useSmart="true" />
</analyzer>
</fieldType>
FieldType 练习2
1、定义一个FieldType,索引的分词器用IKAnalyzer,查询的分词器用IKAnaylzer + 同义词Filter。
2、配置同义词:
相同,相似,相近
电脑,笔记本电脑=>计算机
3、测试分词:
他的电脑和她的笔记本电脑很相似
CopyField 复制字段
复制字段允许将一个或多个字段的值填充到一个字段中。它的用途有两种:
1、将多个字段内容填充到一个字段,来进行搜索
2、对同一个字段内容进行不同的分词过滤,创建一个新的可搜索字段
定义方式:
1、先定义一个普通字段
<field name="cc_all" type="zh_CN_text" indexed="true" stored="false" multiValued="false" />
2、定义复制字段
<copyField source="cat" dest="cc_all"/>
<copyField source="name" dest="cc_all"/>

















 446
446

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









