






 本文详细介绍了Spark中combineByKey算子的工作原理及使用方法,并通过一个具体示例展示了如何利用该算子来处理和聚合数据。
本文详细介绍了Spark中combineByKey算子的工作原理及使用方法,并通过一个具体示例展示了如何利用该算子来处理和聚合数据。
1、combineByKey
combine 为结合意思。
作用: 将RDD[(K,V)] => RDD[(K,C)] 表示V的类型可以转成C两者可以不同类型。
def combineByKey[C](createCombiner:V =>C ,mergeValue:(C,V) =>C, mergeCombiners:(C,C) =>C):RDD[(K,C)]
def combineByKey[C](createCombiner:V =>C ,mergeValue:(C,V) =>C, mergeCombiners:(C,C) =>C,numPartitions:Int ):RDD[(K,C)]
def combineByKey[C](createCombiner:V =>C ,mergeValue:(C,V) =>C, mergeCombiners:(C,C) =>C,partitioner:Partitioner,mapSideCombine:Boolean=true,serializer:Serializer= null):RDD[(K,C)]
第一个函数和第二个函数默认使用的是HashPartitioner、serialize为null。
这个算子还是比较复杂,解释下:
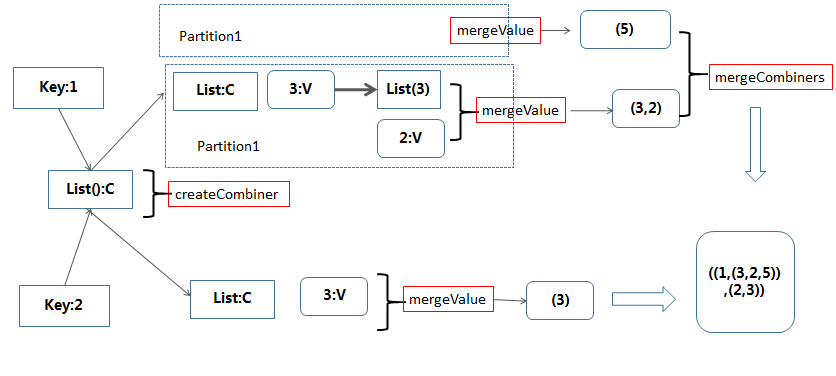
1)createCombiner:在遍历RDD的数据集合过程中,对于遍历到的(k,v),如果combineByKey第一次遇到值为k的Key(类型K),那么将对这个(k,v)调用 createCombiner函数,它的作用是将v转换为c(类型是C,聚合对象的类型,c作为局和对象的初始值)
2)mergeValue: 在遍历RDD的数据集合过程中,对于遍历到的(k,v),如果combineByKey不是第一次(或者第二次,第三次…)遇到值为k的Key(类型K),那么将对这个 (k,v)调用mergeValue函数,它的作用是将v累加到聚合对象(类型C)中,mergeValue的类型是(C,V)=>C,参数中的C遍历到此处的聚合对象,然后对v 进行聚合得到新的聚合对象值。
3)mergeCombiners:因为combineByKey是在分布式环境下执行,RDD的每个分区单独进行combineByKey操作,
最后需要对各个分区的结果进行最后的聚合,它的函数类型是(C,C)=>C,每个参数是分区聚合得到的聚合对象
例子:
scala> val data = sc.parallelize(List(("1","3"),("1","2"),("1","5"),("2","3")))
scala> val natPairRdd = data.combineByKey(List(_), (c: List[String], v: String) => v::c, (c1: List[String], c2: List[String]) => c1 ::: c2)
scala> natPairRdd.collect
res0: Array[(String, List[String])] = Array((1,List(3, 2, 5)), (2,List(3)))


















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









