



 本文深入浅出地介绍了正则表达式的各种符号及其应用场景,包括如何匹配重复字符、网站格式及Ascii码超过255的字符等。通过具体实例帮助读者理解并掌握正则表达式的使用技巧。
本文深入浅出地介绍了正则表达式的各种符号及其应用场景,包括如何匹配重复字符、网站格式及Ascii码超过255的字符等。通过具体实例帮助读者理解并掌握正则表达式的使用技巧。
注意验证的时候不要出现什么中文括号之类的 看又看不出 会坑死自己)
1.rub+b
可以匹配rubb / rubbb 但不能匹配 rubab
所以只能匹配rub+(任意的(大于1个)b)
2.rub*b
匹配rub+(任意数量的b可以为0)
3.rua?b
?代表前面的字符最多只可以出现1次
也就是只匹配ruab或者rub
4.转义字符‘/
5.{n},{n,}
n 是一个非负整数。匹配确定的 n 次(注意是指前面的字符)
比如g{3}nb只匹配gggnb
{n,}
a{2,}g 匹配2个以上的a +g
a{2,4}g 匹配2个到4个a+g
6.‘.’任意字符
7.‘^’从开始处的文本开始匹配 ‘$’匹配结束处
8.ter\b 以空格为一个单词 匹配以ter结尾的单词
Chapter aater 12ddsdater 则匹配到3个
9.\w 相当于([0-9a-zA-Z_]) 匹配字母或下划线或汉字(甚至还包括一些希腊字母,俄文的字母)
10.\d匹配数字
11.\s匹配任意的空白符
12./g 表示该表达式将用来在输入字符串中查找所有可能的匹配,返回的结果可以是多个。如果不加/g最多只会匹配一个
13./i 表示匹配的时候不区分大小写
14./m多行匹配 比如说出现/n的换行符时
15./s 单行匹配
16./x 忽略空白
17.‘\1’ 匹配的是 所获取的第1个()匹配的引用。
18.‘\2’ 匹配的是 所获取的第2个()匹配的引用。
结合实例
(1)匹配重复字符
var str = "Is is the cost of of gasoline going up up";
var patt1 = /\b([a-z]+) \1\b/ig;
解析: \b([a-z]+) 从小写字符串开始匹配
\1 重复匹配一遍\b([a-z]+) 比如 前面匹配过的字符串abc 他需要再出现abc一次才匹配
所以我们先用 \b([a-z]+) \1 如图测试
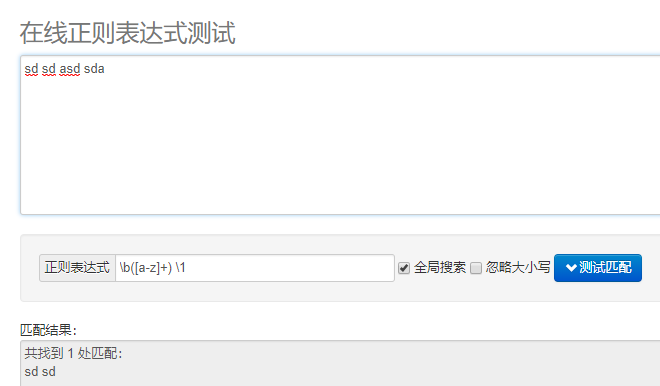
只匹配到一次重复
而/ig则是(全文查找、忽略大小写)
匹配结果为 Is is of of up up
(2)匹配网站格式
(\w+):\/\/([^/:]+)(:\d*)?([^# ]*) (这里可能包括中文括号等字符,测试请自行转化)
解析我们拆成几部分
1.(\w+):\/\/ 至少一个的字母或下划线或汉字+:// => 比如www://
2.([^/:]+)仍以数量的:开头的匹配 => :aa:bb:cc =>匹配aa ,bb,cc
3.(:\d*)? 匹配最多一个‘:’+数字 :80=> 匹配为 :80 (匹配端口)
4.([^#]*) 匹配任意字符多次(文件路径)。
(3)匹配Ascii码大于255
[^\x00-\xFF]

















 564
564

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









