



 本文提供了两种常见的停车入库方法,包括车身位置调整、倒车角度控制等细节,并强调了慢速、回头观察、寻找参照物等注意事项。
本文提供了两种常见的停车入库方法,包括车身位置调整、倒车角度控制等细节,并强调了慢速、回头观察、寻找参照物等注意事项。
方法一:
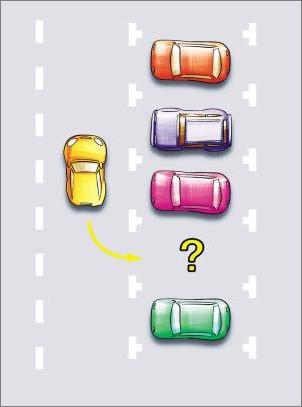
车身调正,保持与旁车1米左右的间距
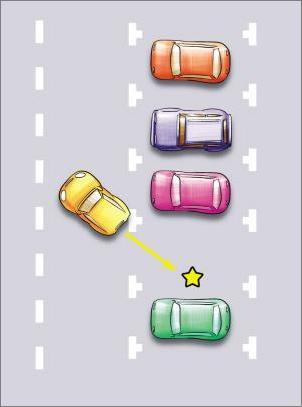
开始倒库,用右后轮去找轮胎点,当轮胎过了库右上角的轮胎点后,马上将方向打满
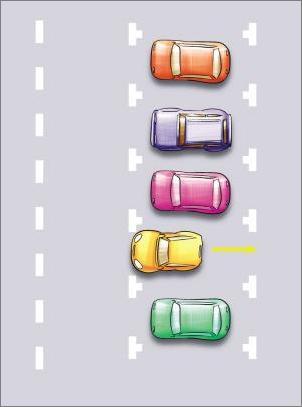
车身位置调正后,将方向盘调正,然后继续倒车,直至车身完全入库
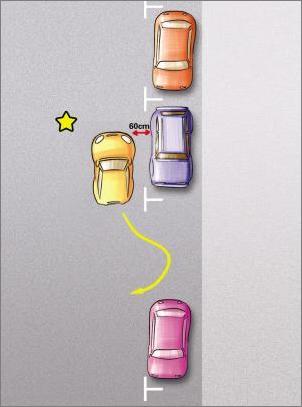
保持自己的车与前车间距60厘米左右并调到平齐位置
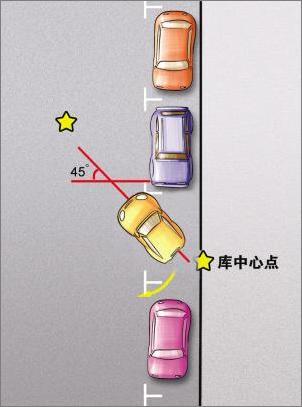
用车尾去找车库的中心点,然后保持约45度角的位置入库。
当车尾快碰到马路牙子后,快速反打方向盘,将车头送入车位,最后微调即可
另外,还有几点需要注意:
一是要慢。无论多熟练的司机开车也会慢慢地将车倒进车库,道理不用多说,后眼谁也没长,难免后边突然蹿出个人来或地面上有个栏杆的,这时较慢的车速会给你赢得更多的安全时间。
二是要看。正常人在从镜子里看反射物时都会多多少少产生些误差,所以为了能更好地看清车后部的状况,奉劝女司机们一定要养成回头看路的好习惯。
笔者曾亲眼目睹过女司机看着反光镜头也不回地倒车,结果弯儿都没拐就朝着障碍物去了,教训啊!
三是找记号。这里说的记号可不是让你跟在驾校考试似的,在车上用红油漆画个道,再在车库上系根绳,而是要刻意地用眼睛去找你车头或车尾部的所谓的记号点,然后用这个点再去瞄车库的尽头,这样就可以进去了。
四是勤练。我曾碰到过不止一位女司机只会“鸵鸟式”进库,一头扎不进去就不管了,斜着将车往那儿一摆,多一把都不肯揉。其实开车就是一个经验活儿,只有不停地练习才会越开越溜。我刚学开车时也经常发生入位不正或进不去库的情况,这时我多半会边揉边下车观察,看看离前后车都还有多少量,再一边往库里揉,直到车身笔直地停在车位里才罢休。
五是倒库更容易。其实倒库是最容易将车开进狭小车位的方法。因为一般车头都会比车尾长,这样正着进库就需要更大的行进距离,对于较宽大的车位还好说,要是前后车留的量都很小可就费劲了。而且一旦车辆仍旧需要调整停靠位置,不停地上下移动车辆也会消耗较大体力,所以最佳的入位方法是倒库。
PS
1.女司机平时停车最好选择有人职守的停车场,万一揉不进库还可以找个帮手。
2.夜间最好不要将车停到地下车库,因为车库的人较少,不利于女司机的人身安全。
3.选择熟的地方停车可以大大减少发生剐蹭的几率。
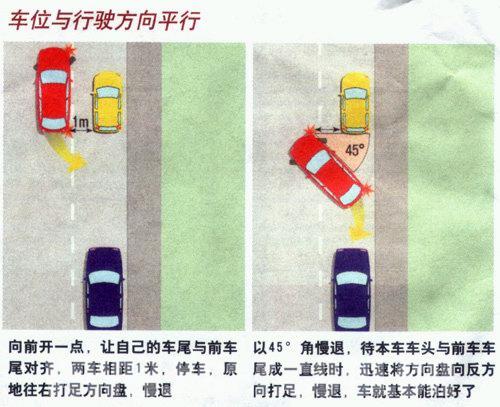
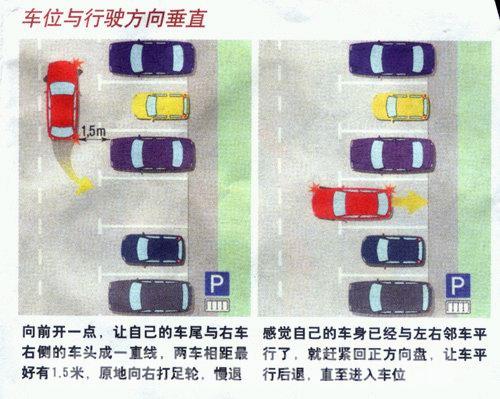
斜线停车




倒车视频
http://you.video.sina.com.cn/b/373536-1013970455.html
http://you.video.sina.com.cn/b/373536-1013970455.html


















 4511
4511

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









