



 在不告知文件编码时,探测文件编码无绝对正确方法,只有成功率大小之分。文中列出常用识别文件编码的方法,如根据常见编码文件开头识别,通过文件前三个字节判断,读取文件字段进行特殊编码字符判断,还可通过工具库cpdetector获取文件编码。
在不告知文件编码时,探测文件编码无绝对正确方法,只有成功率大小之分。文中列出常用识别文件编码的方法,如根据常见编码文件开头识别,通过文件前三个字节判断,读取文件字段进行特殊编码字符判断,还可通过工具库cpdetector获取文件编码。

在不告知文件编码的情况下,通过一定的手段去探测文件的编码,几乎没有任何一种方法是绝对正确的。只有成功率大小的问题。一下列出几个常用的识别文件编码的方法。
常见的编码文件的开头来识别文件编码:
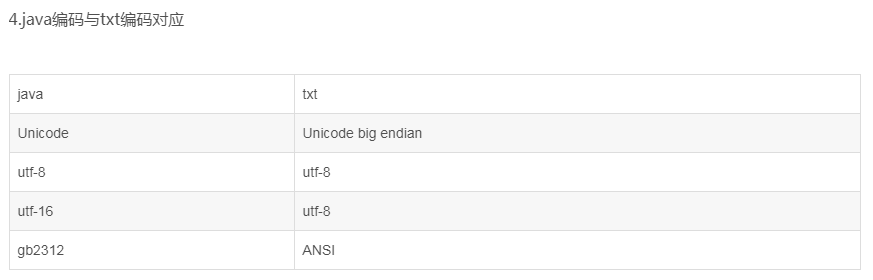
ANSI: 无格式定义
Unicode: 前两个字节为FFFE Unicode文档以0xFFFE开头
Unicode big endian: 前两字节为FEFF
UTF-8: 前两字节为EFBB UTF-8以0xEFBBBF开头
1、通过文件的前三个字节来判断
public static String codeString(String fileName) throws Exception {
BufferedInputStream bin = new BufferedInputStream(new FileInputStream(fileName));
int p = (bin.read() << 8) + bin.read();
bin.close();
String code = null;
switch (p) {
case 0xefbb:
code = "UTF-8";
break;
case 0xfffe:
code = "Unicode";
break;
case 0xfeff:
code = "UTF-16BE";
break;
default:
code = "GBK";
}
return code;
}2、判断前三个字节出错率还是蛮大的,还可以进一步读取文件的字段,进行特殊编码字符的判断来确定文件编码
/**
* 判断文本文件的字符集,文件开头三个字节表明编码格式。
* <a href="http://blog.163.com/wf_shunqiziran/blog/static/176307209201258102217810/">参考的博客地址</a>
*
* @param path
* @return
* @throws Exception
* @throws Exception
*/
public static String charset(String path) {
String charset = "GBK";
byte[] first3Bytes = new byte[3];
try {
boolean checked = false;
BufferedInputStream bis = new BufferedInputStream(new FileInputStream(path));
bis.mark(0); // 读者注: bis.mark(0);修改为 bis.mark(100);我用过这段代码,需要修改上面标出的地方。
// Wagsn注:不过暂时使用正常,遂不改之
int read = bis.read(first3Bytes, 0, 3);
if (read == -1) {
bis.close();
return charset; // 文件编码为 ANSI
} else if (first3Bytes[0] == (byte) 0xFF && first3Bytes[1] == (byte) 0xFE) {
charset = "UTF-16LE"; // 文件编码为 Unicode
checked = true;
} else if (first3Bytes[0] == (byte) 0xFE && first3Bytes[1] == (byte) 0xFF) {
charset = "UTF-16BE"; // 文件编码为 Unicode big endian
checked = true;
} else if (first3Bytes[0] == (byte) 0xEF && first3Bytes[1] == (byte) 0xBB
&& first3Bytes[2] == (byte) 0xBF) {
charset = "UTF-8"; // 文件编码为 UTF-8
checked = true;
}
bis.reset();
if (!checked) {
while ((read = bis.read()) != -1) {
if (read >= 0xF0)
break;
if (0x80 <= read && read <= 0xBF) // 单独出现BF以下的,也算是GBK
break;
if (0xC0 <= read && read <= 0xDF) {
read = bis.read();
if (0x80 <= read && read <= 0xBF) // 双字节 (0xC0 - 0xDF)
// (0x80 - 0xBF),也可能在GB编码内
continue;
else
break;
} else if (0xE0 <= read && read <= 0xEF) { // 也有可能出错,但是几率较小
read = bis.read();
if (0x80 <= read && read <= 0xBF) {
read = bis.read();
if (0x80 <= read && read <= 0xBF) {
charset = "UTF-8";
break;
} else
break;
} else
break;
}
}
}
bis.close();
} catch (Exception e) {
e.printStackTrace();
}
System.out.println("--文件-> [" + path + "] 采用的字符集为: [" + charset + "]");
return charset;
}
3、通过工具库cpdetector来获取文件编码
/**
* <div>
* 利用第三方开源包cpdetector获取文件编码格式.<br/>
* --1、cpDetector内置了一些常用的探测实现类,这些探测实现类的实例可以通过add方法加进来,
* 如:ParsingDetector、 JChardetFacade、ASCIIDetector、UnicodeDetector. <br/>
* --2、detector按照“谁最先返回非空的探测结果,就以该结果为准”的原则. <br/>
* --3、cpDetector是基于统计学原理的,不保证完全正确.<br/>
* </div>
* @param filePath
* @return 返回文件编码类型:GBK、UTF-8、UTF-16BE、ISO_8859_1
* @throws Exception
*/
public static String getFileCharset(String filePath) throws Exception {
CodepageDetectorProxy detector = CodepageDetectorProxy.getInstance();
/*ParsingDetector可用于检查HTML、XML等文件或字符流的编码,
* 构造方法中的参数用于指示是否显示探测过程的详细信息,为false不显示。
*/
detector.add(new ParsingDetector(false));
/*JChardetFacade封装了由Mozilla组织提供的JChardet,它可以完成大多数文件的编码测定。
* 所以,一般有了这个探测器就可满足大多数项目的要求,如果你还不放心,可以再多加几个探测器,
* 比如下面的ASCIIDetector、UnicodeDetector等。
*/
detector.add(JChardetFacade.getInstance());
detector.add(ASCIIDetector.getInstance());
detector.add(UnicodeDetector.getInstance());
Charset charset = null;
File file = new File(filePath);
try {
//charset = detector.detectCodepage(file.toURI().toURL());
InputStream is = new BufferedInputStream(new FileInputStream(filePath));
charset = detector.detectCodepage(is, 8);
} catch (Exception e) {
e.printStackTrace();
throw e;
}
String charsetName = "GBK";
if (charset != null) {
if (charset.name().equals("US-ASCII")) {
charsetName = "ISO_8859_1";
} else if (charset.name().startsWith("UTF")) {
charsetName = charset.name();// 例如:UTF-8,UTF-16BE.
}
}
return charsetName;
}

















 9294
9294

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









