






转载请注明出处
- 相信很多人看这篇文章已经知道连接池是用来干什么的?没错,数据库连接池就是为数据库连接建立一个“缓冲池”,预先在“缓冲池”中放入一定数量的连接欸,当需要建立数据库连接时,从“缓冲池”中取出一个,使用完毕后再放进去。这样的好处是,可以避免频繁的进行数据库连接占用很多的系统资源。
- 常见的数据库连接池有:dbcp,c3p0,阿里的Druid。好了,闲话不多说,本篇文章旨在加深大家对连接池的理解。这里我选用的数据库是mysql。
- 先讲讲连接池的流程:
- 首先要有一份配置文件吧!我们在日常的项目中使用数据源时,需要配置数据库驱动,数据库用户名,数据库密码,连接。这四个角色万万不可以少。
#文件名:db.properties jdbc.driver = com.mysql.jdbc.Driver jdbc.url =jdbc:mysql: // localhost:3306/ssm jdbc.username= root jdbc.password = lfdy jdbc.initSize =3 jdbc.maxSize =10 #是否启动检查 jdbc.health = true #检查延迟时间 jdbc.delay =3000 #间隔时间 jdbc.period =3000 jdbc.timeout =100000
2. 我们要根据上述的配置文件db.properties编写一个类,并加载其属性
public class GPConfig { private String driver; private String url; private String username; private String password; private String initSize; private String maxSize; private String health; private String delay; private String period; private String timeout; //省略set和get方法// 编写构造器,在构造器中对属性进行初始化 public GPConfig() { Properties prop = new Properties(); // maven项目中读取文件好像只有这中方式 InputStream stream = this .getClass().getResourceAsStream("/resource/db.properties" ); try { prop.load(stream); // 在构造器中调用setter方法,这里属性比较多,我们肯定不是一步一步的调用,建议使用反射机制 for (Object obj : prop.keySet()){ // 获取形参,怎么获取呢?这不就是配置文件的key去掉,去掉什么呢?去掉"jdbc." String fieldName = obj.toString().replace("jdbc.", "" ); Field field = this .getClass().getDeclaredField(fieldName); Method method = this .getClass().getMethod(toUpper(fieldName), field.getType()); method.invoke( this , prop.get(obj)); } } catch (Exception e) { e.printStackTrace(); } } // 读取配置文件中的key,并把他转成正确的set方法 public String toUpper(String fieldName){ char [] chars = fieldName.toCharArray(); chars[ 0] -=32; // 如何把一个字符串的首字母变成大写 return "set"+ new String(chars); } }
3.好了,我们配置文件写好了,加载配置文件的类也写好了,接下来写什么呢?回忆一下,我们在没有连接池前,是不是用Class.forName(),getConnection等等来连接数据库的?所以,我们接下来编写一个类,这个类中有创建连接,获取连接的方法。
public class GPPoolDataSource { // 加载配置类 GPConfig config = new GPConfig(); // 写一个参数,用来标记当前有多少个活跃的连接 private AtomicInteger currentActive = new AtomicInteger(0 ); // 创建一个集合,干嘛的呢?用来存放连接,毕竟我们刚刚初始化的时候就需要创建initSize个连接 // 并且,当我们释放连接的时候,我们就把连接放到这里面 Vector<Connection> freePools = new Vector<> (); // 正在使用的连接池 Vector<GPPoolEntry> usePools = new Vector<> (); // 构造器中初始化 public GPPoolDataSource(){ init(); } // 初始化方法 public void init(){ try { // 我们的jdbc是不是每次都要加载呢?肯定不是的,只要加载一次就够了 Class.forName(config.getDriver()); for ( int i = 0; i < Integer.valueOf(config.getInitSize());i++ ){ Connection conn = createConn(); freePools.add(conn); } } catch (ClassNotFoundException e) { e.printStackTrace(); } check(); } // 创建连接 public synchronized Connection createConn(){ Connection conn = null ; try { conn = DriverManager.getConnection(config.getUrl(), config.getUsername(), config.getPassword()); currentActive.incrementAndGet(); System.out.println( "创建一个连接,当前的活跃的连接数目为:"+ currentActive.get()+"连接:"+ conn); } catch (SQLException e) { e.printStackTrace(); } return conn; } /** * 创建连接有了,是不是也应该获取连接呢? * @return */ public synchronized GPPoolEntry getConn(){ Connection conn = null ; if (! freePools.isEmpty()){ conn = freePools.get(0 ); freePools.remove( 0 ); } else { if (currentActive.get() < Integer.valueOf(config.getMaxSize())){ conn = createConn(); } else { try { System.out.println( "连接池已经满了,需要等待..." ); wait( 1000 ); return getConn(); } catch (InterruptedException e) { e.printStackTrace(); } } } GPPoolEntry poolEntry = new GPPoolEntry(conn, System.currentTimeMillis()); // 获取连接干嘛的?不就是使用的吗?所以,每获取一个,就放入正在使用池中 usePools.add(poolEntry); return poolEntry; } /** * 创建连接,获取连接都已经有了,接下来就是该释放连接了 */ public synchronized void release(Connection conn){ try { if (!conn.isClosed() && conn != null ){ freePools.add(conn); } System.out.println( "回收了一个连接,当前空闲连接数为:"+ freePools.size()); } catch (SQLException e) { e.printStackTrace(); } } // 定时检查占用时间超长的连接,并关闭 private void check(){ if (Boolean.valueOf(config.getHealth())){ Worker worker = new Worker(); new java.util.Timer().schedule(worker, Long.valueOf(config.getDelay()), Long.valueOf(config.getPeriod())); } } class Worker extends TimerTask{ @Override public void run() { System.out.println( "例行检查..." ); for ( int i = 0; i < usePools.size();i++ ){ GPPoolEntry entry = usePools.get(i); long startTime = entry.getUseStartTime(); long currentTime = System.currentTimeMillis(); if ((currentTime-startTime)> Long.valueOf(config.getTimeout())){ Connection conn = entry.getConn(); try { if (conn != null && ! conn.isClosed()){ conn.close(); usePools.remove(i); currentActive.decrementAndGet(); System.out.println( "发现有超时连接,强行关闭,当前活动的连接数:"+ currentActive.get()); } } catch (SQLException e) { e.printStackTrace(); } } } } } }
4.在上述的check()方法中,要检查是否超时,所以我们需要用一个包装类
public class GPPoolEntry { private Connection conn; private long useStartTime; public Connection getConn() { return conn; } public void setConn(Connection conn) { this .conn = conn; } public long getUseStartTime() { return useStartTime; } public void setUseStartTime( long useStartTime) { this .useStartTime = useStartTime; } public GPPoolEntry(Connection conn, long useStartTime) { super (); this .conn = conn; this .useStartTime = useStartTime; } }
5.好了,万事具备,我们写一个测试类测试一下吧
public class GPDataSourceTest { public static void main(String[] args) { GPPoolDataSource dataSource = new GPPoolDataSource(); Runnable runnable = () -> { Connection conn = dataSource.getConn().getConn(); System.out.println(conn); }; ExecutorService executorService = Executors.newFixedThreadPool(5 ); for ( int i = 0; i < 60; i++ ) { executorService.submit(runnable); } executorService.shutdown(); } }
4.好了,我给下我的结果:
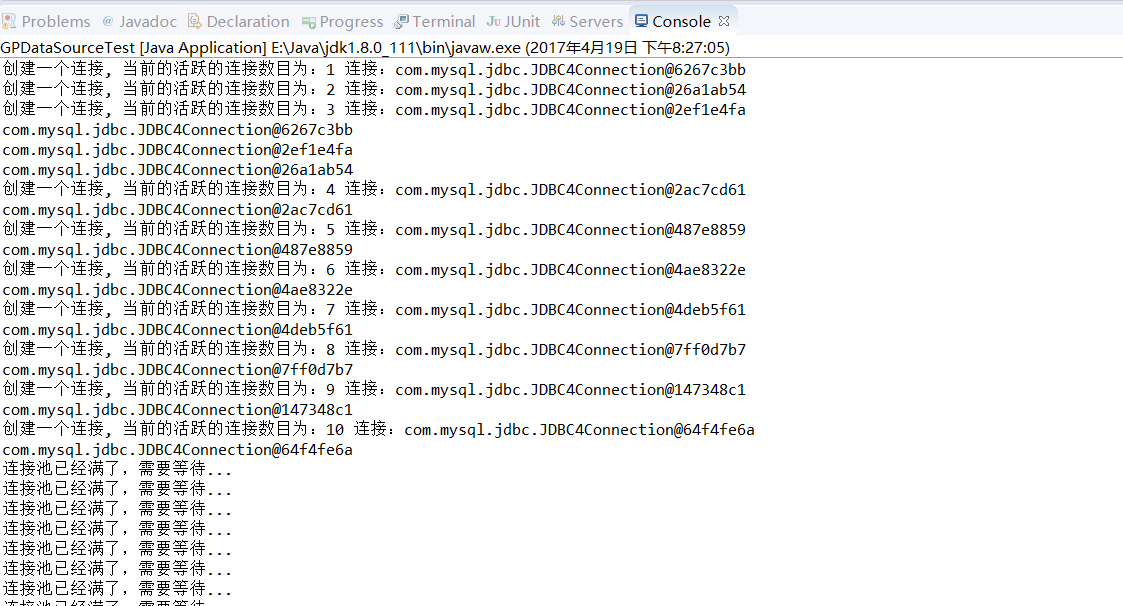
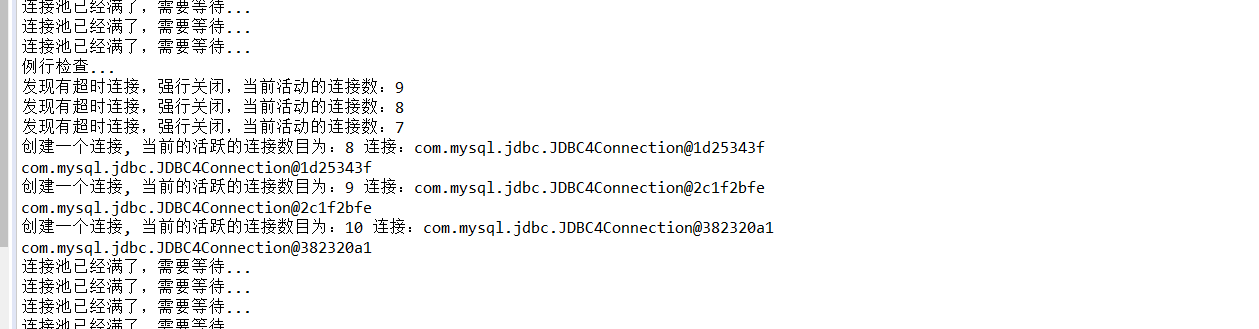
5.总结下,这个手写连接池部分,其实我也是学习的别人的,所以有很多东西不熟悉,也有许多漏洞,现在我先说下我需要完善的地方:
-
- 反射机制
- 读取properties文件
- 线程池
- 线程
- 集合Vector

















 1363
1363

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









