



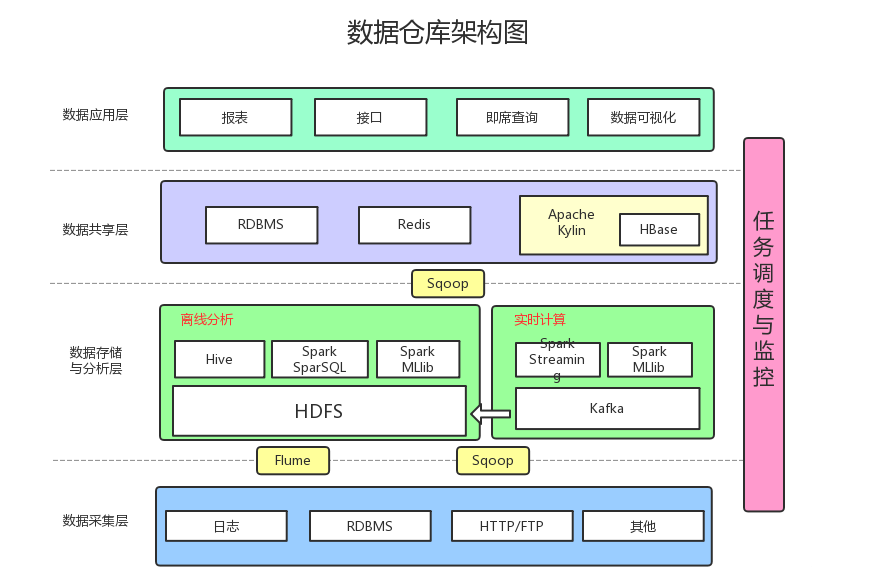
数据采集:采用Flume收集日志,采用Sqoop将RDBMS以及NoSQL中的数据同步到HDFS上
消息系统:可以加入Kafka防止数据丢失
实时计算:实时计算使用Spark Streaming消费Kafka中收集的日志数据,实时计算结果大多保存在Redis中
机器学习:使用了Spark MLlib提供的机器学习算法
多维分析OLAP:使用Kylin作为OLAP引擎
数据可视化:提供可视化前端页面,方便运营等非开发人员直接查询
 本文介绍了一种基于Flume、Kafka、SparkStreaming、Redis、SparkMLlib、Kylin和可视化前端的大数据实时处理与分析架构。该架构通过Flume收集日志,使用Sqoop同步RDBMS和NoSQL数据至HDFS,Kafka确保数据不丢失,SparkStreaming实现实时计算并将结果存入Redis,利用SparkMLlib进行机器学习,Kylin作为OLAP引擎支持多维分析,同时提供可视化界面供非技术人员使用。
本文介绍了一种基于Flume、Kafka、SparkStreaming、Redis、SparkMLlib、Kylin和可视化前端的大数据实时处理与分析架构。该架构通过Flume收集日志,使用Sqoop同步RDBMS和NoSQL数据至HDFS,Kafka确保数据不丢失,SparkStreaming实现实时计算并将结果存入Redis,利用SparkMLlib进行机器学习,Kylin作为OLAP引擎支持多维分析,同时提供可视化界面供非技术人员使用。
数据采集:采用Flume收集日志,采用Sqoop将RDBMS以及NoSQL中的数据同步到HDFS上
消息系统:可以加入Kafka防止数据丢失
实时计算:实时计算使用Spark Streaming消费Kafka中收集的日志数据,实时计算结果大多保存在Redis中
机器学习:使用了Spark MLlib提供的机器学习算法
多维分析OLAP:使用Kylin作为OLAP引擎
数据可视化:提供可视化前端页面,方便运营等非开发人员直接查询
转载于:https://www.cnblogs.com/chengjianxiaoxue/p/10219055.html

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言


























