 Azure Table 存储设计指南
Azure Table 存储设计指南







 本文档提供了Azure Table存储的设计原则与最佳实践,包括分区策略、查询限制、实体组事务(EGTs)等关键概念。同时介绍了多种设计模式如同PartitionKey多RowKey模式、数据同步模式、索引模式等,帮助开发者更高效地利用Azure Table存储。
本文档提供了Azure Table存储的设计原则与最佳实践,包括分区策略、查询限制、实体组事务(EGTs)等关键概念。同时介绍了多种设计模式如同PartitionKey多RowKey模式、数据同步模式、索引模式等,帮助开发者更高效地利用Azure Table存储。
参阅的文章
l https://docs.microsoft.com/en-us/rest/api/storageservices/fileservices/designing-a-scalable-partitioning-strategy-for-azure-table-storage
l https://docs.microsoft.com/en-us/azure/storage/storage-table-design-guide
在设计之前你需要知道的
l 对Table Item进行排序时, 对于存储类型是String的字段,“2”大于“111”
l 对于Query中的查询条件,只支持“等于”,“不等于”,“大于”“大于等于”“小于”“小于等于”,相比于Sql来说,查询能力还是非常有限的
l 一个Partition Server 可以承载多个Partition,同一个Partition一定在同一个Server上
l 一个Partition 1秒可以处理500 Entity
l 可以考虑使用多个Partition以避免用同一个Partition导致Server的负载过大
l 一个EGT要小于100个Storage操作以及小于4M的内容
l 一条记录的大小要小于1M
l 一个EGT只记做一次操作的花费,并且可以保证操作的一致性,如果有一些操作不能完成,整个EGT会被回滚
l Unique Value的PartitionKey如果增序或降序排列的话被称为Range Partition,可以很好的提高性能
l PartitionKey和RowKey会被加上索引
l 一个搜索如果如果不指定PartitionKey,他就会搜索所有Partition,效率会很差
| 除了每一条记录大小要小于1M以外,每个Column的大小也有限制,例如类型为string的Column最大不能超过64K
Storage Table 设计模式
1. 同PartitionKey多RowKey模式
适用场景:需要对同一个Entity中的多个字段进行查询,比如分别就ID和邮箱来查询员工信息

2. 多PartitionKey,多RowKey模式
适用场景:需要对同一个Entity中的多个字段进行查询,和上面不同的是可以就多个Partition进行负载分流

3. 数据同步模式
适用场景:同一个Entity存在于不同的Partition,或者不同的Table,或者不同的数据源(比如Blob里, File System等等),他们之间的数据要保持同步的话,可以借助Storage Queue进行管理
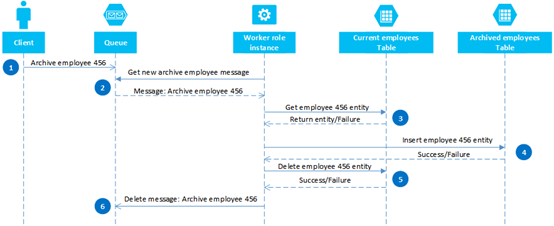
4. 索引模式
适用场景 :希望根据除PartitionKey和RowKey的其他属性进行查找,又不希望存储过多的重复数据,可以建立额外的Entity,专门映射这种关联关系。比如希望查找所有LastName相同的员工信息

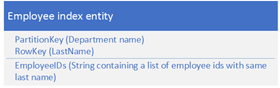
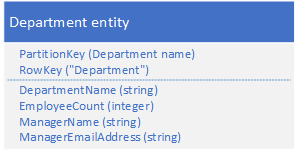
5. 合并数据模式
适用场景:区别于把所需要的数据分别存在两个entity,可以把相关数据融合成一个entity,以减少数据访问的次数,因为Storage Table支持多达256个字段
原先是这样

现在可以改成这样
6. 组合键模式
适用场合 :只需要一个Query去获得相关的数据
以前是这样 :
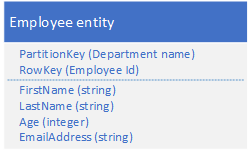

现在是这样:

7. 大规模删除模式
适用场景 :需要根据时间对历史数据进行删除
如何设计 :把时间信息作为Table Name,比如YYYYMMTable,如果要删除历史数据,可以直接删除对应的Table即可
8. 数据序列模式
适用场景:对按有限规则生成的RowKey,可以改变属性的设计,使其可以只使用一个Query获得所需数据
以前是这样:如果要统计一天的消息量,要Query 12次
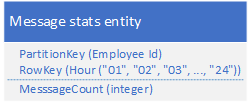
改成这样,只需要Query 1 次
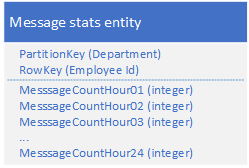
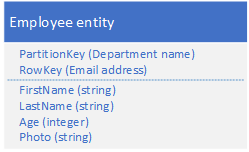
9. 大型Entity模式
适用场景:因为一条Table中的记录的限额是1M,对于比较大的字段,应该把相应内容存储在Blob中,Table中只存储Blob对应记录的地址
10. 分流模式
适用场景 :因为一个Partition的处理能力是每秒500个Entity,所以我们可以对Partition进行适当的切分,缓解访问压力

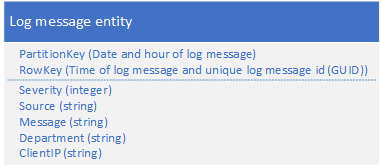
11. 日志存储模式
适用场景 :首先通过PartitionKey进行粗粒度时间分流,缓解存取压力,继而以查询条件开头来设计RowKey,有助于后续查询

















 492
492

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









