



1. Replication: 因为每个HDFS被部署在是低成本的商业硬件上(low cost commodity hardware),所以为了有更佳的Fault Tolerance,HDFS将每个Block备份存储。默认的Replication Factor=3.
Note: The NameNode collects block report from DataNode periodically to maintain the replication factor. Therefore, whenever a block is over-replicated or under-replicated the NameNode deletes or add replicas as needed.

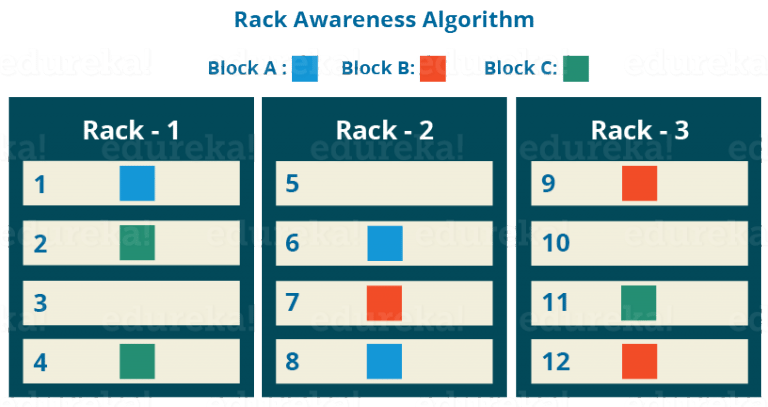
2. Rack Awareness:Namenode会根据Rack Awareness算法来确保一个Block的3个Replica不在一个Rack上。
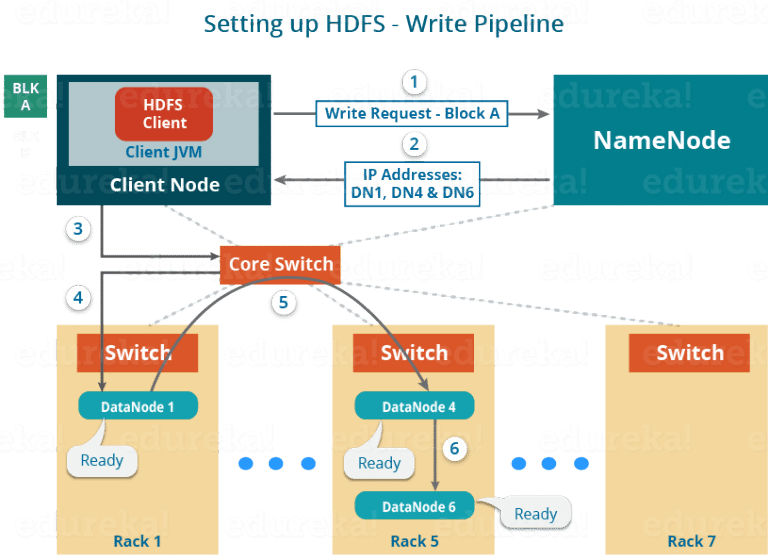
3. HDFS Write:
a. 建立pipline
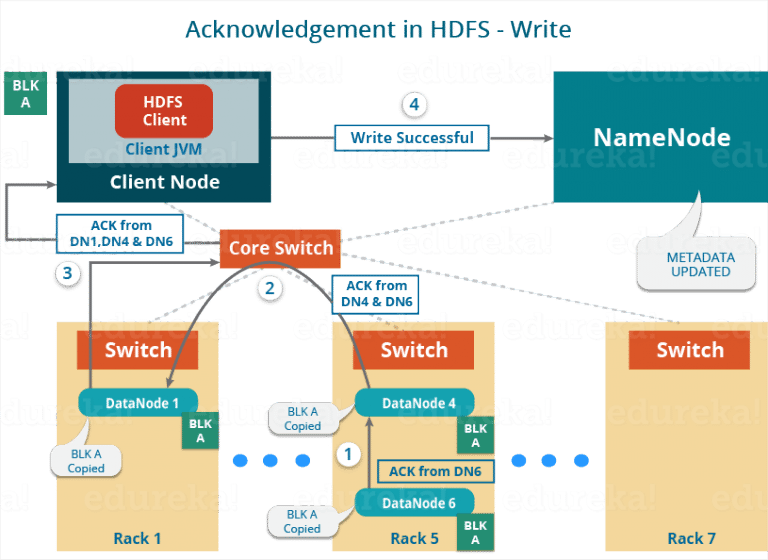
2. Streaming Data

3.Shutdown and Acknoledgement:
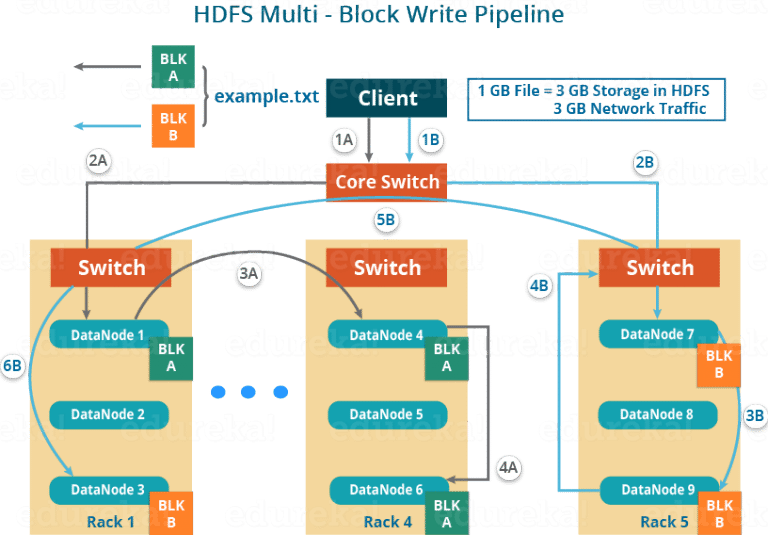
多Blocks的并行操作:
For Block A: 1A -> 2A -> 3A -> 4A
For Block B: 1B -> 2B -> 3B -> 4B -> 5B -> 6B
HDFS Read:
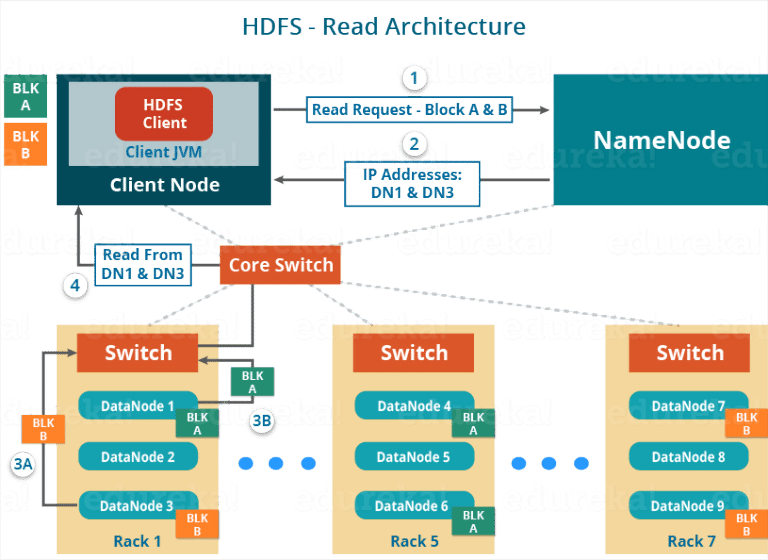
https://www.edureka.co/blog/apache-hadoop-hdfs-architecture/#datanode
https://www.coursera.org/learn/big-data-essentials/lecture/JmzZr/block-and-replica-states-recovery-process-1

















 2321
2321

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









