






 本文深入探讨了高性能MySQL中的三星索引概念,详细解释了一星、二星和三星索引的含义,并通过SQL量化方法对不同索引配置进行了评估。
本文深入探讨了高性能MySQL中的三星索引概念,详细解释了一星、二星和三星索引的含义,并通过SQL量化方法对不同索引配置进行了评估。
高性能MySQL中的三星索引
我对此提出了深深的疑问:
一星:相关的记录指的是什么??(相关这个词很深奥,“相关部门”是什么部门)
二星:如果建立了B-Tree(B+Tree)索引,数据就有序了。
三星:索引的列包含了查询需要所有的列?根本不需要在where查询条件所有的列上建立索引!
我认为一星和二星的rows应该是columns,索引不关具体的数据行,只与查询的列有关。这样也与High Performance MySQL 后面提到的多列索引的观点相符合,特别是二星评估。
个人的观点:
评估一个索引是否适合某个查询的“三星系统”(three-start system):
一星:索引将相关的列放到一起,即在一系必要的列上建立索引,不必为在where条件里面的列都建立索引。
二星:索引中的数据列顺序和查找中排列顺序一致。通常将选择性最高的列放到索引的最前列。
三星:索引中的列包含了查询中需要的全部列。索引包含查询所需要的数据列,不再进行全表查表(聚簇索引、覆盖索引)。
参考资料:
《高性能MySQL》中文第三版
《High Performance MySQL (3rd Edition)》英文第三版
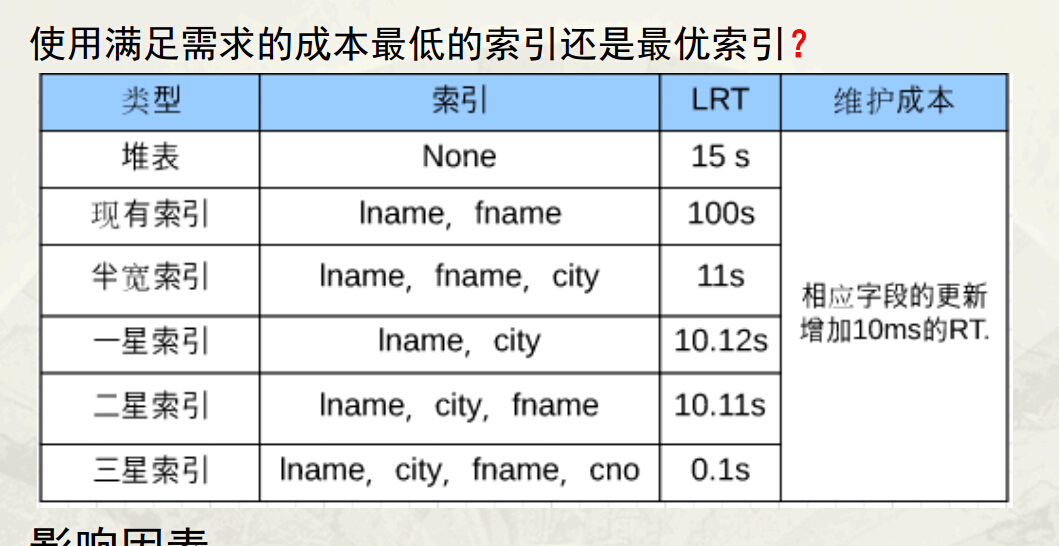
SQL量化方法
u CASE 3:三星索引(lname,city,fname,cno)
RT = 1 * 10ms + 1000*0.1ms = 0.1 s
一次随机读取,1000次行扫描
u CASE 4:二星索引(lname,city,fname)
RT = 1 * 10ms + 1000 * 0.1ms + 1000 * 10ms= 10.11s
一次随机读取,1000行扫描,1000次随机IO
u CASE 5:一星索引(lname,city)
RT= 1 * 10ms + 1000 * 0.1ms + 1000 * 10ms + 1000 * 0.01ms=10.12s
一次随机读取,1000行扫描,1000次随机IO,1000行排序


















 513
513

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









