




 本文介绍了如何利用R语言中的Calinski-Harabasz准则来确定聚类的最佳K值。该准则通过比较组间平方和误差(SSB)与组内平方和误差(SSw)来评估聚类效果,理想的聚类应有较小的SSw和较大的SSB,从而获得较高的Calinsky criterion值。文章详细阐述了实现步骤,包括数据读取、计算最佳K值以及结果可视化。
本文介绍了如何利用R语言中的Calinski-Harabasz准则来确定聚类的最佳K值。该准则通过比较组间平方和误差(SSB)与组内平方和误差(SSw)来评估聚类效果,理想的聚类应有较小的SSw和较大的SSB,从而获得较高的Calinsky criterion值。文章详细阐述了实现步骤,包括数据读取、计算最佳K值以及结果可视化。
Calinski-Harabasz准则有时称为方差比准则 (VRC),它可以用来确定聚类的最佳K值。Calinski Harabasz 指数定义为:
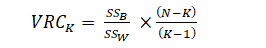
其中,K是聚类数,N是样本数,SSB是组与组之间的平方和误差,SSw是组内平方和误差。因此,如果SSw越小、SSB越大,那么聚类效果就会越好,即Calinsky criterion值越大,聚类效果越好。
1.下载permute、lattice、vegan包
install.packages(c("permute","lattice","vegan"))
2.引入permute、lattice、vegan包
library(permute)
library(lattice)
library(vegan)
3.读取数据
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









