






 本文探讨了自然语言处理(NLP)的基本概念,包括词意消歧、指代理解、自动生成语言等核心研究内容。通过实例演示了Python环境下文本的读取、分词与分析过程,涵盖了英文与中文分词方法,如NLTK和jieba分词库的使用。
本文探讨了自然语言处理(NLP)的基本概念,包括词意消歧、指代理解、自动生成语言等核心研究内容。通过实例演示了Python环境下文本的读取、分词与分析过程,涵盖了英文与中文分词方法,如NLTK和jieba分词库的使用。

NLP
-
自然语言:指一种随着社会发展而自然演化的语言,即人们日常交流所使用的语言;
-
自然语言处理:通过技术手段,使用计算机对自然语言进行各种操作的一个学科;
NLP研究的内容
- 词意消歧;
- 指代理解;
- 自动生成语言;
- 机器翻译;
- 人机对话系统;
- 文本含义识别;
NLP处理
- 语料读入
- 网络
- 本地
- 分词

#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2018-9-28 22:21
# @Author : Manu
# @Site :
# @File : python_base.py
# @Software: PyCharm
import urllib
from nltk import word_tokenize
from bs4 import BeautifulSoup
# 在线文档下载
url = 'http://www.gutenberg.org/files/2554/2554-0.txt'
res = urllib.request.urlopen(url)
raw = res.read().decode('utf8')
print('length', len(raw))
print('type', type(raw))
print(raw[:100])
# 分词
tokens = word_tokenize(raw)
print(tokens[:50])
print('length:' + str(len(tokens)))
print('type:', type(tokens))
# 创建文本
text = nltk.Text(tokens)
print('type', type(text))
print('length', len(text))
print(text)
- 基于此单位的文本分析
- 正则表达式

- 正则表达式
- 分割
- 断句
- 分词
- 规范化输出
中文分词及相应算法
- 基于字典、词库匹配;
- 正向最大匹配;
- 逆向最大匹配;
- 双向最大匹配;
- 设立切分表执法;
- 最佳匹配;
- 基于词频度统计;
- N-gram模型;
- 隐马尔科夫模型;
- 基于字标注的中文分词方法;
- 基于知识理解;
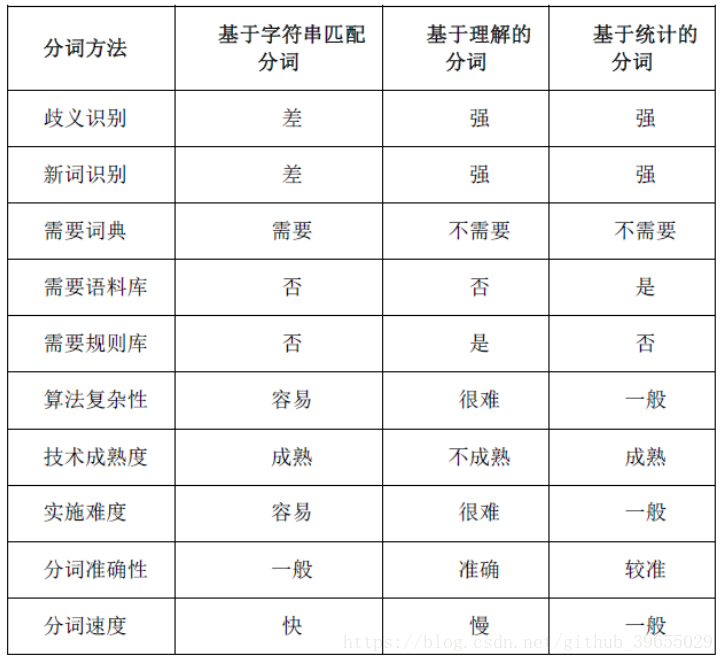
分词方法比较
结巴分词
- 安装 在控制台使用
pip install jieba即可安装;
- 功能
- 分词;
jieba.cut、jieba.cut_for_search;
- 添加自定义词典;
jieba.load_userdict(file_name)、add_word(word, freq=None, tag=None)、jieba.del_word(word)、jieba.suggest_freq(segmen, tune=True);
- 关键词提取;
jieba.analyse.extract_tags(sentence, topK=20, withWeight=False, allowPOS=());jieba.analyse.set_idf_path(file_name);jieba.analuse.set_stop_words(file_name);
- 词性标注;
jieba.tokenize();jieba.posseg.cut();
- 并行分词;
- 词汇搜索;
- 分词;


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









