






定义:
窗口函数 microsoft官方文档里面的解释为:
确定在应用关联的开窗函数之前,行集的分区和排序
窗口是用户指定的一组行。开窗函数计算从窗口派生的结果集中各行的值。可以在单个查询中将多个排名或聚合开窗函数与单个 FROM 子句一起使用。但是,每个函数的 OVER 子句在分区和排序上可能不同。OVER 子句不能与 CHECKSUM 聚合函数结合使用
开始看的时候我不是很理解,自己测试完以后勉强能够看懂吧。写的不对的地方请大家指正。窗口函数和聚合函数的功能类似,都可以对某一列的值进行计算。但不同的是聚合函数必须配合 group by 使用,来显示分组之后组集和组集的聚合值,而窗口函数不需要 分组 就可以显示所有结果集和某些组集的聚合值
例如:我们查询学生姓名,平均成绩的话 直接用AVG(成绩) 然后根据姓名分组就可以了,如果我们希望再加一列课程名和每门课程所有同学的平均分呢,是不是一句话就搞不定了。这时候窗口函数就派上用长了。
窗口函数分类:
SQL Server 提供排名开窗函数和聚合开窗函数
1、聚合开窗函数 :聚合开窗函数不能与order by 一起使用
2、排名开窗函数
(1)、聚合开窗函数: 配合聚合函数来使用
例:
测试表没有遵循范式:
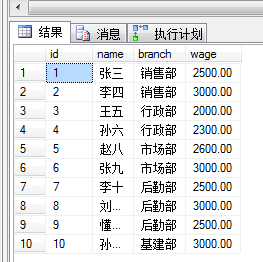
if exists (select 1 from tempdb.dbo.sysobjects where name='##test') drop table ##test --创建测试表 create table ##test ( id int identity(1,1), name varchar(8) , branch varchar(10) , wage numeric(9,2) ) --插入十条数据 insert into ##test values ('张三','销售部',2500) insert into ##test values ('李四','销售部',3000) insert into ##test values ('王五','行政部',2000) insert into ##test values ('孙六','行政部',2300) insert into ##test values ('赵八','市场部',2600) insert into ##test values ('张九','市场部',3000) insert into ##test values ('李十','后勤部',2500) insert into ##test values ('刘十一','后勤部',3000) insert into ##test values ('懂十二','后勤部',2500) insert into ##test values ('孙十三','基建部',3000) select * from ##test
1、我们现在想要查询 员工的姓名,所在部门,工资,所在部门的平均工资
select name,branch,wage,AVG(wage) over (partition by branch)as 部门平均工资 from ##test
我理解的他的逻辑语意是这样的,根据 branch列来分区 计算每个分区的平均工资,partition by 可以指定根据多列来分区,也可以不带partition by 不写的话整张表就是一个区
结果: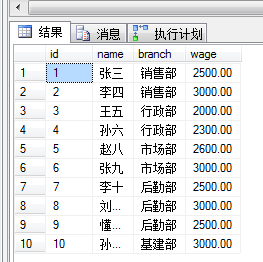
跟其他聚合函数配合的结果:


select name,branch,wage,AVG(wage) over (partition by branch)as 部门平均工资 ,COUNT(branch) over (partition by branch) as 部门人数 ,SUM(wage) over (partition by branch)as 部门工资总数 from ##test go
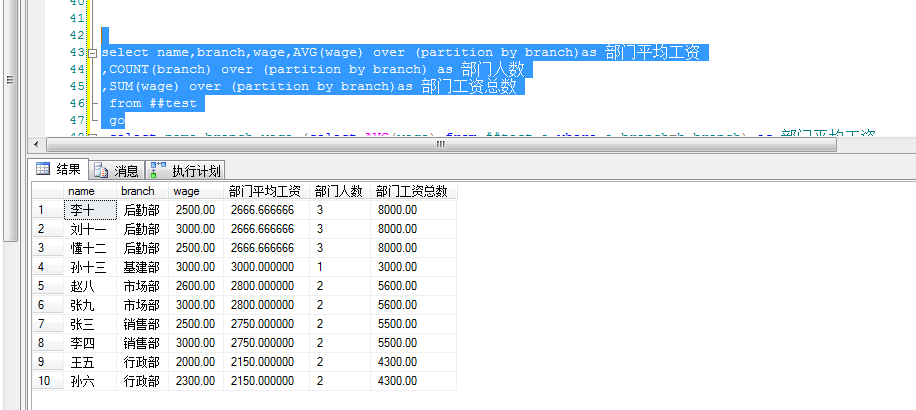
如果不用窗口函数也可以实现但是 查询性能不如运用窗口函数。
select name,branch,wage,(select AVG(wage) from ##test a where a.branch=b.branch) as 部门平均工资 ,(select COUNT(name) from ##test c where c.branch=b.branch ) as 部门人数 ,(select SUM(wage) from ##test d where d.branch=b.branch) as 部门工资总数 from ##test b
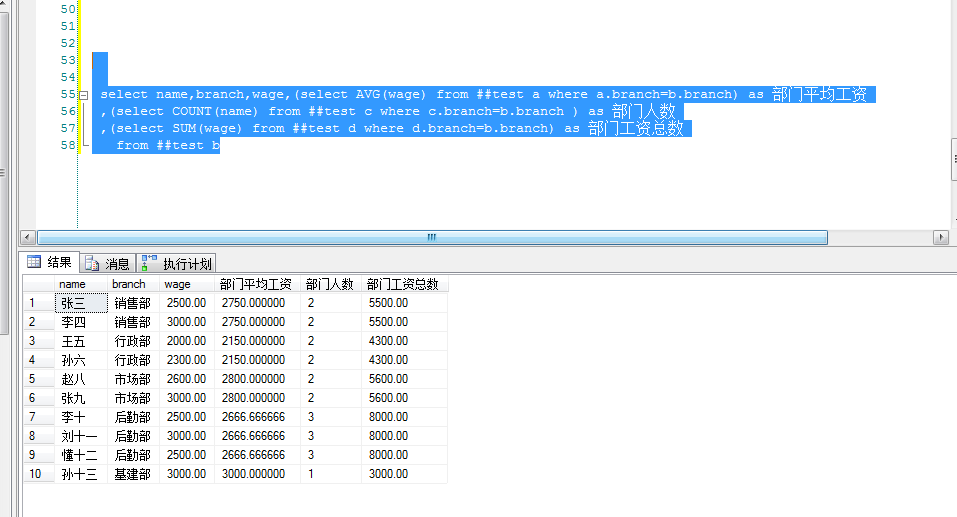
理解的不是太深刻,也请各位砖家表笑我,多多拍砖
.......排名函数 :
sql server 2008 提供了4个排名函数
1、row_number()
2、rank()
3、dense_rank()
4、ntile()
row_number()
row_number()函数语法为:
ROW_NUMBER ( ) OVER ( [ <partition_by_clause> ] <order_by_clause> )
作用是对来自from 的结果集中根据某一列或者多列的值进行排序然后对结果集加编号,编号从整数1开始,如不指定partition 分区那么将对所有结果集当成一个区进行排序编号,如果指定分区,那么将结果按照partition by 的字段分为一个或者多个区,每一个被当成一个集合,对每一个集合分别排序编号。
row_number 函数常用于分页查询中。在2008之前分页查询是用 top和反top的方法,2008增加row函数之后分页查询变得简单了许多
例:
现有结果集:
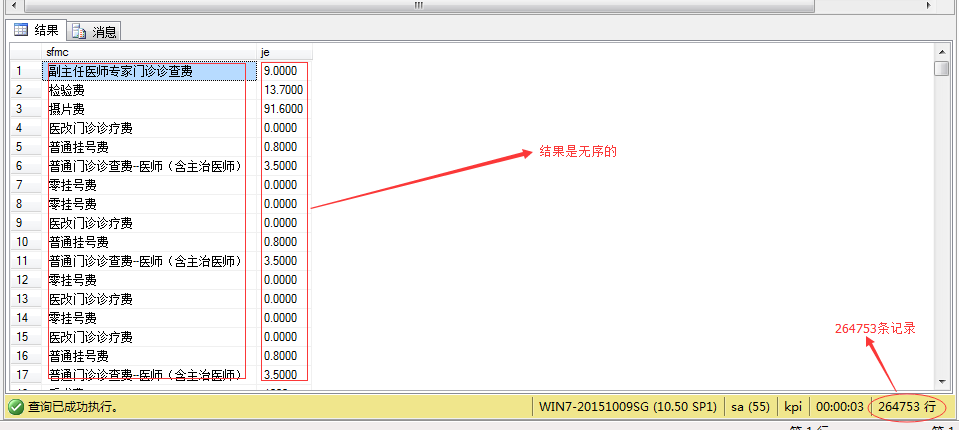
图(1)
用row_number () 来对结果集编号:
select ROW_NUMBER() over (order by je asc )as bh,SFMC,JE from JK_MZMX
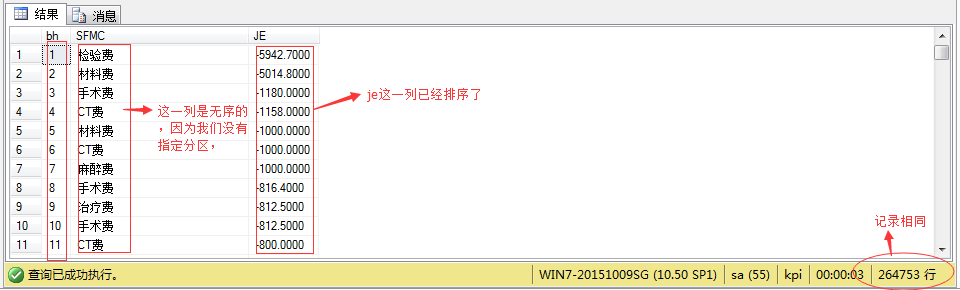
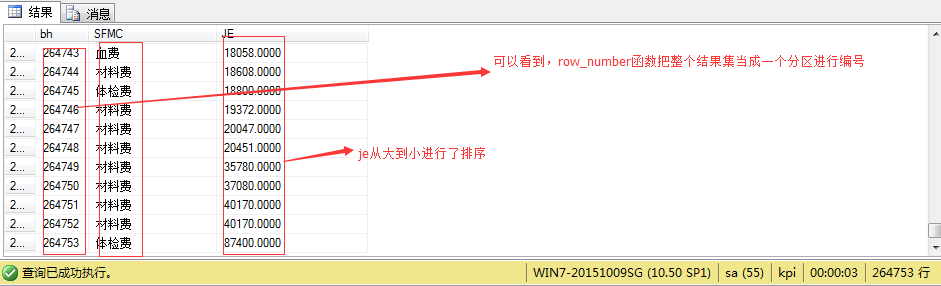
图(2)
我们再根据sfmc列把结果集分区后编号:
select ROW_NUMBER() over (partition by sfmc order by je asc )as bh,SFMC,JE from JK_MZMX
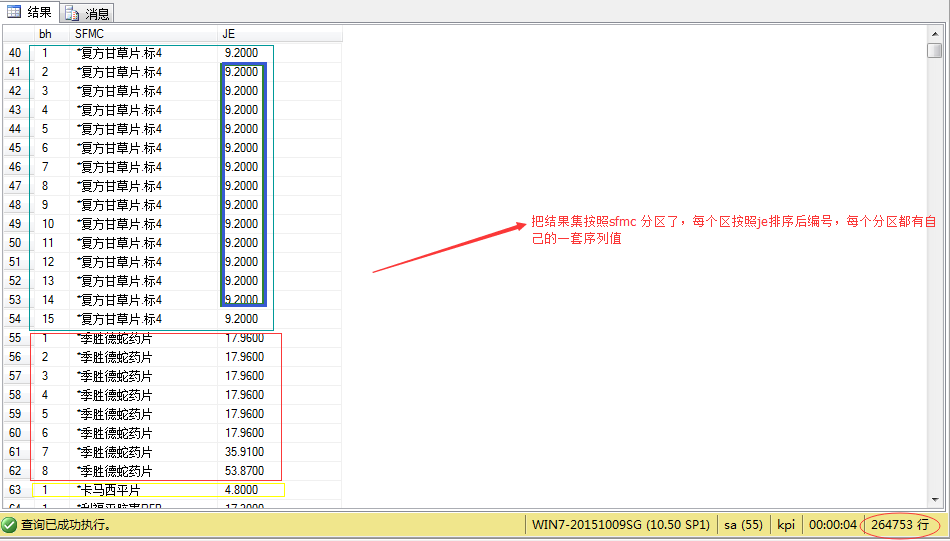
图(3)
注意上图我标蓝的地方,je字段的值是相同的,但是编号不同,假如我们要把一次考试的成绩来进行排名,如果同学A和B都考了100分那么肯定是并列第一,那这时候需要用到dense_rank()函数了
rank() 和dense_rank()函数
这两个函数和row_number()函数的功能类似都是对结果集按照排序列进行编号但是不同的是:RANK 和 DENSE_RANK 向在排序列中具有相同值的行分配相同的排序
还是图三的写法,把row_number()分别换成rank()和dense_rank()函数来试验一下
select rank() over (partition by sfmc order by je asc )as bh,SFMC,JE from JK_MZMX
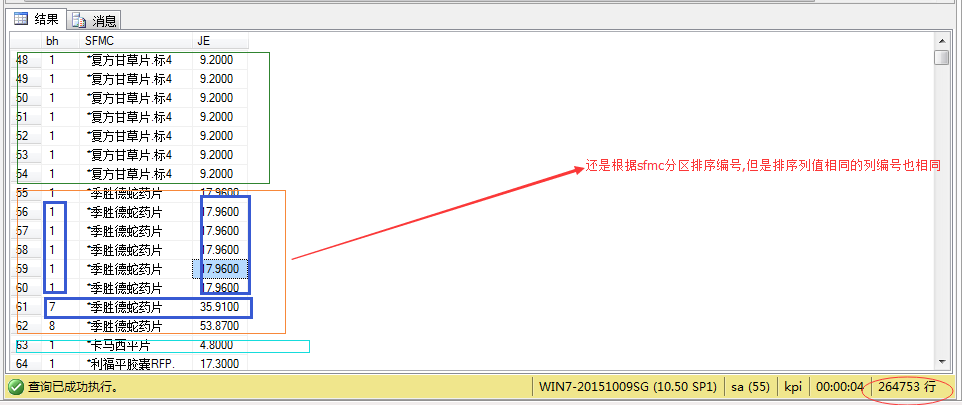
rank()函数把排序列相同的记录编号也给予相同的编号,可是排序列的值晋升一阶后编号怎么变成7了,因为rank()函数是返回结果集分区内每行的排名,行的排名是相关行之前排名数加1,所以7表示的是第七行。看来rank()函数还是不能满足上边说的对成绩排名的需求
试试dense_rank()
select dense_rank() over (partition by sfmc order by je asc )as bh,SFMC,JE from JK_MZMX
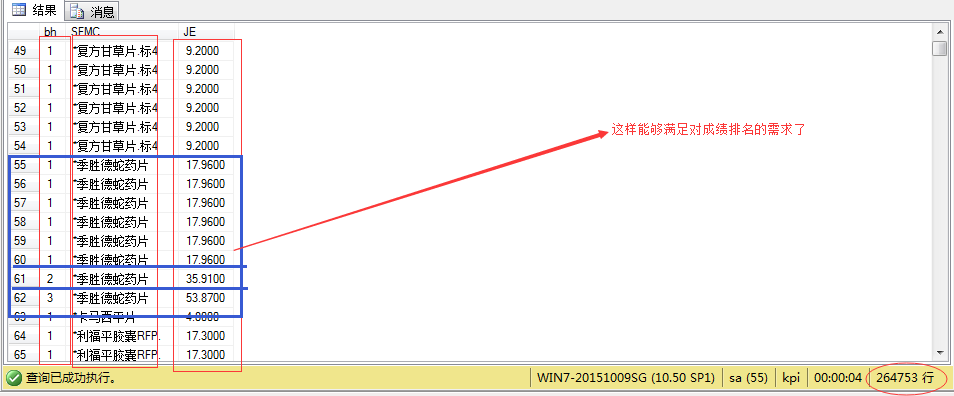
因为dense_rank()函数是返回结果集中分区的排名,但是排名不间断,行排名是上一个排名数+1而不是上一行数+1.
NTILE()

















 1699
1699

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









