






 本文分享了一种基于Densenet和双Lstm的OCR检测方案,通过Warp-CTC进行去重定向,实现了快速且高精度的字符识别。作者在Linux环境下进行了英文自然场景的识别实验,并计划结合MobileNet-SSD进行场景检测。
本文分享了一种基于Densenet和双Lstm的OCR检测方案,通过Warp-CTC进行去重定向,实现了快速且高精度的字符识别。作者在Linux环境下进行了英文自然场景的识别实验,并计划结合MobileNet-SSD进行场景检测。
https://github.com/senlinuc/caffe_ocr源代码在此,是基于senlnuc的模型进行学习的。
好长时间没更新学习博客了,之前一直在忙着做基网络模型的评测,以及tesseract 和其他Ocr的研究等。
更新一下最近学习的OCR检测,要求是速度要快,准确度要相对较高!
整个操作流程:
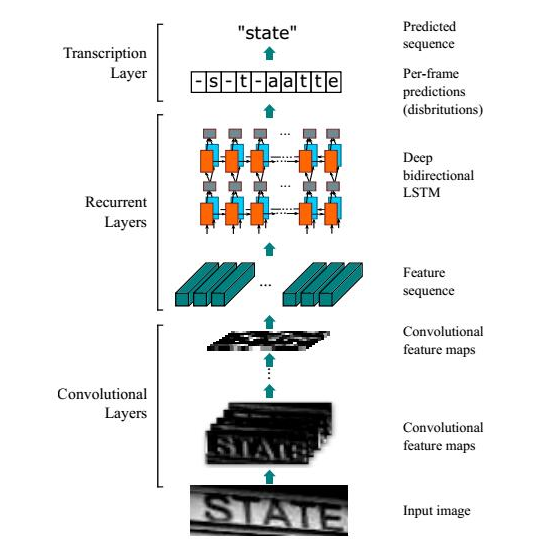
先用卷积进行特征提取,这里我用的是Densenet的模型,然后用双Lstm进行不定长处理,然后接上warp-ctc进行去重定向。
作者中文字符识别的准确率如下表:
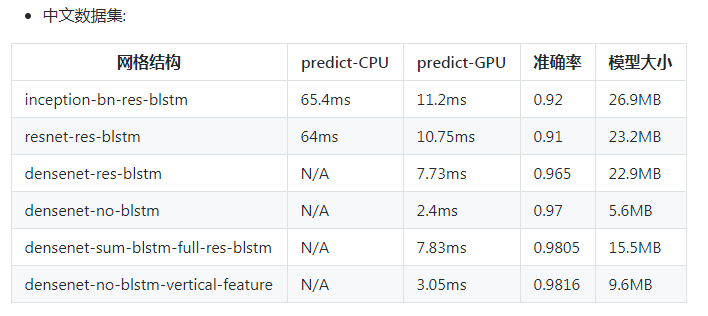
我是基于linux进行的英文自然场景英文识别,目前还在识别的训练阶段,接下来会加上自然场景的检测,暂定用mobileNet-ssd。训好后会放出评测


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









