






 本文深入探讨了指针的概念及其在编程语言中的作用,特别是C#中指针的使用细节,包括内存地址操作、类型安全及与托管和非托管指针的区别。
本文深入探讨了指针的概念及其在编程语言中的作用,特别是C#中指针的使用细节,包括内存地址操作、类型安全及与托管和非托管指针的区别。
Pointers are the heart and soul of a programming language. The only reason why the C
programming language is so popular amongst programmers is because of its concept of
pointers. Even C#, grudgingly, supports the concept of pointers. A pointer value is an
address that represents a memory location.
In IL, numbers can be of two types:
• normal numbers, that we are so familiar with.
• numbers that represent a location in memory.
A pointer represents the second type where the number represents a memory location.
Memory locations contain data of specific types. A pointer also needs to be typed, so that it
can point to memory locations that contain data of the same type. This is required to
guarantee type safety.
IL defines a location signature for pointers that contain the data type and, a special syntax
to identify it as a pointer. A pointer type value is not an object.
The & symbol signifies a managed pointer whereas, the * symbol signifies an unmanaged
pointer. The managed world does not like pointers. Then there are transient pointers which
we will introduce later.

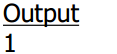
Like C, the programming language C# also understands a pointer to mean a variable that
contains a special number, one representing a computer memory location. Thus, pointers
are no different from other variables. Any number can be stored in them.
In the above example, we have placed the value 1 on the stack and used ldloc.0 to store
this value in a pointer variable. A pointer variable is no different from a non-pointer
variable.

IL does not understand pointers. Therefore, IL does the following:
• places the value of the pointer v on the stack
• places 1 on the stack
• calls the add instruction.
The add instruction does not sense the pointer on the stack and simply increases its value
by 1


As explained earlier, C# increases the value of a pointer variable by 4 if it is a pointer to an
int. An int requires 4 bytes of memory.
Let us now understand some basics of pointers. The value of a pointer variable is a
memory location and it is, in turn, stored in memory too.

We have loaded the address of the variable j on the stack and stored it in the variable v.
Thus, the variable v now contains the address of the variable j in memory. From the
output, we can infer that, variable j in memory, begins at the memory location 6552340.

In the above program, we have stored the address of the int32 j in the pointer variable v.
We have then, loaded the value of v or the address of variable j, on the stack and
thereafter, called the instruction stobj. This instruction takes a data type as a parameter
and initializes the memory location placed earlier on the stack, with the value that is on
top of the stack.
Thus, even though the instruction stloc v is not used anywhere, we have been able to place
a value in the memory location occupied by j. The instruction, ldloc and stloc read from
and write to a memory location respectively.
We can thus see that, the value of any variable, whether it is a local or a parameter or a
field, is simply the value that is stored in the specific memory location.


This program is almost identical to the earlier one, and yet, the output is vastly different.
The reason is that, we have changed the parameter that was passed to the instruction
stobj from int32 to int8.
Let us explain the repercussions of this change.

The variable j is initialised with a value 66051. Following it, the address of this variable is
placed on the stack and the instruction ldobj is called with a parameter int32. This
instruction picks up an address from the stack and returns the value that is contained in
the first 4 memory locations starting at the retrieved address.
It takes up 4 bytes as we have specified the parameter as int32. When we modify the same
parameter to int8 or 1 byte, we get a different answer. We are using the instruction ldobj to
identify as to what is stored in a specific memory location.
Here, we have used a short i.e. int16 that requires 2 bytes, to store the value of the
variable j. We have placed its address on the stack and called ldobj with an int16 to get its
actual value, i.e. 515.
Thereafter, we have again placed its address on the stack and called ldobj with int8. This
generates an answer of 3. This means that the number 3 is stored in the first memory
location occupied by the variable j. We will explain the reason for this shortly.
We again place the address of the variable j on the stack and add 1 to it. the address gets
incremented by 1 and ldobj is called once again with int8. This time, the answer generated
is the number 2. Thus, the second memory location occupied by the variable j contains 2.
Though we are aware that the value of the variable j is 515, how is it that the memory it
occupies contains the numbers 3 and 2 ?. Why is the number 515 stored as the numbers 3
and 2
The answer is very simple. Computer memory can only store values ranging from 0 to 255 i.
e. a range of 256 different values. Thus, a value that lies in the range of 0 to 255 can be
stored in one memory location. But the number 515 is larger than 255.
In this case, the assembler first divides the number 515 by 256, because the result of this
division cannot be larger than 255. It stores the remainder of the division, i.e. the number
3, in the first memory location. Further, the result of the division, i.e. the number 2 is
stored in the second memory location.
Thus, the number 515 gets stored as the numbers 3 and 2 in memory. When we want to
access the value of j, the assembler multiplies the number in the first location by 1 and the
number in the second location by 256. Thus 1*3 + 256*2 gives us back the original
number 515.
Doesn’t the above explanation give you a warm feeling in the heart and make you feel
more comfortable while dealing with computers. At least, it had that effect on us !

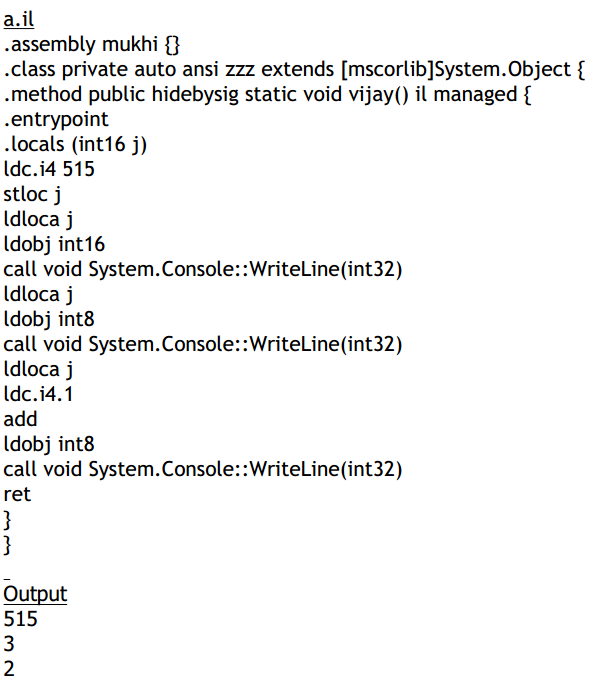
The above program is similar to its predecessor, albeit with some minor modifications.
We want to unravel as to how an int32 is stored in memory. We initialize the variable j to
66051. Then, we display the values at the 4 memory locations occupied by j. The only
small change we make here is that, we increase the memory location for ldobj by 1 the first
time, and then by 2 and then by 3, because we want to read different memory locations
each time.
We have to change the values in the add as we cannot change the address at which the
variable starts. Whenever a variable is stored over four memory locations, the mathematics
becomes tedious. Over four memory locations, we can store numbers in a range of 4 billion
or 2 raised to the power of 32.
The numbers to be stored in the 4 memory locations are arrived as follows:
• First, the assembler divides the number 66051 by 2 raised to the power 24. The
answer is 0 and the remainder is 66051.
• This remainder of 66051 is then divided by 2 raised to the power 16 or 65536. The
answer is 1 and the remainder is 515.
• This remainder of 515 is then divided by 2 raised to the power 8 or 256, as explained
in the example above. The answer is 2 and the remainder is 3
The 4 answers i.e. 0, 1, 2 and 3 are finally stored in the 4 memory locations occupied by j.

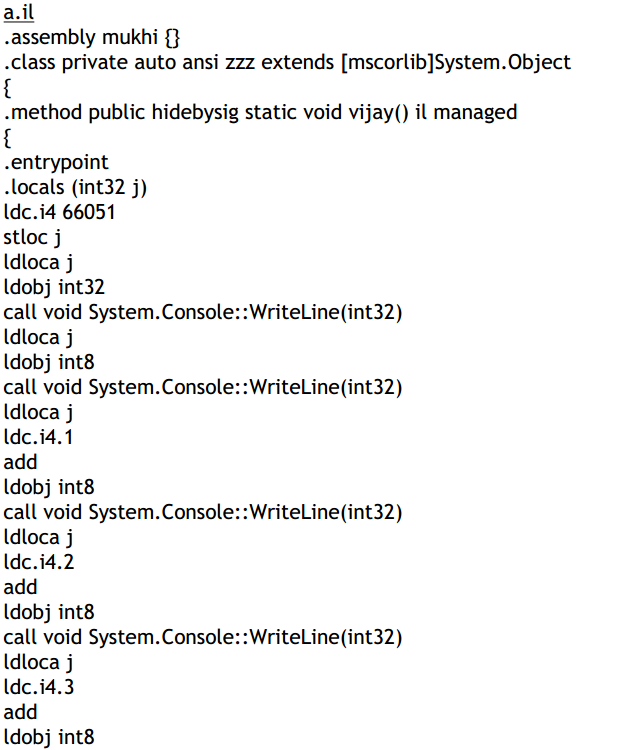
This example simply builds upon the preceding example. A variable on the stack has a
random value and j is initialised to 0. Then, we store the address of j in the variable v.
Next, we place this address and the number 3 on the stack.
Thereafter, we use stobj with int8 to place this number 3 at the first memory location
occupied by j. When we display the value of j, the assembler does the following:
• It multiplies the number at the first memory location by 1 (2 raised to the power 0)
• It multiplies the number at the second memory location by 256 (2 raised to the power
8)
• It multiplies the number at the third memory location by 65536 (2 raised to the
power 16)
• It multiplies the number at the fourth memory location by 2 raised to the power 24.
The output of the above program is generated as follows:
• Since the first memory location of j has a value 3, the value of j becomes 3.
• Then, we encounter the value 2 in the second memory location of j. Thus, its value
now becomes 515.
• Then we find the value 1 in the third memory location occupied by j, changing its
value to 66051 because of the following calculation:
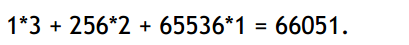
This is the reverse of the earlier program. Instead of placing 66051 on the stack, we are
individually places values on the stack to build the number.

It is unfortunate that IL does not understand pointers the way C# or any other
programming language does.
Here, v is a pointer to a pointer to a pointer to an int32. Ultimately it is treated as a pointer
to an int32, and everything works as shown. We have stored the address of j in it and used
ldobj and stobj to access the memory.
We have gone a step further and removed all the asterix symbols from the locals directive
and made v a simple int32. We see no errors because a pointer and an int32 take up the
same amount of memory. Thus, the parameters to ldobj and stobj are most crucial.

Pointer are not interpreted as memory locations to a particular data type, but as numbers.
Thus, subtracting them will give us the amount of memory separating the pointers.
In the program above, as the two ints are separated by 4 bytes, the result of the
subtraction is 4. The pointers we have used are called unmanaged pointers. They never
reference any memory which is being monitored by the garbage collector. The garbage
collector is oblivious to the existence of these pointers. Garbage collectors like to move
things around in memory, at their beck and call. This has led to the concept of pinning.
Pointers cannot use verifiable code.
There are 5 different load instructions in IL. They are for the following:
• a field
• a static field
• a local
• a parameter
• an array
If we add the letter 'a' at the end of these load instructions, we will get the address of the
variable instead of its value.

The ldstr instruction stores the string in memory and places its memory location on the
stack. Here, we are merely displaying this value.
This value that we are displaying is very different from earlier values as the values earlier
were on the stack, whereas the string is stored on the heap.
We have called ldstr but now stored the value in the variable v. Then, we have placed the
value of v on the stack and called the WriteLine function with a string as a parameter.
We can't place strings or objects on the stack. We can only place numbers on the stack.
Also, we can place the reference of an object on the stack. This reference is a number that
indicates the starting location of the object in memory. Using ldobj, we can access the
value that is stored in memory allocated for the object.



All locals are created on the stack. The rest are on the heap. The stack only contains
numbers. On a 32 bit machine, as in this case, they are in multiples of 4.
The stack is also used to transfer parameters to a function. In this case, parameters are
pushed onto the stack and the functions are called. When the function encounters a ret,
the stack is restored to the state prior to the function call
Thereafter, when another function is called, the same stack, i.e. the same memory that was
used earlier to transfer parameters for the previous function, is used again for the new
function also.
This is how memory is conserved. Once a function finishes execution, the memory
allocated to the locals is used by another function. Thus, locals lose their values once a
function quits out.
You may have noticed that there is a 16 byte gap between the two parameters. There is no
information available as to what is stored in these 16 bytes.
![]()
Nothing stops you from shooting yourself in the foot. The reason why the powers to be do
not like you using pointers is that, they are very powerful but, at the same time, they are
extremely dangerous.
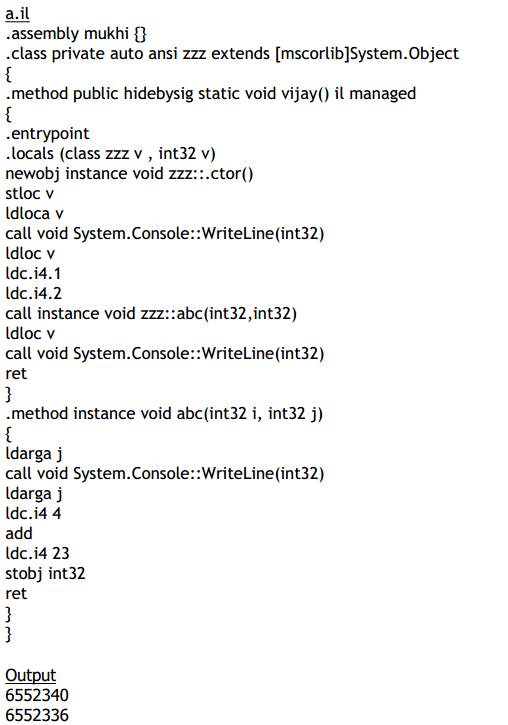
Here, we are displaying the address of the local v and also the parameter j. We realized that
they differ by 4 memory locations only. Thus, we added 4 to the address of j and wrote 23
to the memory locations that signify the address of the local v in the function vijay.
Thus, when we displayed the value of v in the function vijay, the number 23 was displayed.
Thus, from one function, we have been able to change the value of a variable present in an
another function.
This feature can create havoc if the pointers are not used carefully. Let us assume that
there is some bug in the WriteLine function and it writes some random value somewhere in
memory. If that random memory location contained any crucial data or variables, the
program can crash and there is no way that you can find out as to where the error has
occurred.


We can overwrite any piece of memory we like. In the function abc, we have accessed the
address of the parameter i, and stored the value 23 in that address. When we subsequently
tried to display its value, ldarg.1, for a moment also, did not consider the old value to be 1.
All that it did was read the memory location and display the value stored there.

The above example simply prints out the addresses of a static field and an instance field.
They are both stored on the heap but at different locations in the heap memory.
Here is a summary of all that we have learnt about unmanaged pointers:
• The concept of pointers has been borrowed from languages like C and C++.
• There are no restrictions on their use, and thus, code that uses them cannot be
verified at all.
• They are internally recognized as unsigned integers by the Execution Engine (EE).
• The * symbol and a data type should be used with pointers.
• The run time does not report the existence of unmanaged pointers to the garbage
collector. Hence no garbage collector can handle these unmanaged pointers.


Now let us understand the managed pointer. This is the second type of pointer and begins
with a & symbol. This type of pointer may point to a field of an object type or to a value
type or any other type. It cannot however, be NULL.
The most important thing about this type of pointer is that, it must be reported to the
garbage collector, in spite of the fact that, it points to managed memory. This type of
pointer works in the good managed world.
The last type of pointer is the transient pointer. It lies in between managed and
unmanaged pointer. We cannot create pointers of this type. They are created by the EE,
with the help of some IL instructions and depending upon the destination, the EE makes
them either managed or unmanaged pointers.

















 1031
1031

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









