






 本文探讨了SparkSQL中CatalystOptimizer作为核心组件的作用,它负责将SQL语句转换为物理执行计划,直接影响SQL执行效率。文章还对比了ApacheCalcite与orca两种查询优化器,并介绍了关系代数作为查询优化的理论基础。
本文探讨了SparkSQL中CatalystOptimizer作为核心组件的作用,它负责将SQL语句转换为物理执行计划,直接影响SQL执行效率。文章还对比了ApacheCalcite与orca两种查询优化器,并介绍了关系代数作为查询优化的理论基础。

Catalyst Optimizer是SparkSQL的核心组件(查询优化器),它负责将SQL语句转换成物理执行计划,Catalyst的优劣决定了SQL执行的性能。
查询优化器是一个SQL引擎的核心,开源常用的有Apache Calcite(很多开源组件都通过引入Calcite来实现查询优化,如Hive/Phoenix/Drill等),另外一个是orca(HAWQ/GreenPlum中使用)。
关系代数是查询优化器的理论基础。常见的查询优化技术:查询重用(ReuseSubquery/ReuseExchange等)/RBO/CBO等。
SparkSQL执行流程
SparkSQL中对一条SQL语句的处理过程如上图所示: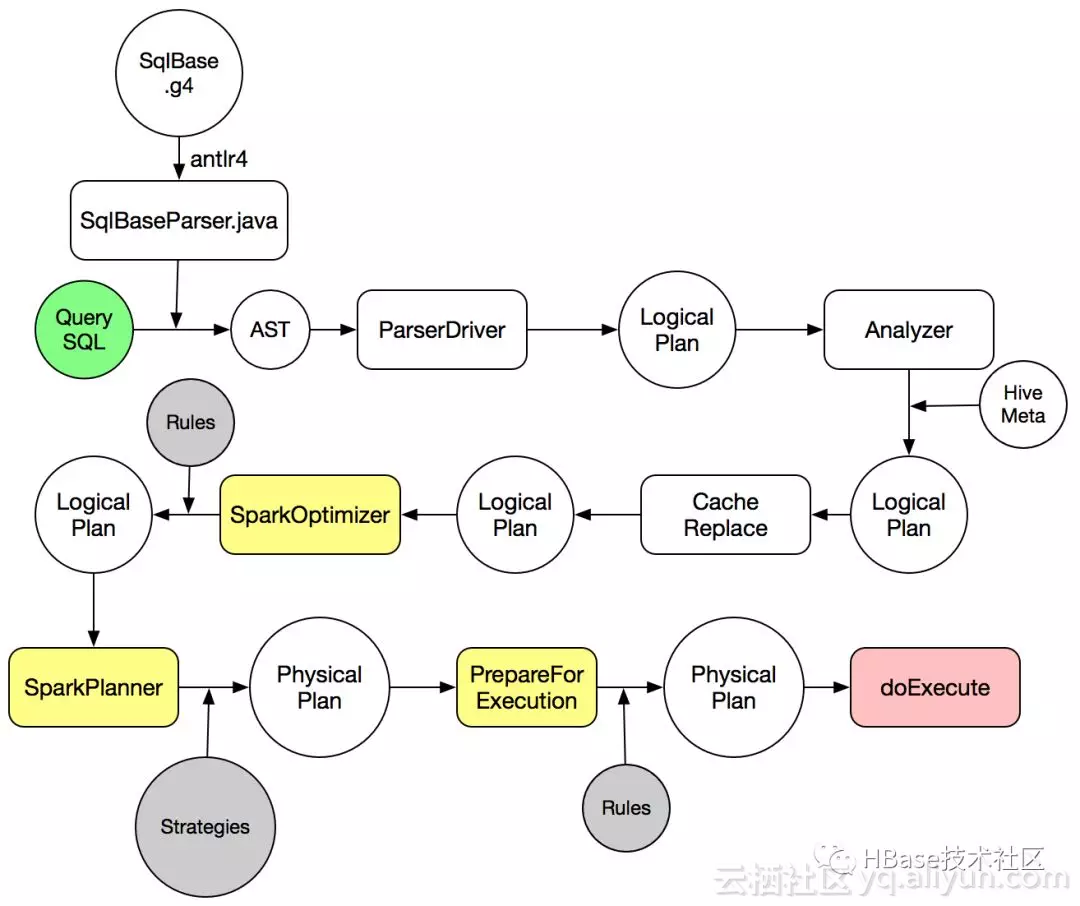
1.SqlParser将SQL语句解析成一个逻辑执行计划(未解析)

















 1356
1356

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









