



 本文详细介绍了Hadoop的基本架构,包括其核心组件HDFS和MapReduce的工作原理。HDFS由NameNode管理和DataNode存储数据;MapReduce通过JobTracker协调任务,TaskTracker执行任务,实现分布式计算。
本文详细介绍了Hadoop的基本架构,包括其核心组件HDFS和MapReduce的工作原理。HDFS由NameNode管理和DataNode存储数据;MapReduce通过JobTracker协调任务,TaskTracker执行任务,实现分布式计算。

##7.hadoop
-
基本架构
- hdfs:分布式文件系统
- map-reduce:分布式计算框架
-
hdfs
- NameNode:一个,系统总管,管理hdfs目录树
- DateNode:一个节点,实际数据存储
-
MapReduce框架
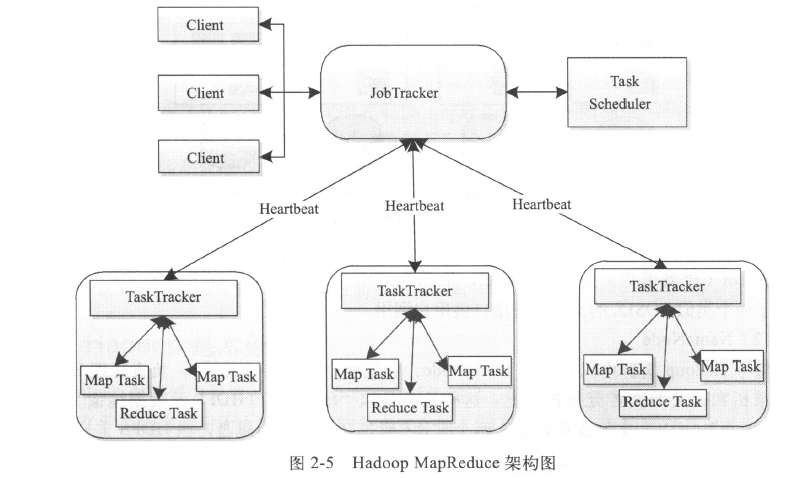
- JobTracker
- TaskTracker
-
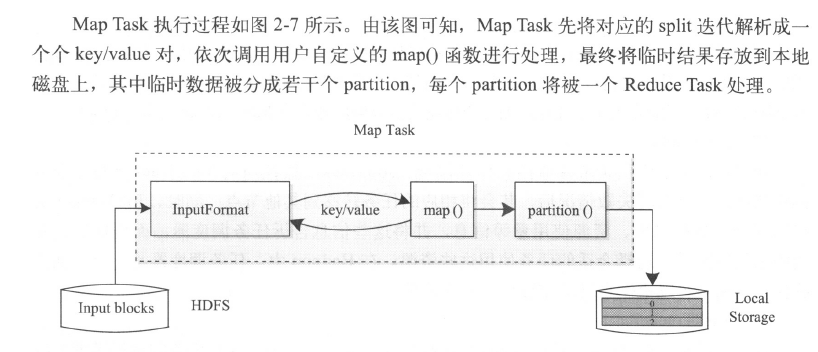
map过程
-
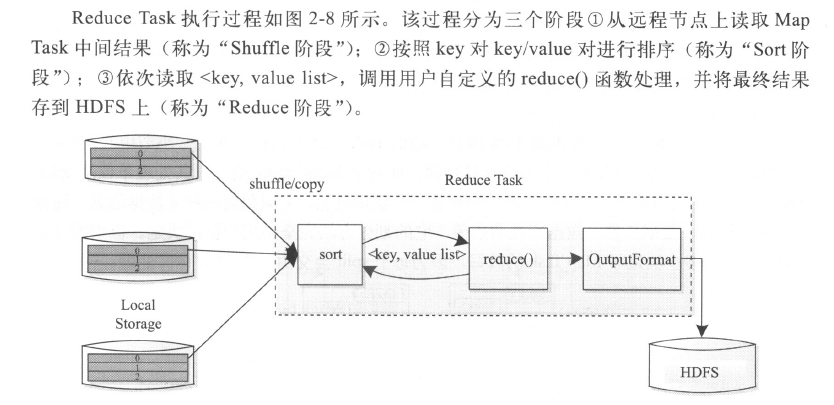
reduce过程
-
Partitioner
-
作用是对Mapper产生的中间结果进行分片,将同一分组的数据交给同一个reducer处理
-
默认hash分片
(key.hashcode & Integer.MAX_VALUE) % reduce_num
-
-
任务选择策略: map task最重要的策略是:数据本地性
-
任务调度器:FIFO
-
task运行过程
- map输出分布式排序:先由各个map task对输出进行局部排序,然后reduce task进行全局排序
- reduce

















 934
934

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









