



 本文深入探讨了Java中的核心技术,包括但不限于栈和堆的区别、基于注解的切面实现、对象关系映射集成模块、反射机制、ACID特性、BS与CS架构的区别、Cookie与Session的区别、fail-fast与fail-safe机制的区别、GET与POST请求的区别以及Interface与抽象类的区别。
本文深入探讨了Java中的核心技术,包括但不限于栈和堆的区别、基于注解的切面实现、对象关系映射集成模块、反射机制、ACID特性、BS与CS架构的区别、Cookie与Session的区别、fail-fast与fail-safe机制的区别、GET与POST请求的区别以及Interface与抽象类的区别。

Java日常记录 1-10
1、操作系统中 heap 和 stack 的区别
堆栈的概念:
堆,队列优先,先进先出(FIFO—first in first out)。栈,先进后出(FILO—First-In/Last-Out)。
堆和栈的区别:
一、堆栈空间分配区别:
1、栈(操作系统):由操作系统自动分配释放 ,存放函数的参数值,局部变量的值等。其操作方式类似于数据结构中的栈;
2、堆(操作系统): 一般由程序员分配释放, 若程序员不释放,程序结束时可能由OS回收,分配方式倒是类似于链表。
二、堆栈缓存方式区别:
1、栈使用的是一级缓存, 他们通常都是被调用时处于存储空间中,调用完毕立即释放;
2、堆是存放在二级缓存中,生命周期由虚拟机的垃圾回收算法来决定(并不是一旦成为孤儿对象就能被回收)。所以调用这些对象的速度要相对来得低一些。
三、堆栈数据结构区别:
堆(数据结构):堆可以被看成是一棵树,如:堆排序;
栈(数据结构):一种先进后出的数据结构。
Java中栈和堆的区别:
栈(stack)与堆(heap)都是Java用来在Ram中存放数据的地方。与C++不同,Java自动管理栈和堆,程序员不能直接地设置栈或堆。
在函数中定义的一些基本类型的变量和对象的引用变量都在函数的栈内存中分配。当在一段代码块定义一个变量时,Java就在栈中为这个变量分配内存空间,当超过变量的作用域后,Java会自动释放掉为该变量所分配的内存空间,该内存空间可以立即被另作他用。
堆内存用来存放由new创建的对象和数组,在堆中分配的内存,由Java虚拟机的自动垃圾回收器来管理。在堆中产生了一个数组或对象后,还可以在栈中定义一个特殊的变量,让栈中这个变量的取值等于数组或对象在堆内存中的首地址,栈中的这个变量就成了数组或对象的引用变量。引用变量就相当于是为数组或对象起的一个名称,以后就可以在程序中使用栈中的引用变量来访问堆中的数组或对象。
Java中变量在内存中的分配:
1、类变量(static修饰的变量):在程序加载时系统就为它在堆中开辟了内存,堆中的内存地址存放于栈以便于高速访问。静态变量的生命周期–一直持续到整个”系统”关闭。
2、实例变量:当你使用java关键字new的时候,系统在堆中开辟并不一定是连续的空间分配给变量(比如说类实例),然后根据零散的堆内存地址,通过哈希算法换算为一长串数字以表征这个变量在堆中的”物理位置”。 实例变量的生命周期–当实例变量的引用丢失后,将被GC(垃圾回收器)列入可回收“名单”中,但并不是马上就释放堆中内存。
3、局部变量:局部变量,由声明在某方法,或某代码段里(比如for循环),执行到它的时候在栈中开辟内存,当局部变量一但脱离作用域,内存立即释放。
2、什么是基于注解的切面实现
简单的说:这种在运行时,动态地将代码切入到类的指定方法、指定位置上的编程思想就是面向切面的编程
面向切面编程(AOP是Aspect Oriented Program的首字母缩写) ,我们知道,面向对象的特点是继承、多态和封装。而封装就要求将功能分散到不同的对象中去,这在软件设计中往往称为职责分配。实际上也就是说,让不同的类设计不同的方法。这样代码就分散到一个个的类中去了。这样做的好处是降低了代码的复杂程度,使类可重用。
但是人们也发现,在分散代码的同时,也增加了代码的重复性。什么意思呢?比如说,我们在两个类中,可能都需要在每个方法中做日志。按面向对象的设计方法,我们就必须在两个类的方法中都加入日志的内容。也许他们是完全相同的,但就是因为面向对象的设计让类与类之间无法联系,而不能将这些重复的代码统一起来。
也许有人会说,那好办啊,我们可以将这段代码写在一个独立的类独立的方法里,然后再在这两个类中调用。但是,这样一来,这两个类跟我们上面提到的独立的类就有耦合了,它的改变会影响这两个类。那么,有没有什么办法,能让我们在需要的时候,随意地加入代码呢?这种在运行时,动态地将代码切入到类的指定方法、指定位置上的编程思想就是面向切面的编程。
一般而言,我们管切入到指定类指定方法的代码片段称为切面,而切入到哪些类、哪些方法则叫切入点。有了AOP,我们就可以把几个类共有的代码,抽取到一个切片中,等到需要时再切入对象中去,从而改变其原有的行为。
这样看来,AOP其实只是OOP的补充而已。OOP从横向上区分出一个个的类来,而AOP则从纵向上向对象中加入特定的代码。有了AOP,OOP变得立体了。如果加上时间维度,AOP使OOP由原来的二维变为三维了,由平面变成立体了。从技术上来说,AOP基本上是通过代理机制实现的。
AOP在编程历史上可以说是里程碑式的,对OOP编程是一种十分有益的补充。
增强(advice,另译为通知,但《3.x》作者不赞成):在特定连接点执行的动作。
切点(pointcut):一组连接点的总称,用于指定某个增强应该在何时被调用。
连接点(join point):在应用执行过程中能够插入切面的一个点
切面(aspect):通知(即增强)和切点的结合。
3、什么是 对象/关系 映射集成模块
对象关系映射(Object Relational Mapping,简称ORM)是通过使用描述对象和数据库之间映射的元数据,将面向对象语言程序中的对象自动持久化到关系数据库中。本质上就是将数据从一种形式转换到另外一种形式。
4、什么是 Java 的反射机制
Java反射机制是在运行状态中,对于任意一个类,都能够知道这个类的所有属性和方法;对于任意一个对象,都能够调用它的任意一个方法和属性;这种动态获取的信息以及动态调用对象的方法的功能称为Java语言的反射机制。
1、关于Class
1、Class是一个类,一个描述类的类(也就是描述类本身),封装了描述方法的Method,描述字段的Filed,描述构造器的Constructor等属性
2、对象照镜子后(反射)可以得到的信息:某个类的数据成员名、方法和构造器、某个类到底实现了哪些接口。
3、对于每个类而言,JRE 都为其保留一个不变的 Class 类型的对象。
一个 Class 对象包含了特定某个类的有关信息。
4、Class 对象只能由系统建立对象
5、一个类在 JVM 中只会有一个Class实例
5、什么是 ACID
数据库事务概念
什么是数据库事务?
事务(transaction)是由指逻辑上对数据的的一组操作, 这组操作要么一次全部成功,如果这组操作全部失败,是不可分割的一个工作单位。
数据库事务的四个基本性质(ACID)
1. 原子性(Atomicity)
事务的原子性是指事务是一个不可分割的工作单位,这组操作要么全部发生,否则全部不发生。
2. 一致性(Consistency)
在事务开始以前,被操作的数据的完整性处于一致性的状态,事务结束后,被操作的数据的完整性也必须处于一致性状态。
拿银行转账来说,一致性要求事务的执行不应改变A、B 两个账户的金额总和。如果没有这种一致性要求,转账过程中就会发生钱无中生有,或者不翼而飞的现象。事务应该把数据库从一个一致性状态转换到另外一个一致性状态。
3. 隔离性(Isolation)
事务隔离性要求系统必须保证事务不受其他并发执行的事务的影响,也即要达到这样一种效果:对于任何一对事务T1 和 T2,在事务 T1 看来,T2 要么在 T1 开始之前已经结束,要么在 T1 完成之后才开始执行。这样,每个事务都感觉不到系统中有其他事务在并发地执行。
4. 持久性(Durability)
一个事务一旦成功提交,它对数据库的改变必须是永久的,即便是数据库发生故障也应该不回对其产生任何影响
http://blog.youkuaiyun.com/helloboat/article/details/51245043
需要说明的是,事务隔离级别和数据访问的并发性是对立的,事务隔离级别越高并发性就越差。所以要根据具体的应用来确定合适的事务隔离级别,这个地方没有万能的原则。
6、BS与CS的联系与区别
C/S是Client/Server的缩写。服务器通常采用高性能的PC、工作站或小型机,并采用大型数据库系统,如Oracle、Sybase、Informix或 SQL Server。客户端需要安装专用的客户端软件。
B/S是Brower/Server的缩写,客户机上只要安装一个浏览器(Browser),如Netscape Navigator或Internet Explorer,服务器安装Oracle、Sybase、Informix或 SQL Server等数据库。在这种结构下,用户界面完全通过WWW浏览器实现,一部分事务逻辑在前端实现,但是主要事务逻辑在服务器端实现。浏览器通过Web Server 同数据库进行数据交互。
C/S 与 B/S 区别:
1.硬件环境不同:
C/S 一般建立在专用的网络上, 小范围里的网络环境, 局域网之间再通过专门服务器提供连接和数据交换服务.
B/S 建立在广域网之上的, 不必是专门的网络硬件环境,例与电话上网, 租用设备. 信息自己管理. 有比C/S更强的适应范围, 一般只要有操作系统和浏览器就行
2.对安全要求不同
C/S 一般面向相对固定的用户群, 对信息安全的控制能力很强. 一般高度机密的信息系统采用C/S 结构适宜. 可以通过B/S发布部分可公开信息.
B/S 建立在广域网之上, 对安全的控制能力相对弱, 可能面向不可知的用户。
3.对程序架构不同
C/S 程序可以更加注重流程, 可以对权限多层次校验, 对系统运行速度可以较少考虑.
B/S 对安全以及访问速度的多重的考虑, 建立在需要更加优化的基础之上. 比C/S有更高的要求 B/S结构的程序架构是发展的趋势, 从MS的.Net系列的BizTalk 2000 Exchange 2000等, 全面支持网络的构件搭建的系统. SUN 和IBM推的JavaBean 构件技术等,使 B/S更加成熟.
4.软件重用不同
C/S 程序可以不可避免的整体性考虑, 构件的重用性不如在B/S要求下的构件的重用性好.
B/S 对的多重结构,要求构件相对独立的功能. 能够相对较好的重用.就入买来的餐桌可以再利用,而不是做在墙上的石头桌子
5.系统维护不同
C/S 程序由于整体性, 必须整体考察, 处理出现的问题以及系统升级. 升级难. 可能是再做一个全新的系统
B/S 构件组成,方面构件个别的更换,实现系统的无缝升级. 系统维护开销减到最小.用户从网上自己下载安装就可以实现升级.
6.处理问题不同
C/S 程序可以处理用户面固定, 并且在相同区域, 安全要求高需求, 与操作系统相关. 应该都是相同的系统
B/S 建立在广域网上, 面向不同的用户群, 分散地域, 这是C/S无法作到的. 与操作系统平台关系最小.
7.用户接口不同
C/S 多是建立的Window平台上,表现方法有限,对程序员普遍要求较高
B/S 建立在浏览器上, 有更加丰富和生动的表现方式与用户交流. 并且大部分难度减低,减低开发成本.
8.信息流不同
C/S 程序一般是典型的中央集权的机械式处理, 交互性相对低
B/S 信息流向可变化, B-B B-C B-G等信息、流向的变化, 更像交易中心。
7、Cookie 和 Session的区别
1. 由于HTTP协议是无状态的协议,所以服务端需要记录用户的状态时,就需要用某种机制来识具体的用户,这个机制就是Session.典型的场景比如购物车,当你点击下单按钮时,由于HTTP协议无状态,所以并不知道是哪个用户操作的,所以服务端要为特定的用户创建了特定的Session,用用于标识这个用户,并且跟踪用户,这样才知道购物车里面有几本书。这个Session是保存在服务端的,有一个唯一标识。在服务端保存Session的方法很多,内存、数据库、文件都有。集群的时候也要考虑Session的转移,在大型的网站,一般会有专门的Session服务器集群,用来保存用户会话,这个时候 Session 信息都是放在内存的,使用一些缓存服务比如Memcached之类的来放 Session。
2. 思考一下服务端如何识别特定的客户?这个时候Cookie就登场了。每次HTTP请求的时候,客户端都会发送相应的Cookie信息到服务端。实际上大多数的应用都是用 Cookie 来实现Session跟踪的,第一次创建Session的时候,服务端会在HTTP协议中告诉客户端,需要在 Cookie 里面记录一个Session ID,以后每次请求把这个会话ID发送到服务器,我就知道你是谁了。有人问,如果客户端的浏览器禁用了 Cookie 怎么办?一般这种情况下,会使用一种叫做URL重写的技术来进行会话跟踪,即每次HTTP交互,URL后面都会被附加上一个诸如 sid=xxxxx 这样的参数,服务端据此来识别用户。
3. Cookie其实还可以用在一些方便用户的场景下,设想你某次登陆过一个网站,下次登录的时候不想再次输入账号了,怎么办?这个信息可以写到Cookie里面,访问网站的时候,网站页面的脚本可以读取这个信息,就自动帮你把用户名给填了,能够方便一下用户。这也是Cookie名称的由来,给用户的一点甜头。
所以,总结一下:
Session是在服务端保存的一个数据结构,用来跟踪用户的状态,这个数据可以保存在集群、数据库、文件中;
Cookie是客户端保存用户信息的一种机制,用来记录用户的一些信息,也是实现Session的一种方式。
附:无状态协议
- 协议对于事务处理没有记忆能力
- 对同一个url请求没有上下文关系
- 每次的请求都是独立的,它的执行情况和结果与前面的请求和之后的请求是无直接关系的,它不会受前面的请求应答情况直接影响,也不会直接影响后面的请求应答情况
- 服务器中没有保存客户端的状态,客户端必须每次带上自己的状态去请求服务器
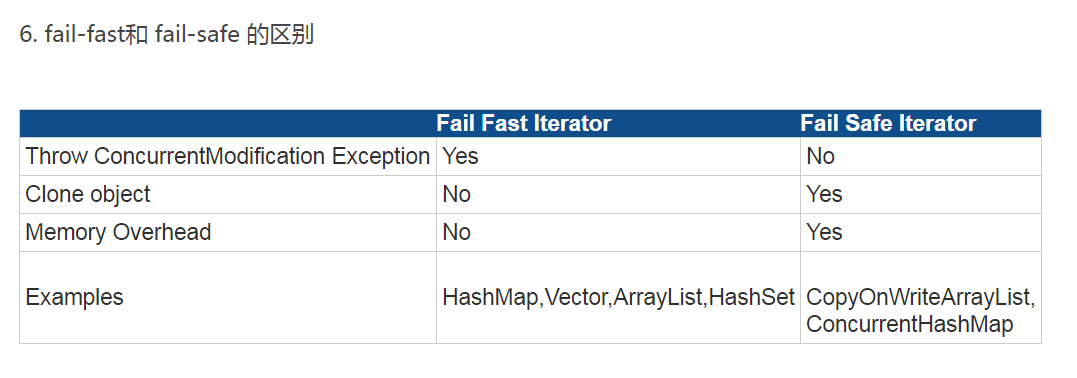
8、fail-fast 与 fail-safe 机制有什么区别
1.什么是同步修改?
当一个或多个线程正在遍历一个集合Collection,此时另一个线程修改了这个集合的内容(添加,删除或者修改)。这就是并发修改
2.什么是 fail-fast 机制?
fail-fast机制在遍历一个集合时,当集合结构被修改,会抛出Concurrent Modification Exception。
fail-fast会在以下两种情况下抛出ConcurrentModificationException
(1)单线程环境
集合被创建后,在遍历它的过程中修改了结构。
注意 remove()方法会让expectModcount和modcount 相等,所以是不会抛出这个异常。
(2)多线程环境
当一个线程在遍历这个集合,而另一个线程对这个集合的结构进行了修改。
. fail-safe机制
fail-safe任何对集合结构的修改都会在一个复制的集合上进行修改,因此不会抛出ConcurrentModificationException
fail-safe机制有两个问题
(1)需要复制集合,产生大量的无效对象,开销大
(2)无法保证读取的数据是目前原始数据结构中的数据。
9、get 和 post请求的区别
http://blog.youkuaiyun.com/wswit/article/details/50776060
10、Interface 与 abstract 类的区别
1.抽象类和接口都不呗实例化,如果要实例化,则要涉及到多台.
2、抽象类要被子类继承,接口要被子类实现。
3、接口里面只能对方法进行声明,抽象类既可以对方法进行声明也可以对方法进行实现。
4、抽象类里面的抽象方法必须全部被子类实现,如果子类不能全部实现,那么子类必须也是抽象类。接口里面的方法也必须全部被子类实现,如果子类不能实现那么子类必须是抽象类。
5、接口里面的方法只能声明,不能有具体的实现。这说明接口是设计的结果,抽象类是重构的结果。
6、抽象类里面可以没有抽象方法。
7、如果一个类里面有抽象方法,那么这个类一定是抽象类。
8、抽象类中的方法都要被实现,所以抽象方法不能是静态的static,也不能是私有的private。
9、接口(类)可以继承接口,甚至可以继承多个接口。但是类只能继承一个类。
10、抽象级别(从高到低):接口>抽象类>实现类。
11、抽象类主要是用来抽象类别,接口主要是用来抽象方法功能。当你关注事物的本质的时候,请用抽象类;当你关注一种操作的时候,用接口。
12、抽象类的功能应该要远多于接口,但是定义抽象类的代价较高。因为高级语言一个类只能继承一个父类,即你在设计这个类的时候必须要抽象出所有这个类的子类所具有的共同属性和方法;但是类(接口)却可以继承多个接口,因此每个接口你只需要将特定的动作方法抽象到这个接口即可。也就是说,接口的设计具有更大的可扩展性,而抽象类的设计必须十分谨慎。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









