



 本文介绍了一种能够准确解析网页内容的技术,包括标题、时间和标签等关键信息,并且能够有效去除广告干扰。通过提供的测试地址,可以体验其强大的解析能力。
本文介绍了一种能够准确解析网页内容的技术,包括标题、时间和标签等关键信息,并且能够有效去除广告干扰。通过提供的测试地址,可以体验其强大的解析能力。

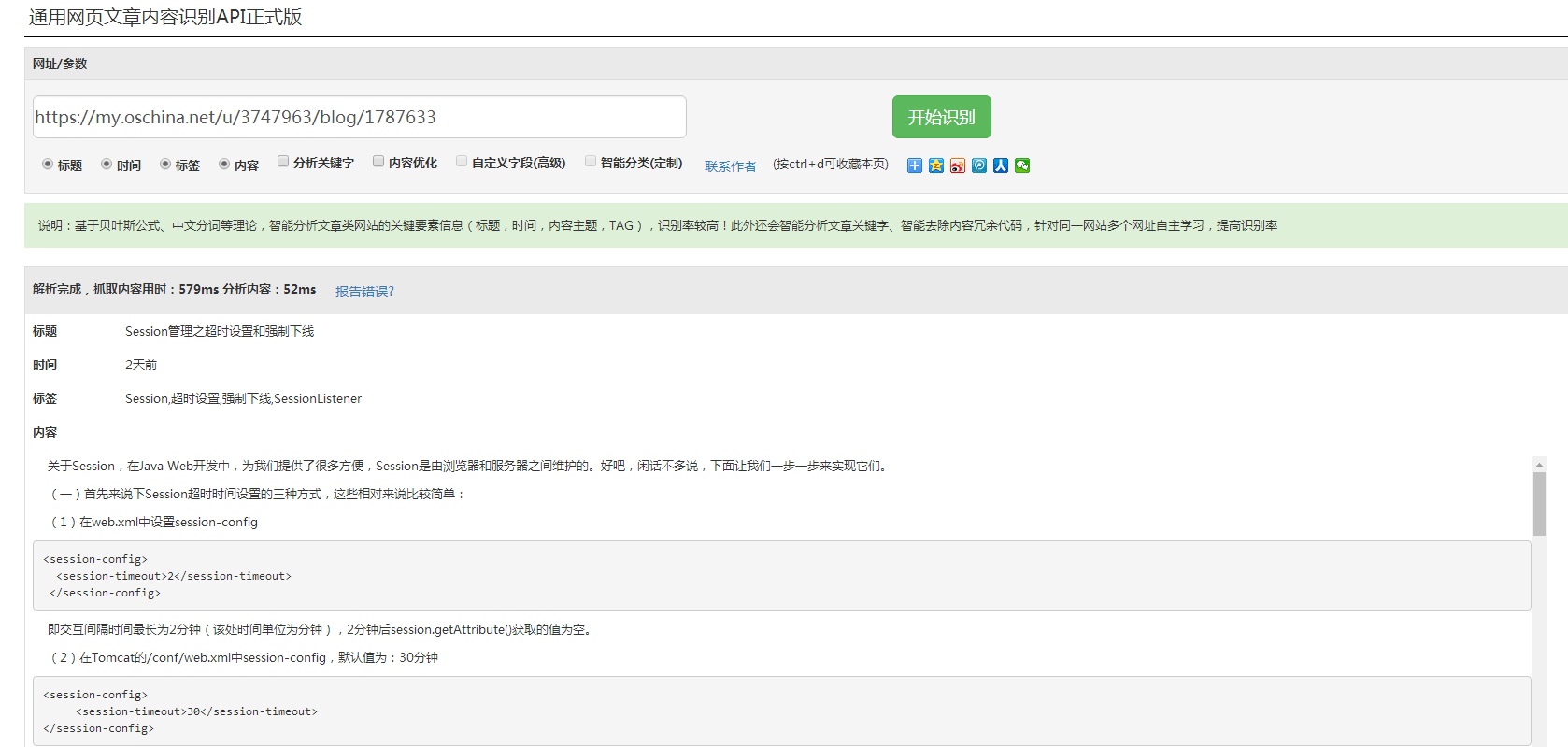
先上一张图吧,接口识别我们开源中国的链接(识别的我们今日的每日一搏 https://my.oschina.net/u/3747963/blog/1787633)
识别的一篇网络文章(原文地址: http://www.nowamagic.net/librarys/veda/detail/2048 )
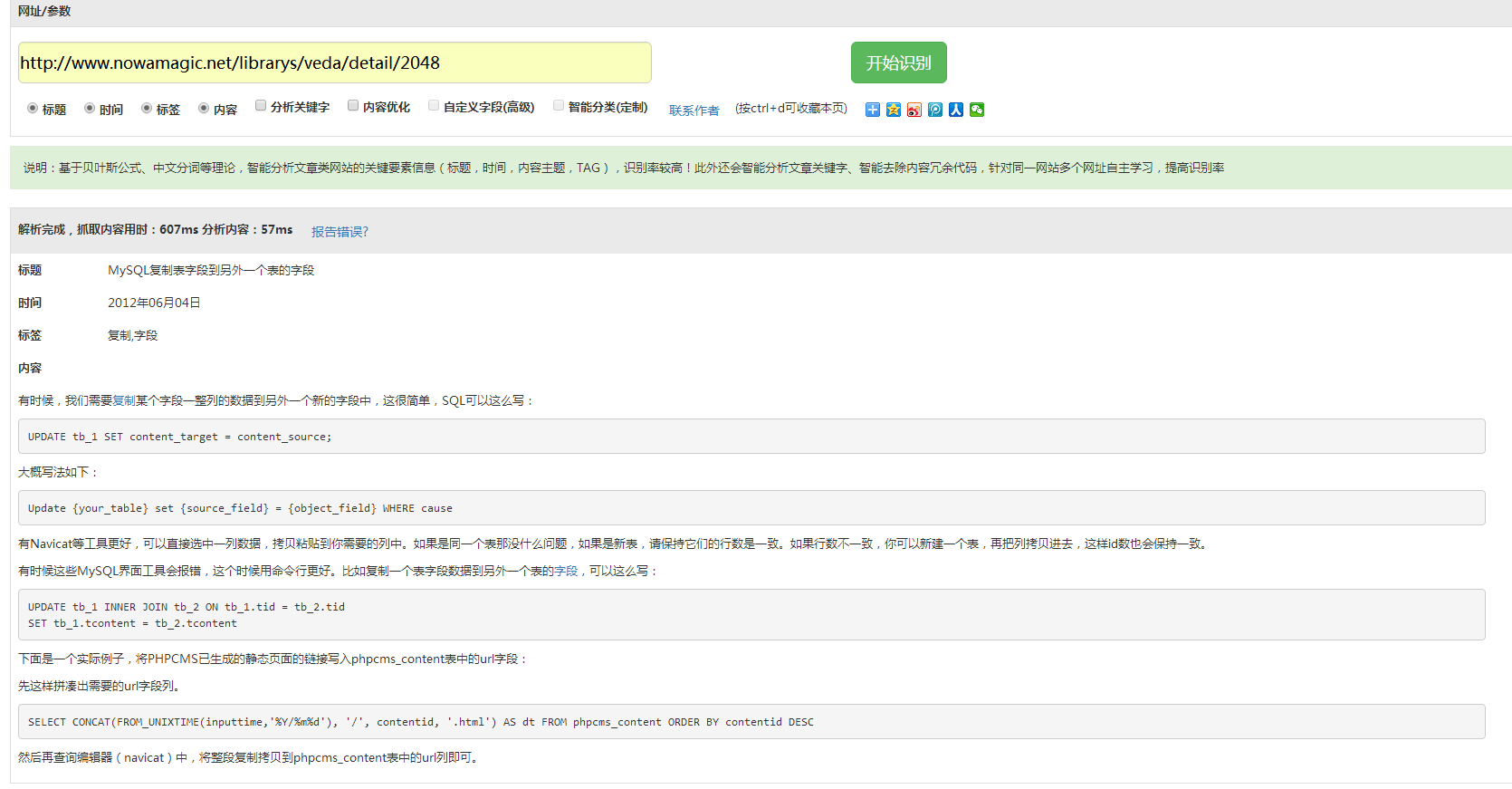
能准确的分析页面标题,时间,TAG,还有最重要的是内容,就连内容里的广告也能识别并且去掉,是不是还可以。
测试地址: http://www.qlshou.com/apidemo/pageparse
先上一张图吧,接口识别我们开源中国的链接(识别的我们今日的每日一搏 https://my.oschina.net/u/3747963/blog/1787633)
识别的一篇网络文章(原文地址: http://www.nowamagic.net/librarys/veda/detail/2048 )
能准确的分析页面标题,时间,TAG,还有最重要的是内容,就连内容里的广告也能识别并且去掉,是不是还可以。
测试地址: http://www.qlshou.com/apidemo/pageparse
转载于:https://my.oschina.net/os2015/blog/1788257
 330
330

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言


























