



 本文详细介绍SQL的基本查询语句,包括单表查询、多表连接查询、子查询、合并查询等多种查询方式,并涵盖数据的插入、更新及删除操作。
本文详细介绍SQL的基本查询语句,包括单表查询、多表连接查询、子查询、合并查询等多种查询方式,并涵盖数据的插入、更新及删除操作。
一、查询数据
1、基本查询语句
(1)查询多个字段
SELECT userid,orderid from sales; #查询userid,orderid字段
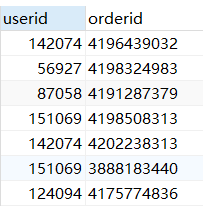
(2)查询所有字段
SELECT * from sales;
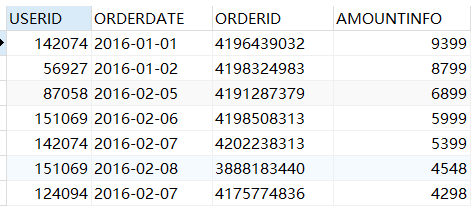
(3)查询指定记录
SELECT * #要显示的字段 from sales WHERE userid=142074; #查询条件

带between and的范围查询:
SELECT userid from sales WHERE AMOUNTINFO BETWEEN 8000 and 10000;

带in的关键字查询:
SELECT * from sales WHERE userid in(56927,124094);

带like的字符匹配查询:
SELECT * from sales WHERE userid LIKE'1%4';
查询空值:
SELECT * from sales WHERE userid is NULL;
![]()
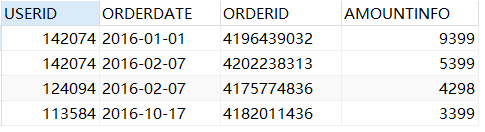
带and的多条件查询:
SELECT * from sales WHERE userid=151069 and AMOUNTINFO>5000;

带or的多条件查询:
SELECT * from sales WHERE userid=151069 or userid=56927;

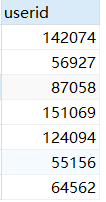
(4)查询不重复的结果:selec distinct
SELECT DISTINCT userid from sales;
(5)对查询结果排序:order by
SELECT * from sales order by userid; #单列排序
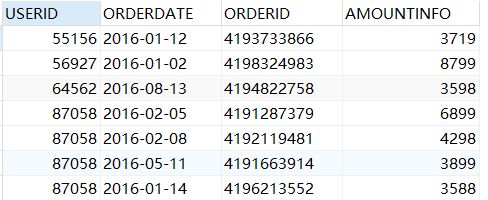
SELECT * from sales order by userid,AMOUNTINFO; #多列排序
排序的第一列要有相同的值,才会对第二列进行排序,如果第一列数据中的值都是唯一的,将不再对第二列进行排序。
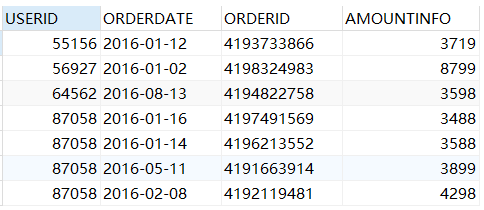
SELECT * from sales order by userid,AMOUNTINFO DESC; #降序排列,默认是升序ASC
DESC关键字只对其前面的列进行降序排序,所以这里只对AMOUNTINFO进行降序,userid仍是升序。
(6)分组查询: group by
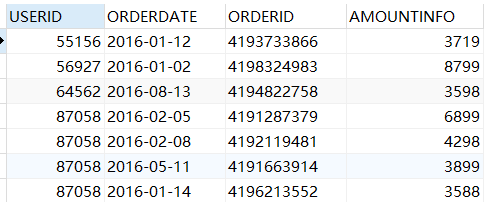
SELECT userid, count(*) from sales GROUP BY userid;
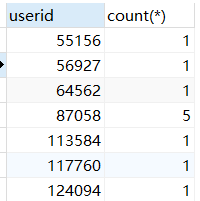
SELECT userid ,GROUP_CONCAT(AMOUNTINFO) #使用GROUP_CONCAT函数,将每个分组中各字段的值显示出来 from sales GROUP BY userid;
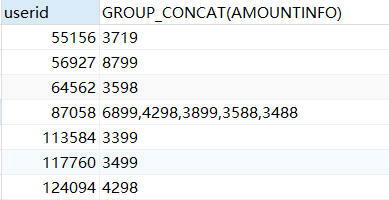
使用having过滤分组
SELECT userid ,GROUP_CONCAT(AMOUNTINFO) from sales GROUP BY userid HAVING COUNT(AMOUNTINFO)>1; #用groupby对userid分组,每组中AMOUNTINFO数量大于1的才会被显示

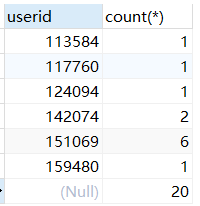
在group by 字句中使用with rollup
SELECT userid,count(*) from sales GROUP BY userid WITH ROLLUP; #在最后增加一条记录,显示查询出的数据总和,即统计记录数量
多字段分组:
分层层次从左至右,先按照第一个字段分组,然后在第一个字段值相同的记录中,根据第二个字段的值进行分组...依次类推。
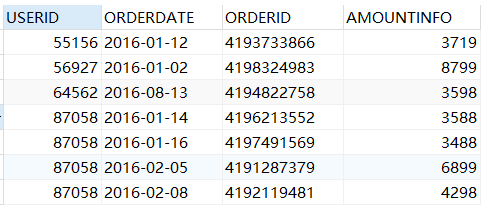
SELECT * from sales GROUP BY userid,ORDERDATE;
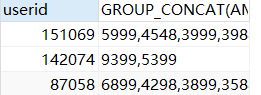
group by 和order by:
SELECT userid ,GROUP_CONCAT(AMOUNTINFO) from sales GROUP BY userid HAVING COUNT(AMOUNTINFO)>1 ORDER BY userid DESC;
(7)使用limit限制查询结果数量
SELECT * from sales LIMIT 3,4; #第一个数字四位置偏移量,偏移3个位置,即从第4行开始查找,返回4行记录
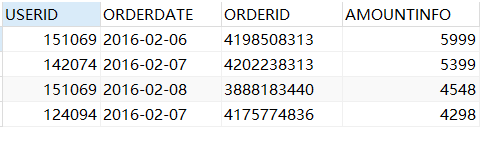
2、使用集合函数查询
avg():返回某列的平均值
count():返回某列的行数,count(*),计算总表的行数,不论是否有空值。count(字段名),计算指定字段的行数,计算时忽略空值。
max():返回某列的最大值
min():返回某列的最小值
sum():返回某列值的和,忽略空值
SELECT count(*) as total from sales;
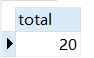
SELECT userid ,max(AMOUNTINFO) #分组后的最大值 from sales GROUP BY userid ;
3、连接查询
(1)内连接( inner join)查询:
列出表中与连接条件相匹配的数据,组成新的数据。
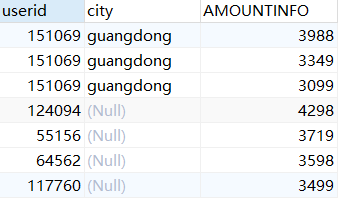
SELECT sales.userid,city,AMOUNTINFO from sales,city WHERE sales.userid=city.userid;
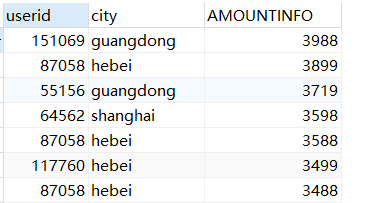
(2)外连接查询
左连接(left join):返回左表中的所有记录和右表中连接字段相等的记录
右连接(right join):返回右表中的所有记录和左表中连接字段相等的记录
SELECT sales.userid,city,AMOUNTINFO from sales LEFT OUTER JOIN city2 ON sales.userid=city2.userid;
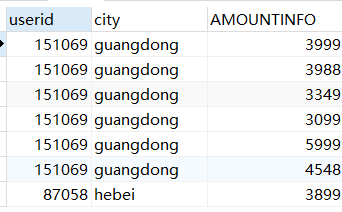
(3)复合条件连接查询
SELECT sales.userid,city,AMOUNTINFO from sales INNER JOIN city2 ON sales.userid=city2.userid AND sales.userid in (151069,87058) ORDER BY userid DESC;
4、子查询
(1)带any、some的子查询
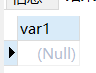
any和some关键字是同义词,表示满足其中任一条件,它们允许创建一个表达式对子查询的返回值列表进行比较。
CREATE TABLE num1 (var1 INT); CREATE TABLE num2 (var2 INT); INSERT INTO num1 VALUES(7),(9),(5); INSERT INTO num2 VALUES(5),(2),(6); SELECT var1 FROM num1 where var1>ANY(SELECT var2 FROM num2); #只要num1表中的数大于num2表中的任意一个数,就显示。7大于5,2,6,故7显示,9大于5,2,6,故9显示,5大于2,故5显示

(2)带all的子查询
all关键字表示要同时满足所有查询条件。
SELECT var1 FROM num1 where var1>ALL(SELECT var2 FROM num2); #num1表中的数要大与num2表中的所有数,才显示。

(3)带exists、not exists的子查询
exists关键字后面的参数是一个任意的子查询,系统对子查询进行运行并判断它是否有返回行,如果有exists返回true,此时外层查询执行;若返回false,外层不执行查询。not exists作用与exists相反。
SELECT var1 FROM num1 where EXISTS (SELECT var2 FROM num2 where var2>9); #SELECT var2 FROM num2 where var2>9 没有返回行,故外层查询不执行
(4)带in,not in 的子查询
in关键字进行子查询时,内层查询语句返回一个数列,这个数列里的值将提供给外层查询语句进行比较运算。not in与in作用相反。
SELECT var1 FROM num1 where var1 in (SELECT var2 FROM num2 ); #(SELECT var2 FROM num2 ) 返回一个数列 5,2,6,num1中的值,只有5在这数列中,故显示5

(5)带比较运算符的子查询
比较运算符:<,<=,=,>=,!=
SELECT var1 FROM num1 where var1 > (SELECT var2 FROM num2 where var2 >5); #(SELECT var2 FROM num2 where var2 >5 返回6,var1中大于6的值为7、9

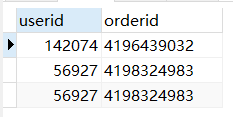
5、合并查询结果
使用关键字union,可以将多个查询结果组个成一个查询结果集,合并时对应的列数和数据类型要相同。
union:合并时删除重复的,返回的行是唯一的
union all:合并时不删除重复的
SELECT userid ,orderid from sales where AMOUNTINFO >8000 union ALL #合并两条查询结果,不删除重复行 SELECT userid ,orderid from sales where userid=56927;
6、为表格、字段取别名
(1)为表取别名
当表名很长或执行一些特殊查询时,为方便操作,可以为表指定别名,用这个名称替代原来的名称。可同时为多个表取别名,取别名的位置可以在select、where、order by等句子中。
SELECT * from sales as ss #表sales 别名ss where ss.userid=56927;

(2)为字段取别名
在一些情况下,显示的列名很长或不够直观,此时可以为该列指定列名。
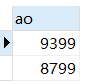
SELECT amountinfo as ao from sales where amountinfo >8000;
7、使用正则表达式查询
mysql中用regexp关键字指定正则表达式的字符匹配模式。
CREATE TABLE test (var1 VARCHAR(22)); INSERT INTO test VALUES('asd'),('aaafrgggg'),('acfmk'); SELECT * from test where var1 REGEXP 'a.d' ; SELECT * from test where var1 REGEXP '^a' ; SELECT * from test where var1 REGEXP 'k$' ; SELECT * from test where var1 REGEXP '^ac+' ; SELECT * from test where var1 REGEXP '[fk]' ; SELECT * from test where var1 REGEXP '[^asd]' ;
二、插入、更新与删除数据
1、插入数据
(1)、为表的所有字段插入数据
CREATE TABLE test2 (id int , name VARCHAR(20), age int ); INSERT INTO test2 VALUES(1,'aa',12),(2,'bb',13); #值的顺序要与建表时的列的顺序一致 INSERT INTO test2(name,id,age) VALUES('cc',3,14); #值的顺序只要与test2(name,id,age)对应即可,可以与建表时列的顺序不一样 SELECT * from test2;

(2)、为表的指定字段插入数据
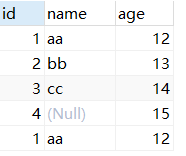
INSERT INTO test2(id,age) VALUES(4,15); SELECT * FROM test2;

(3)、将查询结果插入到表中
INSERT INTO test2 SELECT * from test2 where id=1; #将查询的结果添加到表test2中 select * FROM test2;
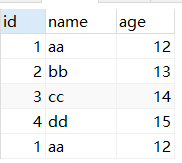
2、更新数据
UPDATE test2 SET name='dd' where id=4;
select * FROM test2;
3、删除数据
DELETE from test2 where id=1; select * FROM test2;



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









